Command Palette
Search for a command to run...
SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
Abstract
While spatial foundation models have demonstrated impressive performance on standard datasets, a critical question remains: are they truly all-round players capable of generalizing robustly across diverse downstream tasks, arbitrary viewpoints, shifting scene domains, varying input densities, and specific hardware constraints? Answering this overarching question requires a holistic assessment, yet current models are mainly evaluated on specific domains for which they were specifically designed or trained. Such evaluations are intrinsically limited by narrow paradigm coverage, limited scene domains, and arbitrary frame sampling, making it fundamentally difficult to assess their true generalization capabilities. To address this gap, we present SpatialBench, a cross-paradigm, domain-diverse benchmark for spatial foundation models with deterministic sampling. SpatialBench features unprecedented scale and rigorous deterministic design, comprising 19 datasets and 546 scenes across 5 diverse spatial domains. It comprehensively evaluates 41 models across 6 paradigms on 5 task suites under 4 different input density settings. Our extensive evaluation reveals that current models are not yet all-round players, and uncovers crucial insights for future advancement. Specifically, we demonstrate that full-context attention maximizes accuracy while bounded-memory strategies unlock long-sequence scalability. Moreover, our empirical evaluations in challenging embodied and egocentric tasks demonstrate that strict domain alignment and high data quality are far more critical to performance than simple dataset scaling. Furthermore, to address the largest data gap identified in our analysis, we go beyond evaluation by introducing a large-scale dataset, DA-Next-5M, and a strong baseline model, DA-Next, pushing the boundaries of spatial representation learning.
One-sentence Summary
SpatialBench introduces a holistic benchmark that evaluates spatial foundation models across diverse downstream tasks, arbitrary viewpoints, shifting scene domains, varying input densities, and specific hardware constraints to assess their robust generalization beyond standard datasets.
Key Contributions
- SpatialBench provides a deterministic, tag-aware evaluation framework that enables systematic cross-paradigm comparisons across diverse input densities, viewpoint types, and scene dynamics. This standalone benchmark establishes a unified protocol for assessing spatial foundation models where prior model-specific suites lack controlled evaluation standards.
- Extensive experiments across 41 models and six paradigms reveal that current spatial foundation models lack robust generalization under shifting domains and varying input densities. These results identify critical performance gaps in domain adaptation and input-density resilience that limit consistent performance in realistic video streams.
- To address identified data scarcity in challenging perspectives, the work introduces DA-Next-5M, a large-scale dataset curated for egocentric and wrist-view sequences. A corresponding baseline model trained on this collection establishes a strong reference point for future improvements in scalable memory management and long-range geometric alignment.
Introduction
Spatial foundation models have emerged as critical backbones for robotics, autonomous driving, and AR/VR applications by enabling accurate 3D scene reconstruction from standard 2D images. Despite their widespread adoption, real-world deployment demands robust performance across unpredictable domain shifts, highly variable input densities, and strict hardware constraints. Prior evaluation efforts fall short because they typically isolate specific model paradigms, rely on inconsistent sampling protocols, and rarely test how systems scale under dense visual streams or memory limits. To bridge this gap, the authors present SpatialBench, a standardized, cross-paradigm benchmark that systematically evaluates forty-one models across six architectural families, nineteen datasets, and four deterministic density regimes. By establishing a unified evaluation protocol, this work exposes fundamental trade-offs between accuracy and scalability while introducing the DA-Next-5M dataset and DA-Next baseline to address critical egocentric perception gaps, ultimately steering the field toward more generalizable spatial intelligence.
