Command Palette
Search for a command to run...
Process Rewards with Learned Reliability
Process Rewards with Learned Reliability
Jinyuan Li Langlin Huang Chengsong Huang Shaoyang Xu Donghong Cai Yuyi Yang Wenxuan Zhang Jiaxin Huang
Abstract
Process Reward Models (PRMs) provide step-level feedback for reasoning, but current PRMs usually output only a single reward score for each step. Downstream methods must therefore treat imperfect step-level reward predictions as reliable decision signals, with no indication of when these predictions should be trusted. We propose BetaPRM, a distributional PRM that predicts both a step-level success probability and the reliability of that prediction. Given step-success supervision from Monte Carlo continuations, BetaPRM learns a Beta belief that explains the observed number of successful continuations through a Beta-Binomial likelihood, rather than regressing to the finite-sample success ratio as a point target. This learned reliability signal indicates when a step reward should be trusted, enabling downstream applications to distinguish reliable rewards from uncertain ones. As one application, we introduce Adaptive Computation Allocation (ACA) for PRM-guided Best-of-N reasoning. ACA uses the learned reliability signal to stop when a high-reward solution is reliable and to spend additional computation on uncertain candidate prefixes. Experiments across four backbones and four reasoning benchmarks show that BetaPRM improves PRM-guided Best-of-N selection while preserving standard step-level error detection. Built on this signal, ACA improves the accuracy--token tradeoff over fixed-budget Best-of-16, reducing token usage by up to 33.57% while improving final-answer accuracy.
One-sentence Summary
The authors propose BETAPRM, a distributional Process Reward Model that predicts step-level success probability and reliability via a Beta belief framework trained on Monte Carlo continuations rather than regressing to finite-sample success ratios as point targets, enabling Adaptive Computation Allocation for Best-of-N reasoning to distinguish reliable rewards from uncertain ones and improving selection performance across four backbones and four reasoning benchmarks while preserving standard step-level error detection.
Introduction
Process Reward Models provide step-level feedback for reasoning tasks, serving as a critical interface for test-time scaling and policy optimization. However, existing models output only a single point estimate for each step, forcing downstream methods to treat imperfect predictions as reliable signals without quantifying uncertainty. Training supervision further complicates this by relying on noisy finite-sample estimates as fixed targets rather than accounting for sampling variance. To address these issues, the authors propose BETAPRM, a distributional reward model that predicts both a step-level success probability and the reliability of that estimate using a Beta-Binomial likelihood. This learned reliability signal enables Adaptive Computation Allocation, which dynamically adjusts inference budget based on confidence to improve accuracy while reducing token usage.
Dataset

Experiment

At each marker, the model scores the step using the normalized Yes probability over the reward tokens Yes and No. For the Standard PRM baseline, candidates are ranked by the average reward,
SPRM(y)=T1t=1∑Tμt.For BETAPRM, the paper additionally extract the concentration κt and compute the Beta standard deviation
σt=κt+1μt(1−μt).the paper rank candidates with the risk-budget selector used in the main experiments:
SRB(y)=T1t=1∑Tμt−λT1t=1∑T1[σt>τ].The penalty weight λ and uncertainty threshold τ are selected from the same small fixed grid for all reported BETAPRM runs: λ∈{0.2,0.5,0.7,1.0,1.5}, with τ set by the q-th percentile of step-level σt, q∈{0.7,0.8,0.9}.
- A.4 VisualProcessBench Evaluation Protocol
the paper evaluate step-level error detection on VisualProcessBench [63]. For each instance, the paper concatenate the question with the provided step-by-step rationale and insert a marker after every step, using the same input format as PRM training. The model produces one score at each marker, which is then converted into a binary prediction of whether the corresponding step is correct or erroneous. Neutral labels are ignored when computing metrics.
For the Standard PRM baseline, the step score is the normalized Yes probability μt. For BE-TAPRM, the paper use the same reward mean together with the learned concentration to compute σt=μt(1−μt)/(κt+1), and evaluate the risk-adjusted step score st=μt−λσt, with λ=0.5 This uses the reliability signal in the same direction as the downstream selection experiments: uncertain positive-looking steps are scored more conservatively.
Given a threshold τcls, steps with st≥τcls are classified as correct and those below the threshold are classified as erroneous. Following the benchmark protocol [63], the paper choose a single global threshold per model by sweeping τcls and maximizing the overall validation F1. the paper report the overall score and the per-source macro-F1 breakdown on VisualProcessBench.
- A.5 Adaptive Computation Allocation Details
ACA is evaluated under the same maximum Best-of-16 budget as the fixed-budget baseline. For each problem, ACA first samples n0=4 complete candidates from scratch. If the stopping criterion is not
satisfied, it allocates another batch of m=4 candidates, up to the maximum budget N=16. All new candidates are generated by InternVL2.5-8B with the same decoding parameters as the fixed-budget Best-of-16 baseline: temperature 0.7, top-p=0.9, top-k=30 and maximum new tokens 2048.
At each stage, candidates are scored by the linear risk-adjusted score used in the ACA stopping rule.
