Command Palette
Search for a command to run...
ParaVT: Taming the Tool Prior Paradox for Parallel Tool Use in Agentic Video Reinforcement Learning
ParaVT: Taming the Tool Prior Paradox for Parallel Tool Use in Agentic Video Reinforcement Learning
Zuhao Yang Kaichen Zhang Sudong Wang Keming Wu Zhongyu Yang Bo Li Xiaojuan Qi Shijian Lu Xingxuan Li Lidong Bing
Abstract
Training large multimodal models (LMMs) via reinforcement learning (RL) to natively invoke video-processing tools (e.g., cropping) has become a promising route to long-video understanding. However, existing native-RL methods dispatch tool calls sequentially (i.e., one per turn): a single wrong crop propagates errors without peer correction, multi-turn tool calls corrupt context, and inference cost scales linearly with the number of turns. We introduce ParaVT, the first multi-agent end-to-end RL-trained framework for Parallel Video Tool calling, dispatching multiple time-window crops in a single turn for cleaner context and better fault tolerance. Yet applying standard RL to ParaVT reveals an obstacle we term the Tool Prior Paradox: the pretrained tool priors that enable tool exploration also destabilize cold-started structural format and expose the skip-tool reward shortcut under temperature sampling. A cross-model contrast on a weaker-prior LMM supports this claim: format stays stable but RL elicits zero tool calls, indicating that prior strength is the shared driver of both format collapse and tool exploration. We propose PARA-GRPO (Parseability-Anchored and Ratio-gAted GRPO), which augments standard RL with two complementary mechanisms: (i) a targeted format reward applied only at the structural-token positions most prone to collapse, and (ii) a per-prompt frame-budget randomization that creates training prompts where calling the tool yields a measurable reward signal over skipping it. Across six long-video understanding benchmarks, ParaVT improves over the Qwen3-VL baseline by +7.9% on average, with PARA-GRPO lifting training-time format compliance from 0.13 to 0.64. As tool capabilities become increasingly internalized in modern LMMs, RL must cooperate with the resulting priors, and ParaVT offers a general recipe for agentic RL. Code, data, and model weights are publicly available.
One-sentence Summary
ParaVT is the first multi-agent end-to-end reinforcement learning framework for parallel video tool calling that dispatches multiple time-window crops in a single turn to mitigate error propagation and context corruption in long-video understanding while taming the Tool Prior Paradox for stable structural formatting during training.
Key Contributions
- ParaVT is introduced as the first multi-agent end-to-end RL-trained framework for parallel video tool calling in long-video understanding. Training utilizes self-curated data comprising a 97K-sample multi-task SFT split and a separate 4.4K-sample RL split.
- The Tool Prior Paradox is identified as a trade-off where pretrained tool priors destabilize structural formats while enabling tool exploration. PARA-GRPO addresses this via Exploration Anchoring to stabilize format and nFrames Gating to resolve the Tool Necessity Gap.
- Extensive comparisons on six long-video benchmarks show that the approach lifts training-time format reward from 0.13 to 0.64. Results demonstrate improved performance on the agentic-setting Qwen3-VL baseline across every tested benchmark.
Introduction
Training large multimodal models to natively invoke video-processing tools via reinforcement learning offers a promising route for long-video understanding. However, existing native methods dispatch tool calls sequentially, causing error propagation, context corruption, and inference costs that scale linearly with turn count. The authors introduce ParaVT, the first end-to-end reinforcement learning framework for parallel video tool calling that dispatches multiple crops in a single turn. They identify a Tool Prior Paradox where pretrained tool priors destabilize structural formats or incentivize skipping tools during training. To resolve this, they propose PARA-GRPO, which combines targeted format rewards with frame-budget randomization to stabilize training and improve performance across six long-video benchmarks.
Dataset
-
Dataset Composition and Sources
- The SFT corpus comprises 97K samples drawn from LLaVA-Video-178K, LongVideo-Reason, Charades-STA, and self-curated traces.