Dataset
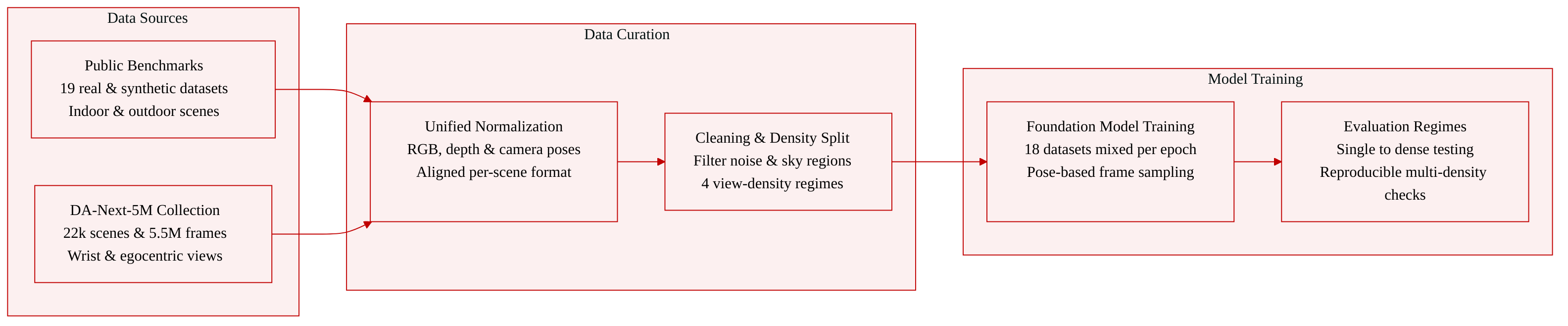
-
Dataset Composition and Sources
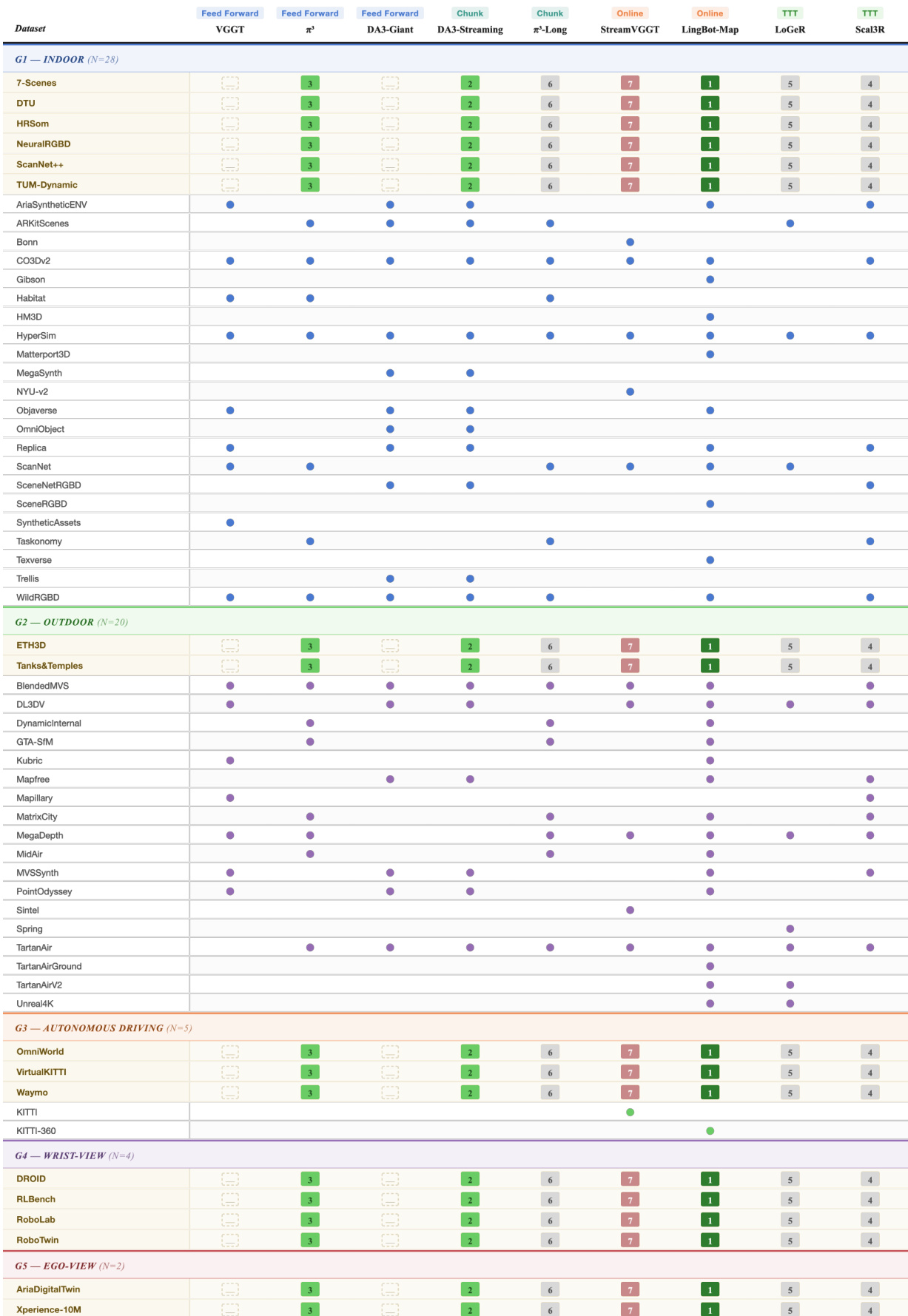
- The authors aggregate 19 publicly available real-world and synthetic datasets into SpatialBench, covering 546 scenes and 72,540 evaluation frames across indoor and outdoor environments.