Slin(y)=T1t=1∑T(μt−λσt),with λ=0.5. The lower and upper confidence bounds use U(y)=T−1∑tσt with cstop=0.3 When ACA continues, it expands the highest-UCB non-winner competitor. For prefix repair, the paper use pbad=0.3 as the low-quality threshold and ccut=1.0 in the conservative step score μt−ccutσt.
For the main ACA results, final candidate selection uses the same risk-budget selector SRB as the Best-of-16 evaluation. For the ACA ablation in the table, all variants instead use the shared linear score Slin, with σt=0 for the reward-only Standard PRM baseline. This keeps the ablation focused on the source of uncertainty.
The the the table evaluates the proposed BETAPRM method as a solution selector for Best-of-N reasoning across four different vision-language model backbones and four math benchmarks. Results demonstrate that BETAPRM consistently achieves the highest final-answer accuracy in every configuration, outperforming both the standard Process Reward Model (PRM) baseline and the base model without training. BETAPRM consistently outperforms the Standard PRM baseline in final-answer accuracy across all evaluated model backbones and math reasoning benchmarks. The proposed method achieves the highest average improvement over the single-pass baseline compared to other training strategies like standard PRM. Incorporating learned uncertainty estimates allows BETAPRM to select better candidates than methods relying solely on average process rewards.
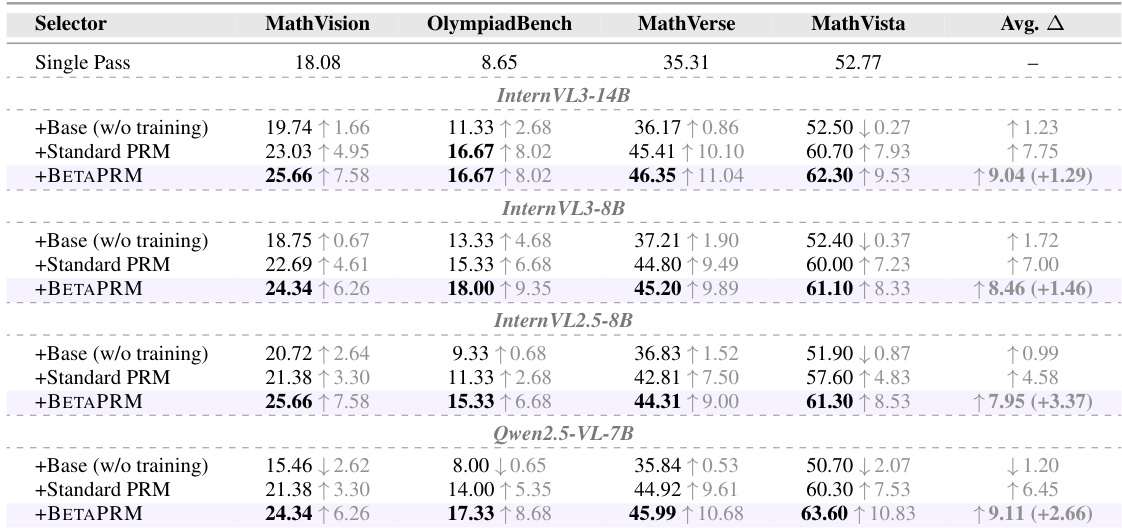
The authors evaluate the contribution of the auxiliary evidence regularizer by comparing the full BETAPRM model against a variant without it. The results demonstrate that the full model consistently achieves higher accuracy across all benchmarks. This finding suggests that the regularizer effectively calibrates the model's concentration estimates, leading to more reliable uncertainty signals for candidate selection. The full BETAPRM model outperforms the version without the regularizer on all benchmarks. Removing the regularizer results in a consistent decline in accuracy across the evaluated datasets. The auxiliary regularizer improves the calibration of concentration parameters used for reliability estimation.

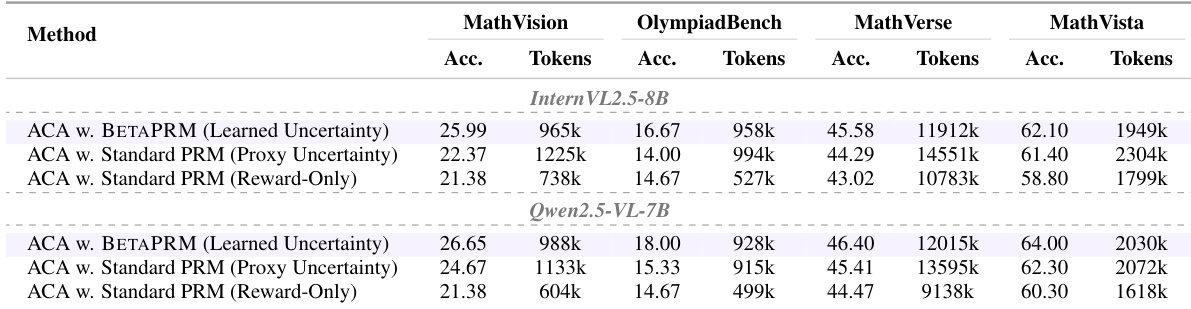
The experiment evaluates Adaptive Computation Allocation (ACA) strategies using different uncertainty sources across two model backbones. Results indicate that ACA utilizing BETAPRM with learned uncertainty consistently outperforms standard PRM baselines by achieving higher accuracy with lower token consumption. While the reward-only variant minimizes token usage, it sacrifices significant accuracy compared to the uncertainty-aware methods. ACA with BETAPRM (Learned Uncertainty) achieves the best balance of high accuracy and low token usage across all benchmarks and backbones. Standard PRM with proxy uncertainty consistently requires more tokens and yields lower accuracy compared to the learned uncertainty variant. The reward-only allocation strategy generates the fewest tokens but results in the lowest accuracy scores, demonstrating the value of explicit uncertainty estimation.