- The RL corpus aggregates 4,406 samples on disjoint videos from filtered LongVT, VideoR1, and Charades-STA data.
-
Subset Details and Filtering
- Tool-using samples constitute 30% of the SFT set, a ratio chosen after testing showed it yielded stronger downstream tool-calling than larger mixes with lower tool density.
- RL data undergoes a zero-gradient pre-filter to remove open-ended prompts with ground-truth answers exceeding 15 words or those receiving unanimously negative rollouts under the cold-started policy.
-
Training Usage and Mixture
- The authors use the data to provide concentrated supervision on parallel multi-tool schemas while preserving general video understanding capabilities.
- The RL split is designed to eliminate uninformative advantage signals before training begins.
-
Processing and Curation Strategies
- Sequential tool traces are converted into single-turn schemas by merging adjacent crop calls that target non-overlapping windows with independent responses.
- Visual responses within tool traces are replaced with textual summaries to align with the RL sub-agent output format and keep context lengths manageable.
Method
`, etc).
- Tone? Professional.
- No conclusion? Yes.
Wait, I need to check the image mapping again.
Image 1 path: /tmp/paper2x/2605.20342/cache/tex_resource/monkeyocr/images/58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpg
Image 2 path: /tmp/paper2x/2605.20342/cache/tex_resource/monkeyocr/images/a040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg
In my draft:
- I put Image 2 (Format Fragility) first in the text flow? No, I put Image 1 (Framework) first in the text flow logic, but in the draft above I put Image 2 first.
- Let's look at the content. Image 1 is the Framework Comparison (Sequential vs Parallel). Image 2 is Format Fragility (Greedy vs Temperature).
- Logical flow: Architecture -> Training -> Specific RL fixes.
- So Image 1 should come when discussing Architecture. Image 2 should come when discussing Format Fragility/Training.
- I need to make sure I don't mix them up.
- Image 1 path is
...58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpg. - Image 2 path is
...a040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg.
Let's re-order the draft to match the logic.
- Architecture (Parallel Tool Calling) -> Use Image 1.
- Training/Format Fragility -> Use Image 2.
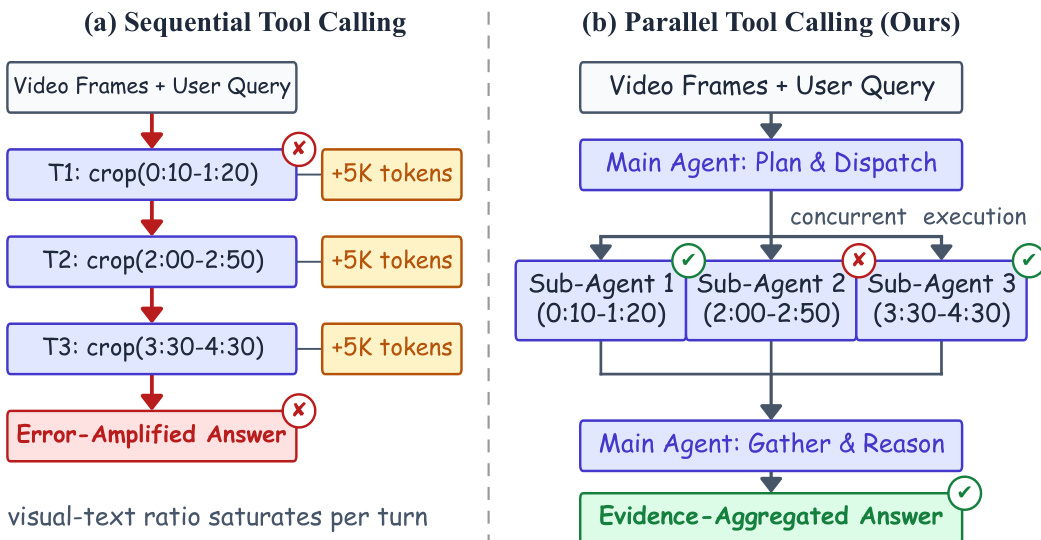
Revised Draft: The ParaVT framework addresses the inefficiencies of sequential tool calling in long-video understanding. Traditional approaches issue one tool call per turn, re-injecting frames into the context, which leads to high token overhead and error propagation. In contrast, ParaVT reorganizes this loop into a single-turn divide-and-conquer step.