- The collection spans static and dynamic content, captured from normal, egocentric, and wrist-mounted viewpoints.
- A dedicated Single-frame Mixture combines Lingbot-Depth with all benchmark datasets to support monocular depth evaluation.
- The companion DA-Next-5M dataset comprises 22,000 scenes and 5.5 million frames focused on egocentric and wrist perspectives, sourced from real-world captures and robotics simulators including RLbench, Robo Colosseum, RoboTwin, and Robolab.
-
Key Details for Each Subset
- Static-real subsets include 7-Scenes, DTU, NRGBD, Scannet++, Tanks & Temples, and ETH3D for high-quality ground-truth geometry.
- Dynamic-real subsets feature TUM-Dynamic, DROID, Xperience, Waymo, and KITTI-Odometry for indoor activities and street-scale driving scenarios.
- Dynamic-synthetic subsets comprise ADT, RLBench with Colosseum, RoboTwin, Robolab, Virtual KITTI 2, and OmniWorld-Game, leveraging domain randomization for backgrounds, object properties, and camera placements.
- The DROID subset undergoes rigorous curation using stereo depth estimation (S²M²), confidence thresholding, initial pose estimation (MapAnything), dynamic object masking (SAM3), and bundle adjustment to ensure temporal depth consistency.
- The Xperience subset utilizes VIPE-based SLAM for poses and FoundationStereo for metric depth estimation, while simulation datasets are resized to 1280x720 or 512x512 resolutions with adjusted camera extrinsics to capture gripper interactions.
-
Data Usage and Training Configuration
- For evaluation, the authors structure each scene across four deterministic view-density regimes: SINGLE (fixed frame), SPARSE (voxel set-cover for viewpoint diversity), MEDIUM (overlap-favored set-cover), and DENSE (long-horizon temporal continuity with a max frame budget).
- For training the DA-Next foundation model, the authors combine 18 datasets including DA-Next-5M, HyperSim, Infinigen, Spring, MapFree, Matterport 3D, MVS-Synth, ScanNet++, TartanAir, Unreal 4K, Virtual KITTI, and Waymo.
- Training employs a fixed mixture ratio sampled per epoch, with each batch containing exactly 18 frames drawn from 2 to 18 random scenes.
- Frame selection relies on Euclidean camera pose distance, ranking frames around a randomly chosen anchor and sampling from its closest valid range to maintain spatial coherence.
-
Processing and Metadata Construction
- All raw datasets are normalized into a unified per-scene representation containing RGB frames, metric depth maps, camera intrinsics, and camera-to-world poses.
- Evaluation inputs are decoupled from data ingestion via JSON records that specify exact frame indices for each scene and density regime, guaranteeing reproducible multi-density sampling.
- A unified five-stage depth cleaning pipeline applies range clipping, flying point removal, edge-aware bilateral filtering, small isolated region removal, and semantic sky masking to filter unreliable pixels.
- Simulation data incorporates extensive domain randomization, while wrist-view sequences are filtered by computing per-pixel reprojection depth error to remove sequences with poor temporal consistency.
Method
The authors leverage a transformer-based architecture for their model, DA-Next, which is built upon the Giant variant of Depth-Anything-3. The framework processes a sequence of input images, denoted as I={Ii}i=1N, and optionally incorporates camera parameters, C={Ci}i=1N={Ki,Gi}i=1N, where Ki is the intrinsic matrix and Gi is the extrinsic pose. The model's architecture is designed to jointly predict depth maps, ray maps, and a global scale factor, enabling the reconstruction of metric-scale 3D point clouds.
