Command Palette
Search for a command to run...
EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
Abstract
The rapid evolution of generative video foundation models has propelled the field toward professional-grade cinematic synthesis. To achieve such demanding quality, the community transitions towards Reinforcement Learning (RL) and agentic workflows. However, reliable evaluation has emerged as a critical bottleneck. Existing benchmarks predominantly evaluate ''whether it is right'' (basic prompt-following) while fundamentally neglecting ''whether it is good'' (cinematic quality, acting, and aesthetics). Furthermore, current automated metrics lack the domain-specific rigor required to provide trustworthy signals, creating a severe credibility gap between human aesthetic perception and machine scoring. To bridge this gap, we introduce EvalVerse, a comprehensive, pipeline-aware, and expert-calibrated evaluation framework. We treat video generation assessment not merely as an engineering task, but as a core scientific problem: the systematic digitization of subjective cinematic expertise. First, we organize domain knowledge into an evaluation taxonomy aligned with the professional filmmaking workflow (pre-production, production, and post-production). Second, we distill human expert judgments into a curated dataset with large-scale human annotations. Third, we inject this knowledge into Vision-Language Models (VLMs) through an expert-calibrated fine-tuning strategy, enabling the VLM to perform explicit Chain-of-Thought reasoning. Compared to previous works, EvalVerse not only retains compatibility with foundational ''rightness'' metrics, but also significantly expands the criteria to ''goodness'' and broaden the task coverage to complex multi-shot sequencing and audio-visual integration. Consequently, by providing granular diagnostic signals, EvalVerse transcends a static leaderboard and establishes a fundamental infrastructure for future work, such as reward models and evaluator agent.
One-sentence Summary
EvalVerse is a pipeline-aware and expert-calibrated benchmarking framework that advances cinematic video assessment beyond basic prompt-following by systematically digitizing subjective expertise through a workflow-aligned taxonomy and a curated human-annotated dataset, thereby bridging the credibility gap between automated metrics and human aesthetic perception for professional cinematic video generation.
Key Contributions
- EvalVerse introduces a pipeline-aware evaluation framework that structures professional filmmaking expertise into a comprehensive taxonomy spanning pre-production, production, and post-production phases. The framework utilizes a Real-to-Gen data engine to construct high-fidelity test pairs through proportional sampling from authentic professional video distributions.
- A systematic human-machine calibration mechanism distills large-scale expert annotations into a curated dataset and injects this domain knowledge into vision-language models. This process translates subjective cinematic standards into scalable, expert-aligned chain-of-thought reasoning for automated assessment.
- Comprehensive evaluations demonstrate strong human-machine alignment across complex multi-shot sequencing and audio-visual integration dimensions. The resulting metrics provide trustworthy diagnostic signals and dense reward vectors to support reinforcement learning optimization and autonomous agentic workflows in generative video synthesis.
Introduction
The rapid evolution of generative video models is driving the field toward professional cinematic synthesis, making fine-grained evaluation critical for training next-generation systems with reinforcement learning and autonomous agents. Existing benchmarks, however, primarily measure basic prompt-following and fail to assess nuanced cinematic quality, creating a significant credibility gap between human aesthetic judgment and automated scoring. To bridge this divide, the authors introduce EvalVerse, a pipeline-aware evaluation framework that maps professional filmmaking workflows into a structured diagnostic taxonomy. By distilling expert judgments into a large-scale annotated dataset and fine-tuning vision-language models with a structured reasoning process, they successfully translate subjective cinematic expertise into scalable, interpretable machine metrics. This methodology enables rigorous assessment of complex multi-shot and audio-visual generation while providing the reliable reward signals required to advance future generative pipelines.
Dataset

-
Composition and Sources: The authors curate a benchmark dataset drawn from a diverse collection of professional films and animations. The database is structured to evaluate video generation models across nine core cinematic dimensions, emphasizing technical fidelity, artistic rendering, and narrative continuity.
-
Subset Details and Distribution: The authors do not partition the data for training. Instead, they use the full collection as an evaluation set and apply a proportional sampling strategy across the nine dimensions to establish precise mixture ratios. Key subsets include the Aesthetics dimension, which covers visual quality, chromaticity, materiality, and lighting, and the Multi-Shot dimension, which assesses sequential logic and editing rhythm.
