Command Palette
Search for a command to run...
Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
Yixuan Yang Zhen Luo Wanshui Gan Jinkun Hao Junru Lu Jinghao Yan Zhaoyang Lyu Xudong Xu
Abstract
Designing realistic and functional 3D indoor rooms is essential for a wide range of applications, including interior design, virtual reality, gaming, and embodied AI. While recent MLLM-based approaches have shown great potential for 3D room synthesis from textual descriptions or reference images, text-based methods struggle to capture precise spatial information, and existing image-conditioned agents suffer from instability and infinite looping when tasked with holistic room generation from top-down views. To address these limitations, we propose Code-as-Room, an MLLM-based agentic framework equipped with a structured execution harness, which represents 3D rooms with Blender codes. Given a top-down room image, the framework parses the reference image to extract scene elements and their spatial relationships, and synthesizes executable Blender code for geometry, materials, and lighting in a principled, multi-stage pipeline. A cross-stage memory module is maintained throughout to mitigate context forgetting inherent to existing agent-based frameworks. We further introduce a dedicated benchmark for code-based 3D room synthesis, encompassing various evaluation protocols. Based on our benchmark, comprehensive comparisons against existing agent-based methods are conducted to validate the effectiveness of our proposed execution harness.
One-sentence Summary
Code-as-Room is an MLLM-based agentic framework that generates 3D rooms from top-down view images by synthesizing executable Blender code through a structured execution harness and a cross-stage memory module, mitigating the instability and context forgetting of prior agents while validating its effectiveness via a dedicated benchmark with comprehensive evaluation protocols.
Key Contributions
- Code-as-Room is an MLLM-based agentic framework that represents complete 3D indoor rooms as executable Blender code to enable direct synthesis from top-down visual inputs.
- The framework employs a structured multi-stage pipeline to generate geometry, materials, and lighting while integrating a cross-stage memory module to preserve spatial relationships and mitigate context forgetting.
- The study introduces a dedicated benchmark for code-based 3D room synthesis with diverse evaluation protocols to validate the execution harness against existing agent-based methods.
Introduction
The authors leverage multimodal large language models to automate the generation of complete, editable 3D indoor rooms from top-down layout images, a capability that significantly accelerates labor-intensive workflows in interior design, virtual reality, and embodied AI. Prior approaches relying on text prompts frequently lack precise spatial information, while existing image-conditioned agent frameworks struggle with unstable execution, infinite looping, and severe context forgetting when processing holistic floor plans. To address these challenges, the authors introduce Code-as-Room, an agentic system that translates top-down references into executable Blender code through a structured, multi-stage pipeline. By integrating a cross-stage memory module and a dedicated execution harness, the framework ensures stable spatial reasoning, coherent scene assembly, and reliable photorealistic rendering without manual intervention.
Method
The framework, referred to as Code-as-Room, operates as a multi-stage agentic pipeline that transforms a top-down room image into executable Blender code. The process is structured to decompose the complex task of 3D scene synthesis into a coarse-to-fine workflow, ensuring robustness and modularity. The overall architecture is guided by a shared cross-stage memory that maintains a persistent state across all stages, enabling coherent information flow and reducing context drift in long agentic sequences.
The initial phase, Stage 1, performs spatial semantic analysis on the input image to extract a schema-constrained description, identifying functional zones, architectural elements, and object hierarchies. This foundational understanding is stored in the memory. Building upon this, Stage 2 constructs an object-centric scene graph, defining a skeleton of architectural features, major layout-defining objects, and their hierarchical relationships, along with a sidecar for minor objects. This graph and its associated data are also written to the memory, providing a structured representation of the scene's spatial layout.