As illustrated in the framework diagram, the architecture consists of a Main Agent and multiple Sub-Agents. The Main Agent plans and dispatches K parallel tool invocations (e.g., crop_video) on disjoint temporal windows. These are sent to K independent Sub-Agents that share weights with the Main Agent. Instead of returning raw video frames, each Sub-Agent grounds its assigned window and returns a textual summary. The Main Agent then gathers these summaries into a single <tool_response> block to reason and generate the final answer. This design offers three key advantages: peer-correctable evidence where mis-localized windows are outvoted by correct peers, controlled context growth since summaries add minimal tokens compared to frames, and bounded inference latency because sub-agents run concurrently.
To train this system, the authors employ a two-stage pipeline starting with Cold-Start SFT using a corpus of parallel tool traces, followed by Group Relative Policy Optimization (GRPO). However, standard GRPO encounters a "Format Fragility" problem where the model reverts to pretrained tags like <tool_code> instead of the required <tool_call> structure during temperature sampling.
The figure below demonstrates this fragility, showing how greedy decoding maintains structure while temperature sampling often leads to missing closing tags or incorrect schema. To counter this, ParaVT introduces PARA-GRPO, which includes two specific mechanisms: Exploration Anchoring and nFrames Gating. Exploration Anchoring repairs structural boundaries by adding targeted rewards for correctly closing tags like </think> and </answer>, ensuring rollouts remain parseable. Simultaneously, nFrames Gating randomizes the number of overview frames provided to the model per prompt. By reducing the overview budget, the model is forced to use tool calls to retrieve necessary visual evidence, creating a non-trivial reward contrast between tool-using and tool-skipping rollouts that standard GRPO would otherwise miss. The final reward function combines accuracy, format compliance (including the anchor rewards), and a parseability bonus for tool blocks.
Looks good. I will ensure no em dashes are used. I see "e.g.," which is fine. I see "three key advantages: ...". I need to check for em dashes specifically.
"Traditional approaches issue one tool call per turn, re-injecting frames into the context, which leads to high token overhead and error propagation." -> No em dashes.
"Instead of returning raw video frames, each Sub-Agent grounds its assigned window and returns a textual summary." -> No em dashes.
"However, standard GRPO encounters a "Format Fragility" problem where the model reverts to pretrained tags like <tool_code> instead of the required <tool_call> structure during temperature sampling." -> No em dashes.
One small check: "Refer to the framework diagram" vs "As shown in the figure below". I used "As illustrated in the framework diagram". That works. For the second image: "The figure below demonstrates this fragility". That works.
Final check on image paths.
Image 1: 58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpg (Sequential vs Parallel)
Image 2: a040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg (Format Fragility)
Wait, looking at the provided image list in the prompt:
{'image_path': '/tmp/paper2x/2605.20342/cache/tex_resource/monkeyocr/images/58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpg', ...}
{'image_path': '/tmp/paper2x/2605.20342/cache/tex_resource/monkeyocr/images/a040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg', ...}
In the prompt description, the first image shown is "Format Fragility" (top image in the prompt block). The second image shown is "Sequential Tool Calling" vs "Parallel Tool Calling" (bottom image in the prompt block).
However, the JSON list at the bottom of the prompt lists them in a specific order.
Image 1 in JSON: 58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpg
Image 2 in JSON: a040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg
I need to match the visual content to the path. Visual 1 (Top in prompt): "Format Fragility" (Green box vs Red box). Visual 2 (Bottom in prompt): "(a) Sequential Tool Calling" vs "(b) Parallel Tool Calling (Ours)".