The overall process begins by patchifying the input frames into patch tokens, ef. These are then concatenated with camera tokens, ec, and scale tokens, es, forming a unified sequence of tokens that is processed by a transformer encoder, E. The camera tokens are either derived from the ground-truth camera information when available, or they are learnable parameters. The transformer encoder is composed of L layers, which alternate between frame-wise self-attention and global self-attention blocks, allowing the model to capture both local and global dependencies within the scene. As shown in the figure below, the output of the encoder, (e^c,e^s,e^f), is then used to generate the final predictions. The patch tokens, e^f, and camera tokens, e^c, are fed into a Dual-DPT head to produce the depth map, D^, and ray map, R^, predictions. Concurrently, the scale tokens, e^s, are processed by a lightweight multi-layer perceptron (MLP) to regress a scalar scale factor, S^. The predicted depth and ray maps, along with the scale factor, are subsequently used to reconstruct the scene's point cloud.
Experiment
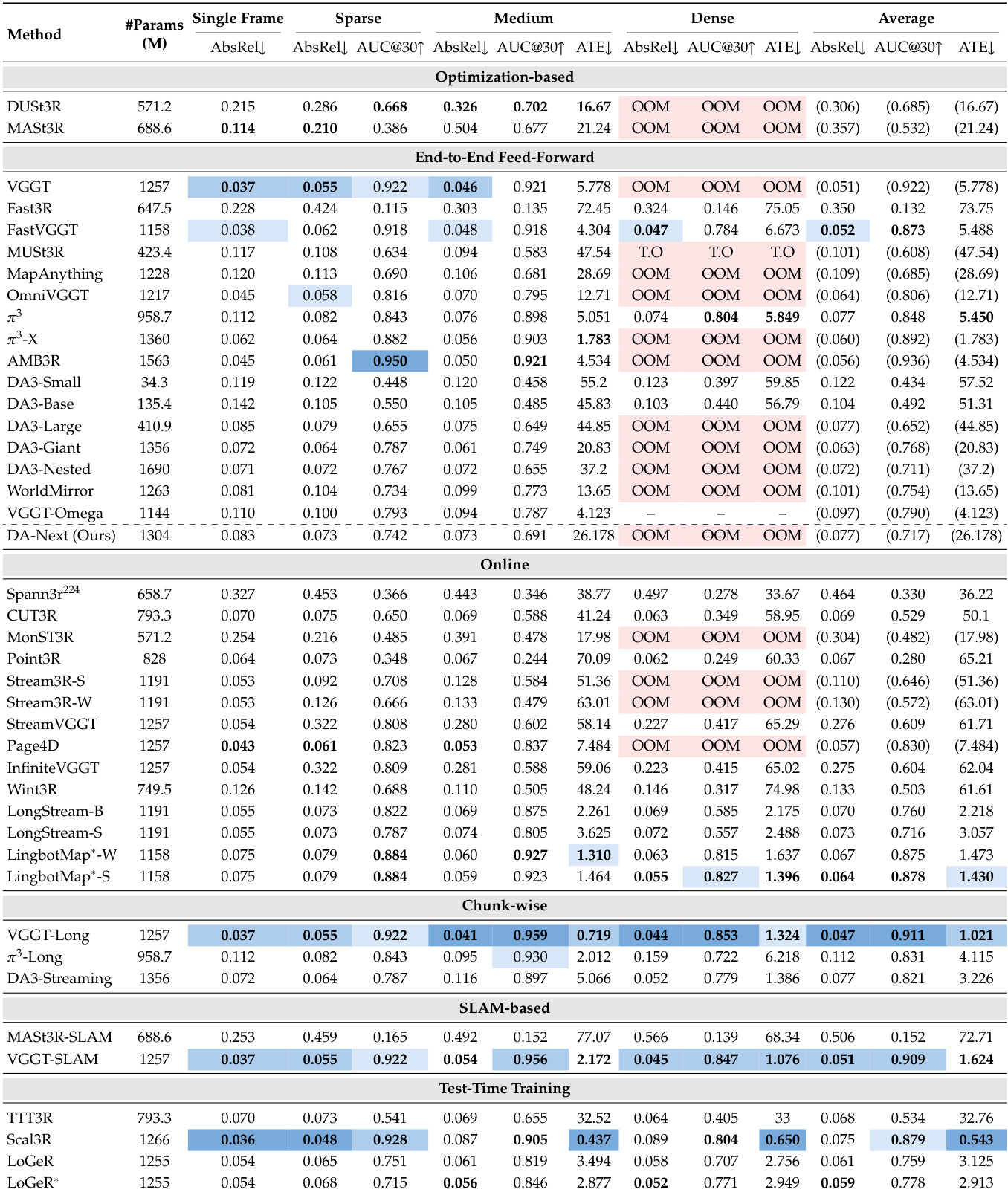
The evaluation benchmarks 41 model variants across six architectural paradigms on spatial reconstruction tasks, validating performance across varying input densities, hardware constraints, and auxiliary prior injections. Qualitative analysis reveals that full-context attention models achieve peak geometric accuracy but are constrained by memory limits, whereas bounded-memory and test-time training approaches successfully trade precision for scalability in long-horizon scenarios. The experiments further demonstrate that training data quality and domain diversity critically dictate generalization, with targeted curation of underrepresented viewpoints substantially closing performance gaps. Ultimately, the findings indicate that optimal spatial foundation models require balancing architectural efficiency with carefully curated, domain-specific data rather than relying solely on increased dataset volume or input density.