-
Data Usage and Workflow: The dataset serves exclusively as a testing benchmark rather than a training resource. The authors construct Real to Gen test pairs to drive downstream generation tasks and measure model capabilities. These pairs function as structured ground truth references and prompt targets for comparative evaluation across different video generation architectures.
-
Processing and Metadata Construction: The pipeline begins with a multi modal perception suite that extracts structured JSON metadata, capturing camera parameters, character attributes, and environmental details. After industrial grade processing and rigorous manual verification, the authors use Gemini 3.1 Pro to synthesize professional cinematic prompts from the metadata and raw captions. For reference based tasks, they extract keyframes and process them through Nano Banana Pro to create high fidelity reference images, while a ControlNet tuned model generates corresponding depth sequences.
Method
The framework of EvalVerse is structured around a comprehensive, pipeline-aware taxonomy that mirrors the traditional cinematic workflow, dividing video evaluation into three distinct stages: Pre-Production, Production, and Post-Production. This hierarchical structure organizes 18 main dimensions and 45 sub-dimensions, each designed to assess specific aspects of video quality from a professional filmmaking perspective. The taxonomy serves as the foundation for a systematic evaluation pipeline, guiding both human and machine assessment processes. Refer to the framework diagram to understand how the core dimensions are distributed across the three stages and how they relate to the overall evaluation process.
The evaluation pipeline is implemented in five steps. Step I involves the establishment of the taxonomy, defining the conceptual framework and its constituent dimensions. Step II focuses on dataset curation, where a large-scale, high-quality database of film and television content is assembled, augmented with industrial operators and human annotations. This step includes comprehensive sampling strategies and test pair construction, ensuring diverse and representative data for evaluation. Step III involves expert human evaluation, where a team of 14 video AIGC research scientists and engineers, along with 20 professional artists, perform both ranking-based and thoroughly considered scoring, with a workflow designed to ensure cross-checking and validation. Step IV constitutes the machine evaluation suite, which includes professional operator development and chain-of-thought evaluation. Step V enables application through benchmarking and the deployment of the trained models.
At the core of the machine evaluation is a two-stage VLM fine-tuning process. The first stage involves score calibration, where the model is trained on a pointwise dataset to generate both a detailed CoT rationale and the final absolute score. The model learns to autoregressively produce the rationale followed by the score, with optimal parameters obtained by minimizing a cross-entropy loss. The second stage involves a progressive, three-tiered calibration mechanism to align the model with human expert criteria. This includes prompt-level calibration, where abstract evaluation dimensions are replaced with more perceptually grounded ones; fusion-level calibration, which employs a lightweight MLP to optimize weights for different evidence sources and reasoning components; and parameter-level calibration, where fine-tuning injects cinematic domain knowledge directly into the model's parameters.
The machine evaluation pipeline operates in two steps. First, a suite of specialized operators extracts deterministic, objective evidence from the input video, audio, text prompt, and reference. These operators, including DINO for cross-frame identity tracking, YOLO for semantic anchoring, SyncNet for audio-visual synchronization, and Whisper for speech emotion recognition, provide a perception prior that mitigates hallucinations and ensures reliable contextual grounding. As shown in the figure below, this evidence is then fed into the fine-tuned VLM, which performs expert-guided chain-of-thought reasoning.

The VLM, denoted as Mθ∗, processes the multi-modal context, which includes the extracted evidence, the text prompt, the reference, and a set of expert-designed multi-questions for a specific cinematic dimension. Instead of producing a direct score, the model generates a detailed CoT, which includes a self-reflection mechanism to re-examine its own reasoning for potential hallucinations. A context-aware gating mechanism dynamically bypasses certain metrics if the narrative context does not warrant them. The final score for a dimension is computed by combining the VLM's output with this gating indicator. This approach ensures that the evaluation is not only accurate but also transparent and interpretable, providing a clear rationale for the final judgment.
Experiment
The evaluation framework assesses video generation models across pre-production asset logic, post-production multi-shot sequencing, and affective storytelling through a rigorous three-stage human expert pipeline alongside automated benchmarking. This comprehensive testing validates how effectively models preserve visual concepts, maintain cinematic aesthetics, and synchronize audio-visual elements across different generation settings. Qualitative analysis reveals a clear performance hierarchy where leading models consistently excel in cinematography, emotional progression, and multimodal coherence, while others demonstrate specialized strengths or notable gaps in complex narrative and sound design. Alignment experiments further confirm that the automated evaluation system closely mirrors professional human judgment, demonstrating that parameter-level calibration is essential for accurately assessing abstract and temporally entangled cinematic criteria.