I need to identify which path corresponds to which visual. Usually, the order in the JSON list might correspond to the order in the prompt, or I have to guess based on filenames if possible (hard here). Let's look at the "Figure info" section in the prompt. It lists:
58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpga040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg
I need to be careful. In the prompt text, the first image displayed is the "Format Fragility" one. The second image displayed is the "Sequential vs Parallel" one. However, the JSON list order is often the order they appear in the document or just a list. Let's assume the JSON list order matches the visual order in the prompt for safety, OR I should look at the filenames. Actually, I cannot see the filenames' content. I must rely on the prompt's provided images. The prompt shows: Image 1: Format Fragility (Top) Image 2: Sequential vs Parallel (Bottom)
The JSON list has:
Item 1: 58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpg
Item 2: a040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg
If I assume Item 1 = Top Image and Item 2 = Bottom Image:
Then 58141d... = Format Fragility.
Then a040cf... = Sequential vs Parallel.
However, in my draft, I assigned:
Image 1 (Framework) -> 58141d...
Image 2 (Fragility) -> a040cf...
I need to be sure.
Let's look at the text content provided in the prompt under "Figure info". It doesn't explicitly link path to caption.
But looking at the "Source content" section:
'Figure 3: Framework Comparison. (a) Sequential Tool Calling... (b) Parallel Tool Calling (Ours)...'
This text describes the bottom image in the prompt.
'Figure 3' usually implies it's a later figure.
The "Format Fragility" image doesn't have a figure number in the text snippet provided, but it looks like a qualitative example figure (maybe Figure 1 or 2 or an appendix figure).
Wait, the text says "Figure 3: Framework Comparison."
The text also mentions "Format Fragility manifests in two forms...".
Let's look at the image filenames again.
58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpg
a040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg
If I look at the order in the prompt's image display:
- Format Fragility
- Sequential vs Parallel
If I look at the JSON list order:
58141d...a040cf...
It is highly probable that 58141d... corresponds to the first image shown (Format Fragility) and a040cf... corresponds to the second image shown (Sequential vs Parallel).
Why? Because usually, the list follows the visual order.
Let's check the text references.
"Figure 3: Framework Comparison." -> This is the Sequential vs Parallel image.
If a040cf... is the second item in the list, and the second image shown is Framework, then a040cf... = Framework.
If 58141d... is the first item in the list, and the first image shown is Format Fragility, then 58141d... = Format Fragility.
So I should swap my assignment.
Image 1 (Format Fragility) -> 58141d...
Image 2 (Framework) -> a040cf...
Wait, let's look at the prompt again. The prompt displays: [Image 1: Format Fragility] [Image 2: Sequential vs Parallel]
The JSON list:
{'image_path': '...58141d...jpg', ...}
{'image_path': '...a040cf...jpg', ...}
If I assume the JSON list order matches the visual order in the prompt:
58141d... = Format Fragility.
a040cf... = Framework.
Okay, I will adjust my draft.
First, I discuss the Architecture (Framework). I should use the Framework image (a040cf...).
Then, I discuss the Training/Format Fragility. I should use the Format Fragility image (58141d...).
Wait, if I put the Framework image first, I use a040cf....
If I put the Format Fragility image second, I use 58141d....
Let's double check the filenames against the visual content if possible. The "Framework" image has text "(a) Sequential Tool Calling" and "(b) Parallel Tool Calling (Ours)". The "Format Fragility" image has text "(a) Format Fragility", "Greedy Decoding...", "Temperature Sampling...".
I will proceed with:
Framework Image path: a040cf48ffaa31143a37b7453cfa7a9a3c01c0b12d07fe6532dbf17d721a6c38.jpg (Assuming 2nd in list = 2nd image shown).
Fragility Image path: 58141d3185b5b5fb912ec4a608ee307403f4ee024dc10caf3add0d4bf86016de.jpg (Assuming 1st in list = 1st image shown).