The experiment evaluates 41 model variants across six paradigms on SpatialBench, assessing performance across single-frame, sparse, medium, and dense input settings. Full-context feed-forward models achieve the highest accuracy under memory constraints, while streaming and online methods enable long-sequence reconstruction with bounded memory, albeit at the cost of lower depth estimation accuracy. Training data quality, particularly in-domain coverage, strongly influences model performance across different domains. Full-context feed-forward models achieve the highest accuracy under memory constraints, outperforming streaming and online methods in reconstruction quality. Streaming and online methods enable long-sequence reconstruction with bounded memory, but their depth estimation accuracy remains below that of full-context models. Model performance is strongly influenced by training data quality and domain coverage, with in-domain data leading to better results across various tasks and settings.
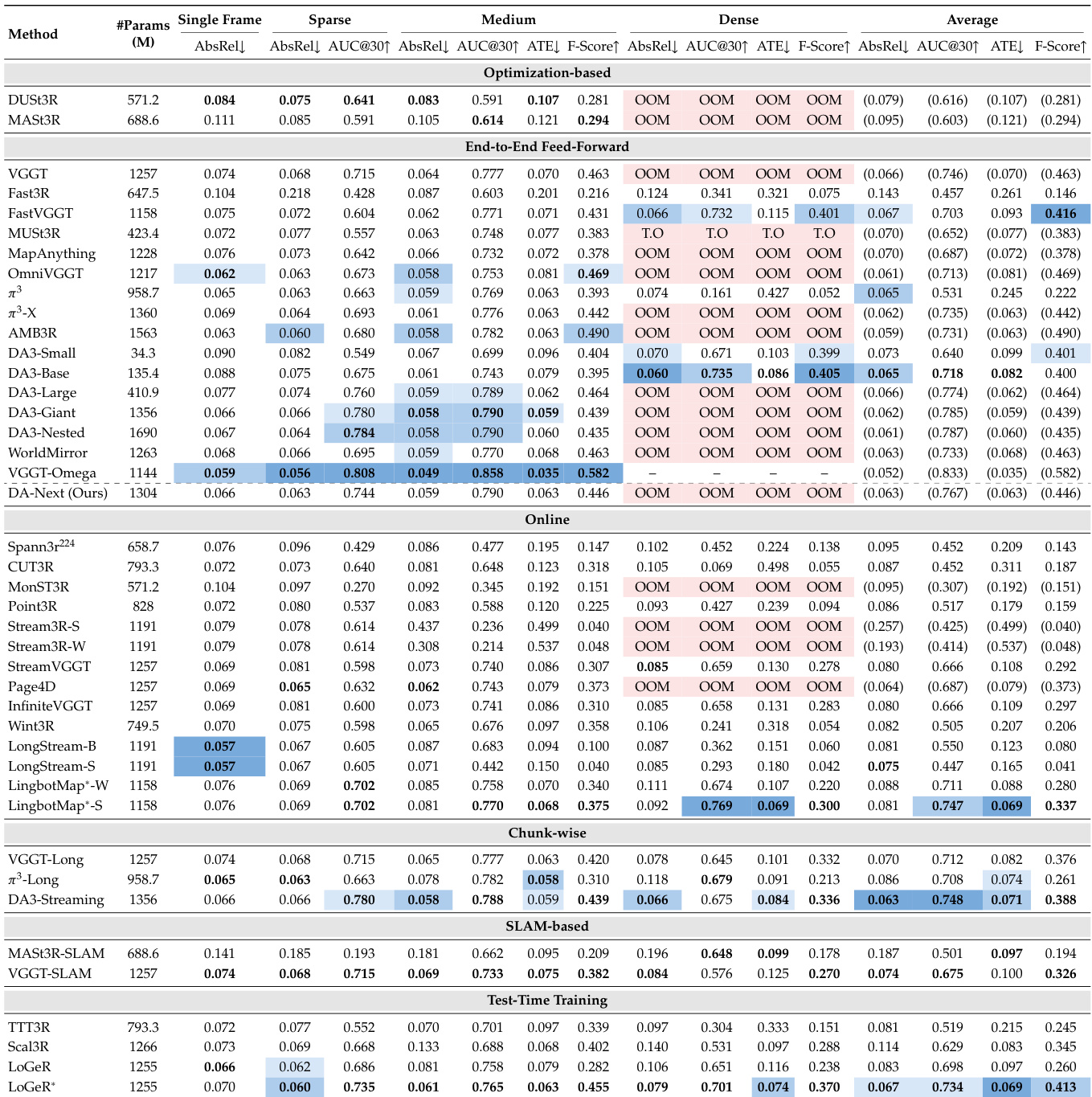
The experiment evaluates 41 model variants across six reconstruction paradigms on SpatialBench, assessing performance across single-frame, sparse, medium, and dense input settings. Results show that full-context feed-forward models achieve the highest accuracy, particularly in depth and camera pose estimation, while bounded-memory models offer scalability at the cost of accuracy. The best-performing methods vary by input regime and domain, with training data coverage being a strong predictor of per-domain performance. Full-context feed-forward models achieve the highest accuracy across most metrics, particularly in depth and camera pose estimation, but often