The authors evaluate the alignment between automated metrics and human expert judgments across various video generation models and evaluation dimensions. Results show strong correlation between automated predictions and human preferences, particularly for dimensions grounded in visual and cinematic criteria, with higher agreement observed for abstract and temporally complex dimensions after task-specific calibration. Automated metrics show strong alignment with human expert evaluations across multiple video generation dimensions. Higher correlation is observed for abstract and temporally entangled dimensions after task-specific calibration. Pixel-grounded dimensions achieve strong alignment with human judgments, indicating reliable performance of prompt-level reasoning.
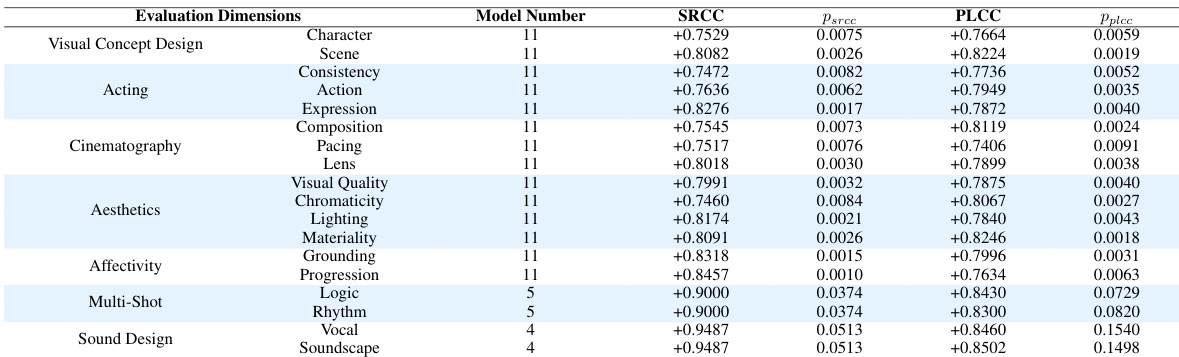
The authors evaluate various video generation models using a comprehensive benchmarking framework that assesses multiple dimensions of video quality, including visual design, emotional resonance, and post-production coherence. The framework, EvalVerse, is designed to align with human expert evaluations through a calibrated pipeline, achieving high consistency with professional judgments across different modalities and evaluation criteria. EvalVerse demonstrates high alignment with human expert evaluations across various video generation models and evaluation dimensions. The benchmarking framework covers diverse task modalities, including text-to-video, reference-to-video, video with sound, and multi-shot sequences. EvalVerse achieves high interpretability and expert-guided evaluation, with strong performance in both pixel-grounded and abstract, temporally-entangled dimensions.
The authors evaluate the alignment between automated model predictions and human expert judgments across various video generation dimensions. The results show strong correlation between automated and human evaluations, particularly for dimensions that are grounded in visual content and those further refined with task-specific calibration. This indicates that the evaluation framework effectively captures human preferences, with higher agreement observed for both pixel-based and abstract, temporally complex attributes after calibration. Automated predictions closely align with human expert judgments across all evaluated dimensions. Dimensions grounded in visual content show strong alignment, indicating reliable performance of prompt-level reasoning. Abstract and temporally complex attributes achieve the highest agreement after task-specific calibration.