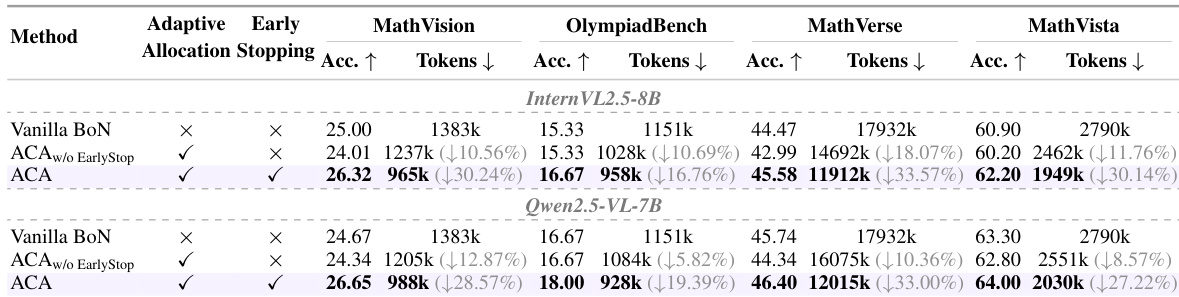
The authors evaluate Adaptive Computation Allocation (ACA) against a standard Best-of-N baseline to assess inference efficiency and accuracy. The results demonstrate that ACA, particularly when combined with early stopping, consistently achieves higher accuracy while significantly reducing the number of generated tokens across multiple benchmarks and model backbones. The full ACA method consistently achieves the highest accuracy scores across all four benchmarks for both model backbones. Adaptive Computation Allocation substantially reduces the token count required for inference compared to the vanilla baseline. Combining adaptive allocation with early stopping yields better performance than using adaptive allocation without early stopping.
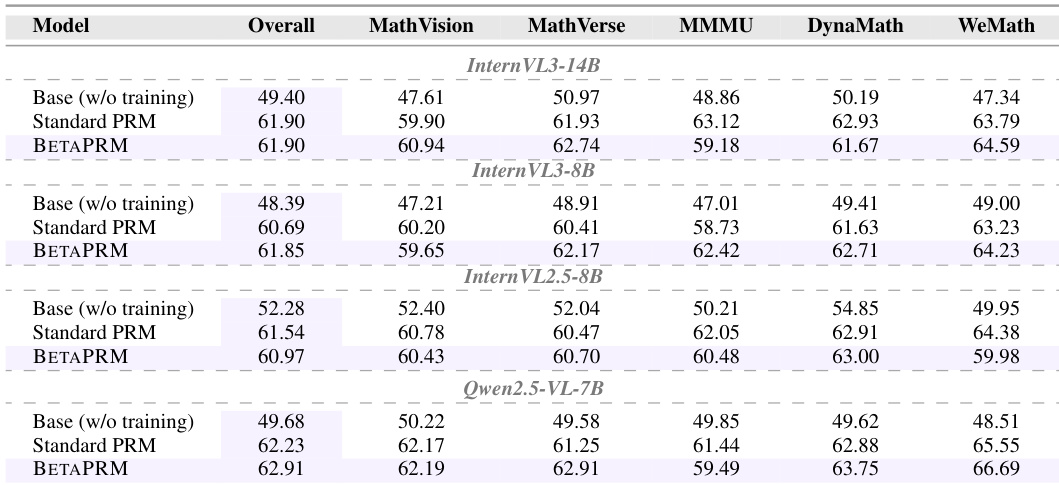
The study evaluates Process Reward Models for Best-of-N selection across four vision-language backbones. Results indicate that the proposed BETAPRM method improves selection accuracy over both untrained base models and Standard PRM baselines. The method effectively leverages uncertainty estimates to enhance performance across diverse mathematical benchmarks. BETAPRM improves Best-of-N selection accuracy across all evaluated backbones. The proposed method achieves superior accuracy compared to Standard PRM and untrained baselines. Performance gains are consistent across multiple mathematical reasoning benchmarks.
The study evaluates the BETAPRM method across multiple vision-language backbones and math benchmarks to validate its effectiveness as a solution selector for Best-of-N reasoning. Results indicate that leveraging learned uncertainty estimates and an auxiliary evidence regularizer enables BETAPRM to consistently outperform Standard PRM baselines in final-answer accuracy. Furthermore, experiments on Adaptive Computation Allocation demonstrate that combining this method with early stopping optimizes inference efficiency by significantly reducing token consumption while maintaining superior performance.