fail on dense inputs due to memory constraints. Bounded-memory models, such as streaming and chunk-wise methods, maintain scalability under long sequences but show lower reconstruction accuracy compared to full-context models. Training data domain coverage is a stronger predictor of performance than model architecture or dataset volume, with models trained on in-domain data outperforming others in their respective domains.
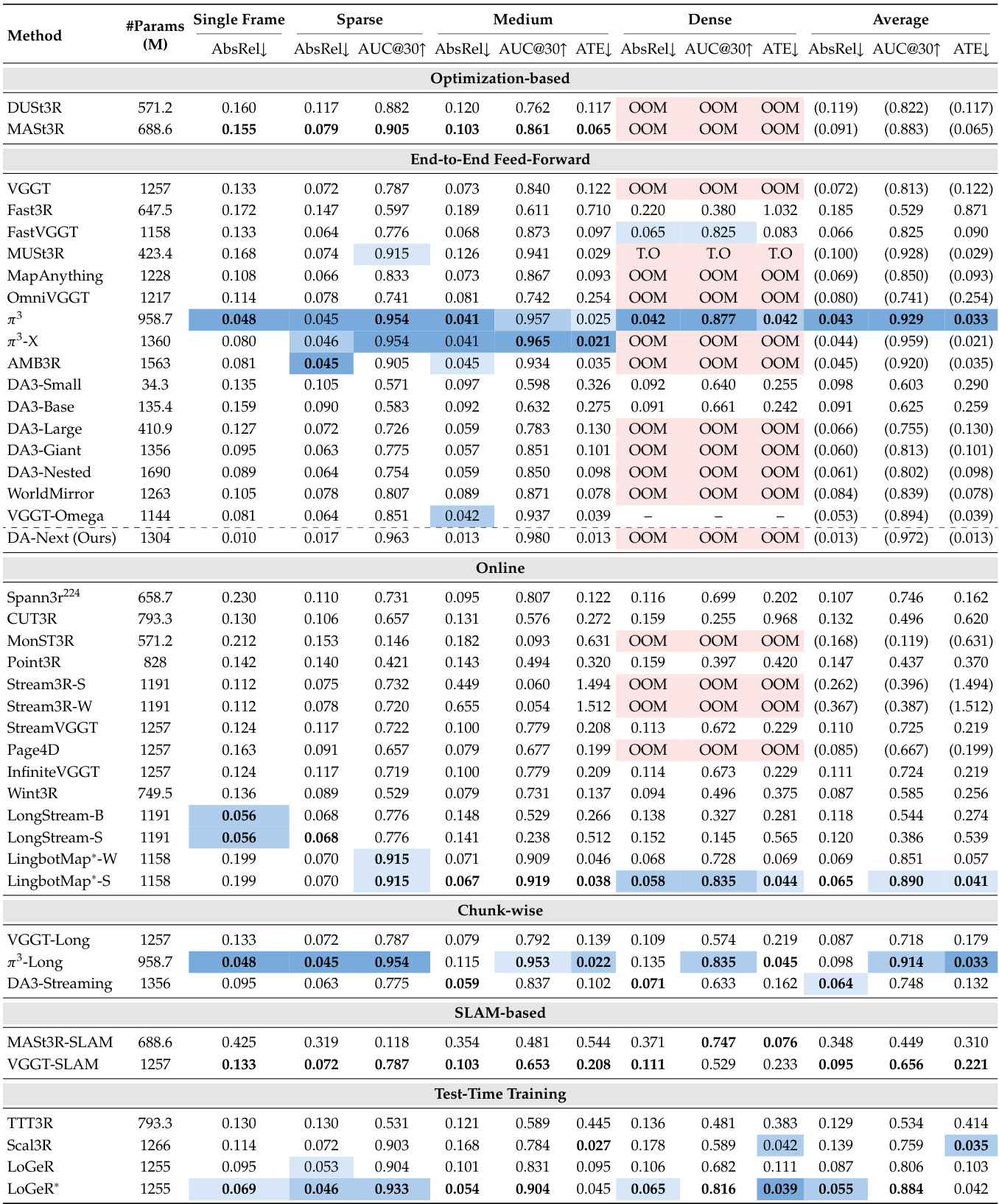
The the the table presents a comparison of various spatial foundation models across multiple datasets grouped by domain, evaluating their performance in terms of reconstruction quality. Models are categorized by their architectural paradigms, such as feed-forward, chunk-based, online, and test-time training, with results indicating that different models excel in different domains and input settings. The evaluation highlights that models trained on in-domain data tend to perform better, and the choice of model depends on the specific application requirements and input density. Different models perform best in different domains, with in-domain training data being a key factor in performance. Feed-forward models generally achieve higher accuracy but are limited by memory constraints on long sequences. The performance of models varies significantly across input settings, with dense inputs not always leading to better results due to redundancy.
The experiment evaluates 41 model variants across six paradigms on SpatialBench, assessing performance across single-frame, sparse, medium, and dense input settings. Results show that full-context feed-forward models achieve the highest accuracy, particularly in depth and camera pose estimation, while streaming and chunk-wise methods offer better scalability on limited hardware despite lower accuracy. The best-performing models vary by input regime and domain, with training data coverage being a key factor in domain-specific performance. Full-context feed-forward models achieve the highest accuracy across most metrics, particularly in depth and camera pose estimation, but are limited by high memory usage. Streaming and chunk-wise models trade accuracy for scalability, enabling long-sequence reconstruction on limited hardware. Model performance varies significantly across input regimes and domains, with training data coverage being a more decisive factor than dataset volume for domain-specific success.
The experiment evaluates 41 model variants across six paradigms on SpatialBench, assessing performance across single-frame, sparse, medium, and dense input settings. Results show that full-context feed-forward models achieve the highest accuracy, particularly on bounded inputs, while streaming and online methods enable long-sequence reconstruction under memory constraints, though with lower depth accuracy. Model performance varies significantly across domains, with training data coverage being a key predictor of success in specific environments. Full-context feed-forward models achieve the highest accuracy on bounded inputs, outperforming streaming and online methods in reconstruction quality. Streaming and online models enable long-sequence reconstruction under memory constraints but trade off depth accuracy for scalability. Model performance across domains is highly dependent on training data coverage, with in-domain data being a stronger predictor of success than dataset volume.