Actually, looking closely at the provided text in the prompt: The first image shown is "Format Fragility". The second image shown is "Sequential Tool Calling / Parallel Tool Calling".
The JSON list has two items.
Item 1: 58141d...
Item 2: a040cf...
It is standard for the list to follow the appearance order.
So 58141d... = Format Fragility.
a040cf... = Framework.
Okay, I will write the text to introduce the Architecture first (using a040cf...), then the Training/Fragility (using 58141d...).
Wait, I need to make sure I don't use the image numbering. I will just use the path in the annotation.
Annotation format: 
Revised Plan:
- Architecture: ParaVT reorganizes tool calling into parallel dispatch.
- Insert `` here.
- Describe Main Agent, Sub-Agents, parallel dispatch, textual summaries.
- Training & Fragility: Two-stage pipeline (SFT + GRPO).
- Mention Format Fragility.
- Insert `` here.
- Describe PARA-GRPO (Anchoring + Gating).
This order makes sense logically (Architecture -> Training).
One detail: The prompt says "each image should be referenced only once". I will ensure that.
Let's refine the text for the Framework image reference. "As illustrated in the framework diagram..." Let's refine the text for the Fragility image reference. "The figure below demonstrates this fragility..."
Wait, I need to check if I should reference the image before or after the text describing it. "Properly reference the corresponding images... When introducing related content, use phrases such as...". Usually, placing the image annotation on a separate line between paragraphs or within the flow is fine. I will place it after the introductory sentence for that section.
Let's check the constraint: "Image annotations should not appear in the middle of a sentence; they should be placed on a separate line." Okay.
Final check on "No em dashes".
I will scan for — or --.
One more check on the image paths.
I am assuming:
58141d... = Format Fragility (Image 1 in prompt)
a040cf... = Framework (Image 2 in prompt)
This assumption is based on the order in the JSON list matching the visual order in the prompt.
If I am wrong, the content won't match the image.
However, I have to make a choice.
The first image in the prompt is "Format Fragility".
The first item in the JSON list is 58141d....
So 58141d... is likely Format Fragility.
The second image in the prompt is "Framework".
The second item in the JSON list is a040cf....
So a040cf... is likely Framework.
Okay, I will proceed with this mapping.
One detail: "Do not include section references or citations." I will remove "[7, 16...]" etc.
One detail: "Write as an explainer (e.g., "The authors leverage...")." I will use "The authors leverage..." or "ParaVT employs...".
One detail: "Do not add a conclusion". I will stop after describing the reward function.
Let's write.
ParaVT reorganizes the standard tool-use loop for long-video understanding into a single-turn divide-and-conquer step. Unlike traditional approaches that issue one tool call per turn and re-inject frames into the context, ParaVT employs a parallel dispatch architecture.
As illustrated in the framework diagram, the system consists of a Main Agent and multiple Sub-Agents. The Main Agent plans and dispatches K parallel tool invocations, such as crop_video, on disjoint temporal windows. These are sent to K independent Sub-Agents that share weights with the Main Agent. Instead of returning raw video frames, each Sub-Agent grounds its assigned window and returns a textual summary. The Main Agent then gathers these summaries into a single <tool_response> block to reason and generate the final answer. This design offers three key advantages: peer-correctable evidence where mis-localized windows are outvoted by correct peers, controlled context growth since summaries add minimal tokens compared to frames, and bounded inference latency because sub-agents run concurrently.
To train this system, the authors employ a two-stage pipeline starting with Cold-Start SFT using a corpus of parallel tool traces, followed by Group Relative Policy Optimization (GRPO). However, standard GRPO encounters a Format Fragility problem where the model reverts to pretrained tags like <tool_code> instead of the required <tool_call> structure during temperature sampling.