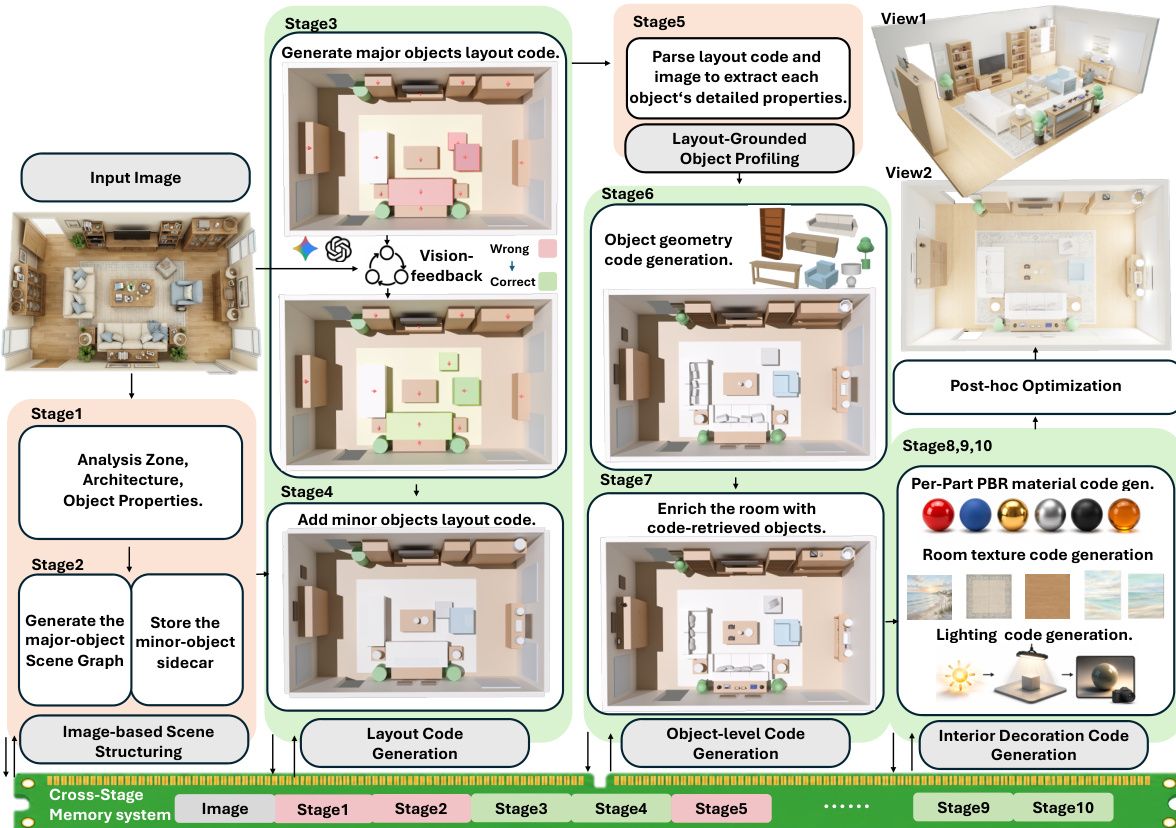
The coarse stage then proceeds to generate a layout program. Stage 3 focuses on creating the major layout, initiating a render-critique–revise loop where the current code is rendered, evaluated by a vision-language model (VLM) critic, and iteratively refined based on the feedback. This feedback is sanitized to ensure compatibility with the initial structural constraints before the code is revised. The process continues until a quality threshold is met or a maximum iteration limit is reached. Stage 4 complements this by adding wall-mounted objects and visually salient minor objects, such as rugs and floor lamps, to the layout, which are appended as primitive-constructor calls. The resulting layout code serves as a scaffold for the subsequent fine-grained stages.

The fine stage begins with Stage 5, which enriches the layout by generating detailed descriptions for each object based on the input image and the fixed layout attributes. This includes fine-grained information on color, material, and style, which is then used in Stage 6 to replace the initial proxy geometry with a more complex, part-based 3D geometry primitive decomposition. This replacement is performed by mapping each object in the layout code to its corresponding set of generated parts, ensuring the object inherits the coarse layout's pose. For tiny objects, a hybrid strategy combines simple geometric placeholders with retrieval from an asset library based on semantic and size compatibility.
The final refinement occurs in the interior decoration stages. Stage 8 assigns PBR materials to the semantic parts of objects, using the generated descriptions and global room style. Stage 9 generates high-resolution texture maps for large surfaces using an image generation model and integrates them into the material node graphs, ensuring proper UV mapping for planar elements. Finally, Stage 10 completes the scene by setting up lighting and rendering parameters based on the input image's cues, and applies a deterministic post-hoc correction pass to fix common implementation issues like missing materials, invalid paths, and geometric artifacts. This culminates in the final executable code, which can be directly executed in Blender to instantiate the complete 3D room scene.