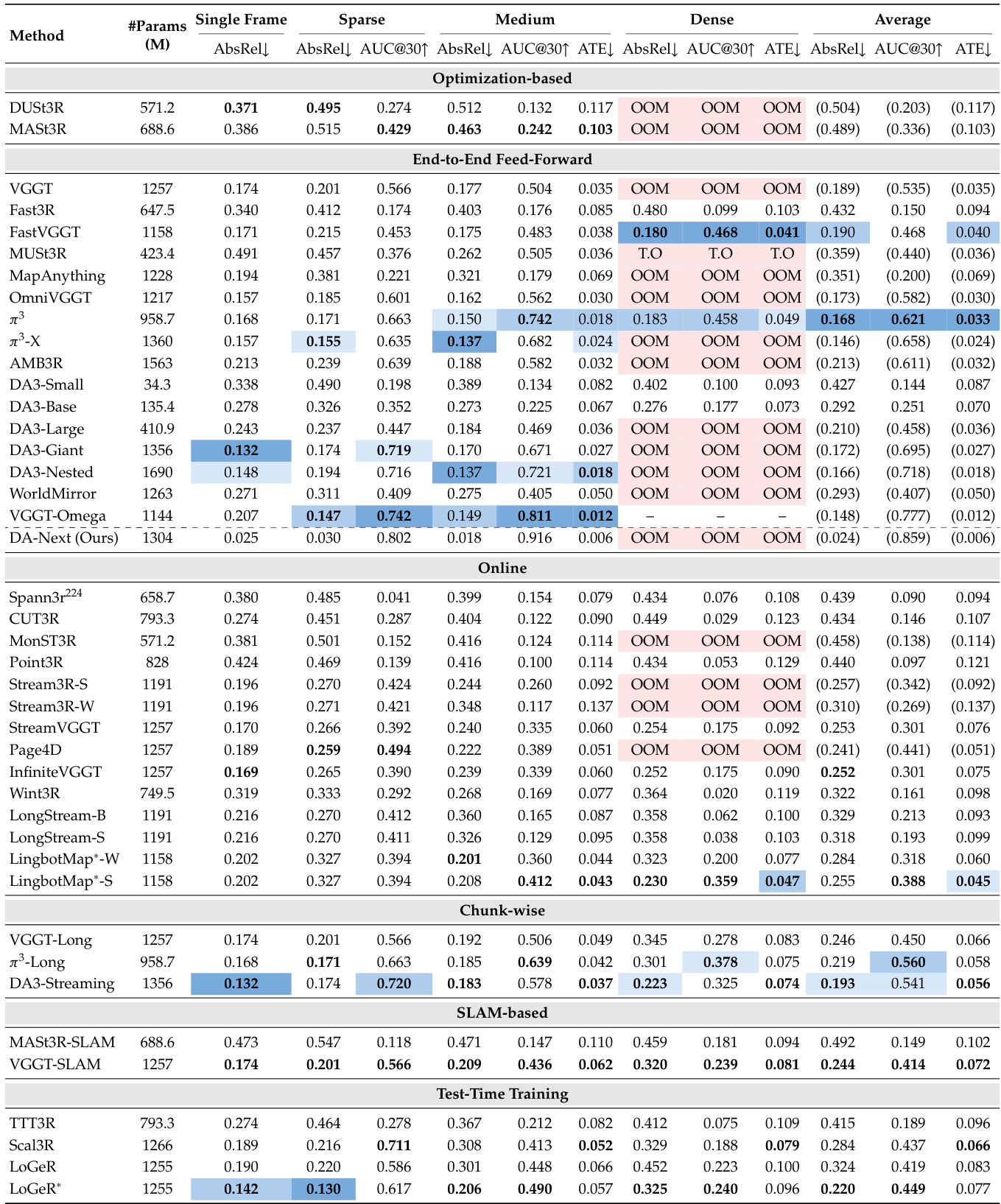
The evaluation assesses forty-one model variants across six reconstruction paradigms on SpatialBench, validating how different architectural approaches balance reconstruction accuracy against memory constraints across varying input densities. Results demonstrate that full-context feed-forward models deliver superior precision but struggle with long sequences, while streaming and chunk-based methods sacrifice accuracy to enable scalable, bounded-memory processing. Across all settings, performance is primarily dictated by in-domain training data coverage rather than model architecture or dataset size, underscoring the necessity of domain-aligned training for optimal results.