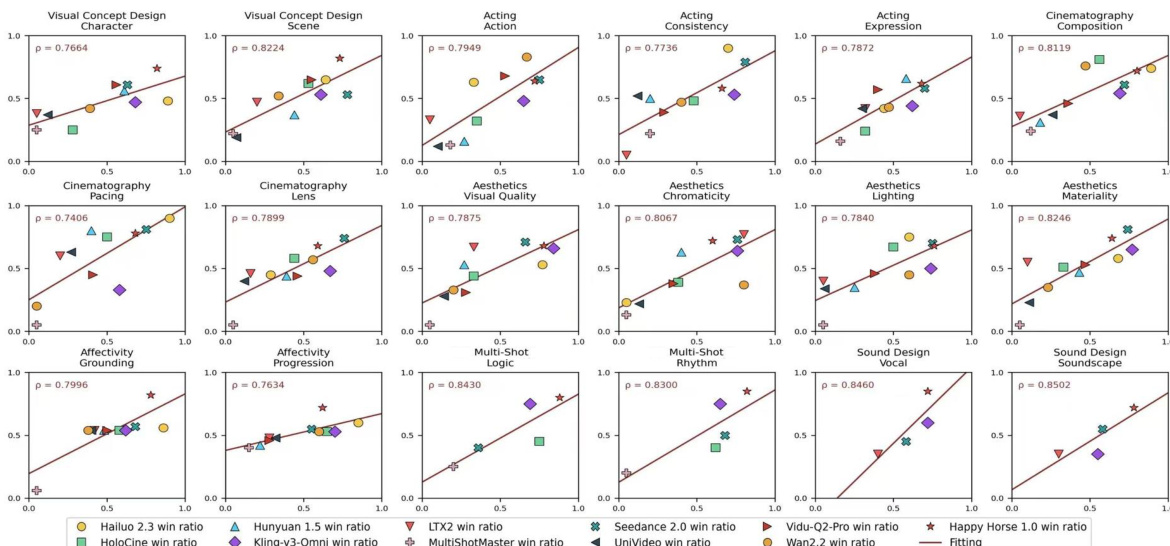
The authors evaluate a range of video generation models across multiple dimensions spanning pre-production, production, and post-production stages, using a multi-stage human evaluation protocol and an automated evaluation framework. Results show that the leading models exhibit strong performance in visual and cinematic aspects, while differences emerge in affectivity and sound-related dimensions, with the evaluation framework demonstrating high alignment with human expert judgments. Seedance 2.0 achieves the highest overall performance across most evaluation dimensions, particularly in aesthetics, cinematography, and sound-related criteria. Models exhibit varying strengths across different aspects, with some excelling in visual and camera control while showing weaknesses in affectivity and audio-visual synchronization. The automated evaluation framework shows strong alignment with human expert preferences, especially for dimensions grounded in visual and cinematic attributes, and further improves for abstract and temporally complex aspects through task-specific calibration.

The authors evaluate multiple video generation models across various cinematic dimensions, including visual design, affectivity, and sound design, using a multi-stage human evaluation protocol. Results show a clear hierarchy among models, with some demonstrating strong overall performance and others showing specialized strengths or weaknesses in specific areas. Seedance 2.0 achieves the highest overall performance across most evaluation dimensions. Kling-v3-Omni and Happy Horse 1.0 show strong and consistent results in visual and cinematic aspects, with varying strengths in sound-related and affective dimensions. Models exhibit uneven performance profiles, with some excelling in specific areas like visual consistency or cinematography while lagging in others such as affectivity or audio-visual synchronization.
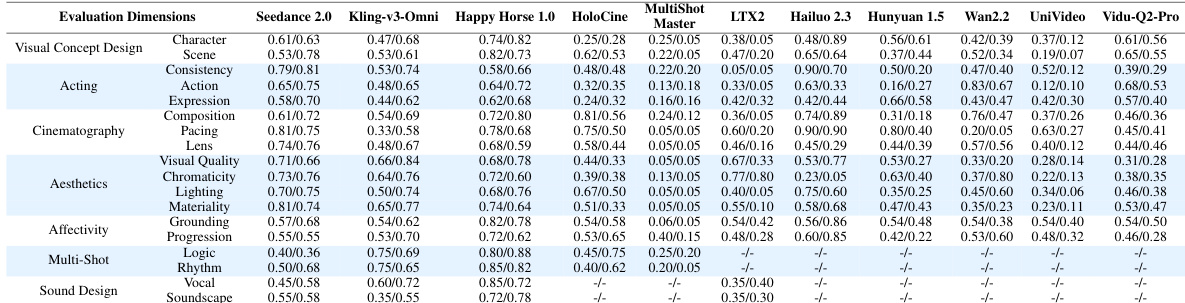
The evaluation employs a comprehensive benchmarking framework paired with a multi-stage human assessment protocol to compare state-of-the-art video generation models across diverse modalities and cinematic dimensions. This experimental setup validates the alignment between automated scoring systems and professional human judgments while establishing a performance hierarchy among competing models. Qualitative results indicate that automated metrics reliably capture human preferences, particularly for visual and cinematic attributes, with task-specific calibration further strengthening agreement on abstract and temporally complex criteria. Overall, model capabilities reveal distinct specializations, with leading systems excelling in aesthetics and cinematography while demonstrating uneven strengths in emotional resonance and audio-visual synchronization.