Experiment
The study evaluates an agentic harness for top-down image-to-3D room generation through a multi-scene benchmark, expert human assessments, and component ablation studies. Results indicate that structured multi-stage workflows significantly improve spatial reasoning, layout consistency, and scene usability compared to direct single-pass generation and existing pipelines. While different vision-language models exhibit distinct strengths in capturing fine details versus coarse structures, the agentic framework consistently mitigates execution instability and enhances overall quality. Furthermore, ablation experiments confirm that cross-stage memory and a limited visual feedback loop are essential for maintaining spatial coherence, while the resulting 3D scenes effectively serve as reliable structural priors for high-fidelity visual refinement.
The authors evaluate their agentic framework for converting top-down images into 3D room models, comparing different vision-language models and configurations. Results show that incorporating memory and visual feedback significantly improves performance across multiple metrics, with the full model outperforming variants lacking these components. The full model with memory and visual feedback achieves the highest performance across all evaluated metrics. Removing the memory mechanism leads to a significant drop in layout consistency and object recall. Visual feedback iterations improve results up to a point, but too many iterations can degrade layout and rotation accuracy.
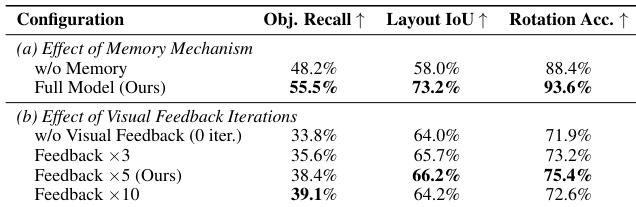
The authors evaluate different vision-language models for 3D room generation from top-down images using a benchmark that assesses visual understanding, spatial reasoning, code generation, and scene quality. Results show that the agentic workflow significantly improves performance across all metrics, with Gemini-based models achieving the most stable and accurate outputs compared to direct generation methods. The effectiveness of memory and visual feedback in the pipeline is further validated through ablation studies. The agentic workflow consistently improves performance across all evaluation metrics compared to direct generation. Gemini-based models achieve more stable and accurate results in spatial reasoning and object placement than GPT-5.5. Memory and visual feedback components in the pipeline are critical, with optimal performance achieved at five feedback iterations.

The authors evaluate their agentic framework, Code-as-Room, for generating 3D room scenes from top-down images using various vision-language models. Results show that the framework consistently improves scene quality, especially in usability and acceptability, compared to direct generation and existing pipelines, with performance varying based on the VLM backbone and the inclusion of memory and visual feedback mechanisms. Code-as-Room significantly improves scene usability and acceptability over direct generation and baseline methods. The framework enhances performance across all evaluated metrics when using different vision-language models, with Gemini-based variants showing strong spatial reasoning and stability. Ablation studies confirm that memory and visual feedback are critical components, with optimal performance achieved using a balanced number of refinement iterations.
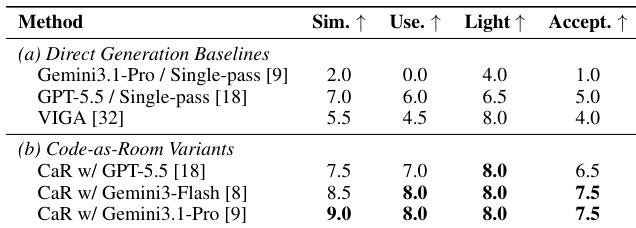
The authors evaluate an agentic framework for generating 3D room models from top-down images by benchmarking it against direct generation methods and existing pipelines across multiple vision-language models. Ablation studies validate that incorporating memory mechanisms and iterative visual feedback are essential for enhancing layout consistency, object recall, and overall scene usability. The framework consistently outperforms baselines, with Gemini-based models demonstrating superior spatial reasoning and stability. Optimal performance is achieved at a balanced number of refinement iterations, as excessive feedback cycles ultimately degrade geometric accuracy.