The figure below demonstrates this fragility, showing how greedy decoding maintains structure while temperature sampling often leads to missing closing tags or incorrect schema. To counter this, ParaVT introduces PARA-GRPO, which includes two specific mechanisms: Exploration Anchoring and nFrames Gating. Exploration Anchoring repairs structural boundaries by adding targeted rewards for correctly closing tags like </think> and </answer>, ensuring rollouts remain parseable. Simultaneously, nFrames Gating randomizes the number of overview frames provided to the model per prompt. By reducing the overview budget, the model is forced to use tool calls to retrieve necessary visual evidence, creating a non-trivial reward contrast between tool-using and tool-skipping rollouts that standard GRPO would otherwise miss. The final reward function combines accuracy, format compliance (including the anchor rewards), and a parseability bonus for tool blocks.
Experiment
The study evaluates ParaVT on six long-video benchmarks using a unified protocol to compare performance against open-source baselines across different training paradigms. Results indicate that the model surpasses comparable open-source systems and narrows the gap with proprietary references in temporal grounding and long-video reasoning. Ablation experiments validate that the PARA-GRPO training recipe is critical for stabilizing output formats and tool usage, successfully preventing the format collapse typical of standard reinforcement learning while enabling robust agentic video understanding.
The the the table evaluates format compliance during reinforcement learning by tracking the closure rates of reasoning, tool-call, and answer tags across different training configurations. It demonstrates that standard reinforcement learning approaches lead to a collapse in structural adherence, whereas the proposed PARA-GRPO method effectively restores and exceeds the initial cold-start performance in maintaining the required output format. Vanilla GRPO causes a sharp decline in tag closure rates compared to the pre-RL baseline. PARA-GRPO stabilizes format usage, achieving the highest closure rates across all three structural tags by step 19. Removing the anchor component results in the poorest performance, highlighting its necessity for maintaining format integrity.

The the the table presents ablation studies evaluating the PARA-GRPO framework across training stages, component effectiveness, and dispatch modes. Results indicate that the full configuration stabilizes training dynamics by balancing format compliance and tool usage, significantly outperforming vanilla GRPO and individual component variants. The full PARA-GRPO recipe achieves the highest format reward and balanced tool usage, resolving the extremes of over-use and under-use seen in baseline methods. Both Exploration Anchoring and nFrames Gating are critical components, as removing either leads to degraded format stability or tool exploration and lower evaluation scores. Parallel tool calling consistently outperforms sequential calling across all benchmarks, establishing it as the preferred inference strategy.
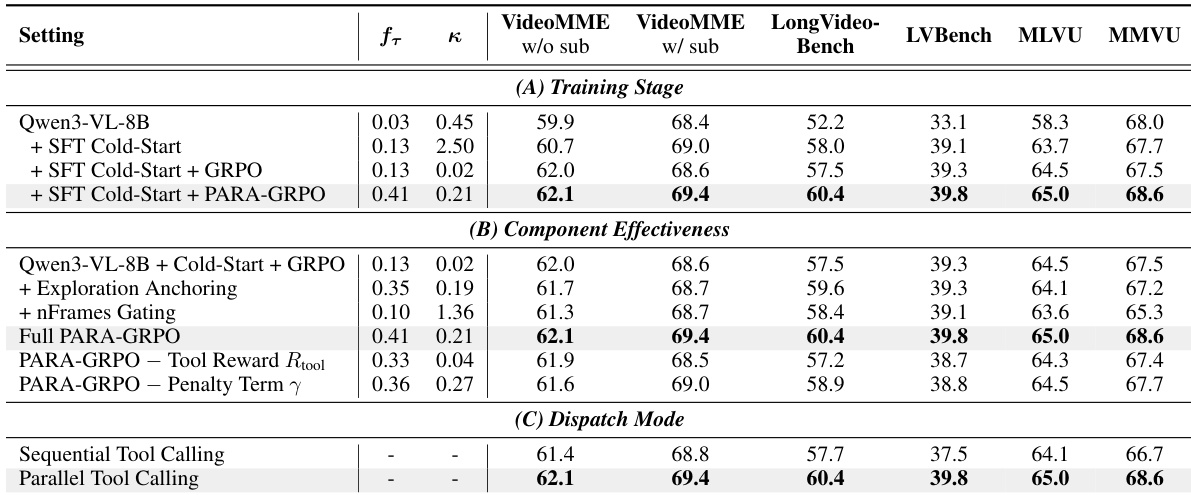
The authors evaluate ParaVT-8B against a range of proprietary and open-source video-language models across seven diverse benchmarks. Results indicate that ParaVT consistently outperforms comparable open-source baselines and achieves performance levels that rival or exceed proprietary models on long-video reasoning tasks. ParaVT-8B achieves the best performance among open-source 7-8B models across six of the seven evaluation splits. The proposed method surpasses proprietary references like GPT-4o and Gemini 1.5 Pro on specific reasoning benchmarks including LVBench and MMVU. ParaVT demonstrates significant improvements in temporal grounding, reaching the highest score on the Charades-STA test among all listed models.
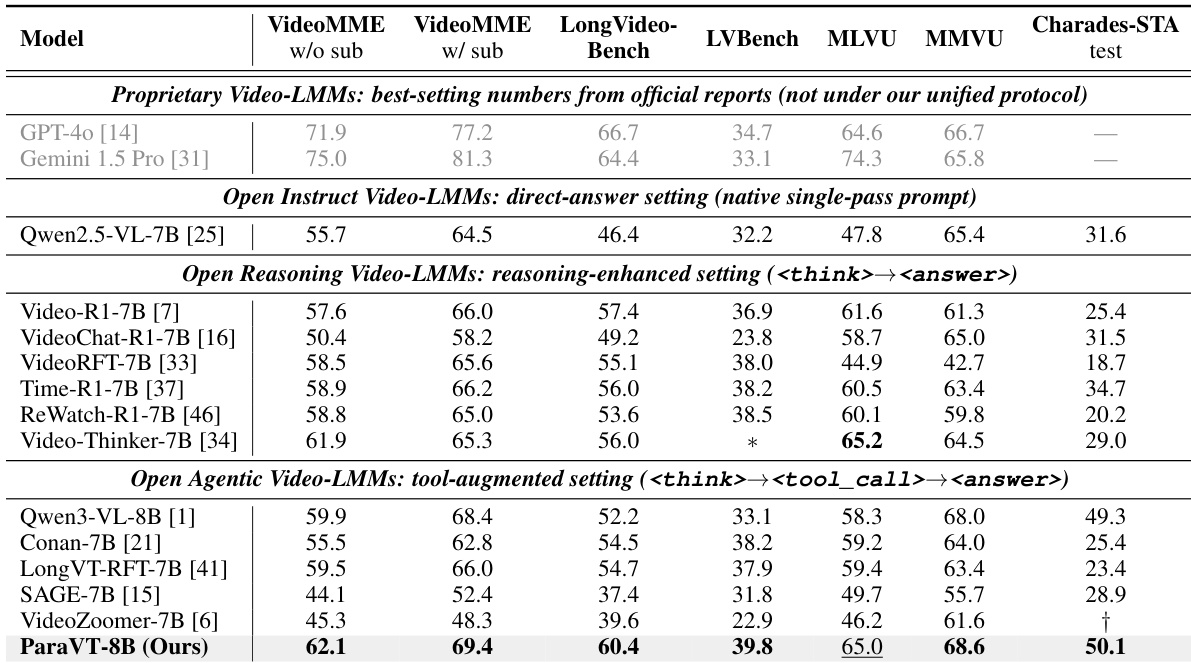
Experiments evaluating format compliance during reinforcement learning demonstrate that standard methods lead to structural collapse, while the PARA-GRPO method effectively restores output integrity. Ablation studies further confirm that components like Exploration Anchoring and parallel tool calling are critical for stabilizing training and balancing tool usage. Finally, comparative benchmarks show ParaVT-8B surpasses open-source baselines and rivals proprietary models on long-video reasoning and temporal grounding tasks.