Command Palette
Search for a command to run...
LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
Nianyi Lin Jiajie Zhang Lei Hou Juanzi Li
Abstract
Long-context reasoning remains a central challenge for large language models, which often fail to locate and integrate key information in extensive distracting content. Reinforcement learning with verifiable rewards (RLVR) has shown promise for this task, yet existing methods are limited by low-confusability distractors and sparse, outcome-only reward signals that cannot supervise intermediate reasoning steps. To address these issues, we introduce LongTraceRL. For data construction, we generate multi-hop questions via knowledge graph random walks and leverage search agent trajectories to build tiered distractors: documents the agent read but did not cite (high confusability) and documents that appeared in search results but were never opened (low confusability), producing training contexts that are far more challenging than those built by random sampling or one-shot search. For reward design, we propose a rubric reward that uses the gold entities along each reasoning chain as fine-grained, entity-level process supervision. This rubric reward is applied only to responses with correct final answers (positive-only strategy), distinguishing the reasoning quality among correct responses and preventing reward hacking. Experiments on three reasoning LLMs (4B--30B) across five long-context benchmarks demonstrate that LongTraceRL consistently outperforms strong baselines and encourages comprehensive, evidence-grounded reasoning. Codes, datasets and models are available at https://github.com/THU-KEG/LongTraceRL{https://github.com/THU-KEG/LongTraceRL}.
One-sentence Summary
LongTraceRL advances long-context reasoning by leveraging search agent trajectories to construct tiered distractors and deploying a rubric reward for fine-grained, entity-level process supervision, thereby overcoming the sparse outcome-only signals and low-confusability distractors that limit prior reinforcement learning methods.
Key Contributions
- A long-context training data construction method generates multi-hop questions via knowledge graph random walks and builds tiered distractors from real search agent trajectories. This approach replaces random sampling with semantically relevant documents to substantially increase training challenge.
- An entity-level rubric reward provides fine-grained process supervision by tracking gold entities along each reasoning hop. Applied exclusively to responses with correct final answers, this positive-only strategy distinguishes reasoning quality among successful outputs and prevents reward hacking.
- Evaluations across five long-context benchmarks and three model families ranging from 4B to 30B parameters demonstrate consistent improvements over existing baselines. The approach yields a 5.7-point average gain for Qwen3-4B over its base version and surpasses the strongest baseline by 2.5 points.
Introduction
Long-context reasoning is essential for large language models to extract relevant information, perform multi-hop inference, and maintain coherence across extended documents, yet it remains a critical bottleneck for deploying reasoning-capable AI in real-world applications. Prior reinforcement learning approaches with verifiable rewards struggle with shallow training data that relies on randomly sampled, semantically irrelevant distractors, alongside sparse outcome-only rewards that fail to supervise intermediate reasoning steps and allow models to succeed by chance. To overcome these hurdles, the authors leverage search agent trajectories to construct tiered, high-confusability distractors and introduce a rubric reward that provides fine-grained, entity-level process supervision along each reasoning hop. This dual approach trains models to distinguish relevant evidence more effectively and prevents reward hacking, consistently improving long-context reasoning performance across multiple model scales and benchmarks.
Dataset

-
Dataset Composition and Sources
- The authors construct the dataset using the KILT Wikipedia snapshot as the sole knowledge source. The pipeline leverages knowledge graph structures to generate multi-hop questions with verifiable reasoning chains, while agent search behavior provides realistic distractors.
-
Key Details for Each Subset
- Multi-hop question generation: The authors perform controlled random walks of eight steps over the Wikipedia hyperlink graph. An LLM selects the next entity from up to five unvisited candidates at each step, with periodic random jumps to diversify graph exploration.
- Question synthesis: A powerful LLM generates questions that require step-by-step reasoning through all path entities. The prompts enforce paraphrased identifiers, unique attribute-based answers, and explicit intermediate gold entities.
- Search trajectory collection: A deep-search agent logs actions such as searching, opening documents, and citing information. The authors sample five independent trajectories per question, retaining only correct paths and discarding questions where all attempts fail.
- Distractor tiers: Retrieved documents are categorized into Tier-1 distractors, which the agent opened but did not cite, and Tier-2 distractors, which appeared in search results but were never opened.
-
Data Usage and Processing
- Training application: The authors use this dataset to train long-context reinforcement learning models, specifically enabling entity-level reasoning supervision over large inputs.
- Context assembly: The authors apply a traj-tiered strategy that prioritizes Tier-1 distractors to maximize challenge, then fills remaining context space with Tier-2 distractors until a target length is reached. All documents are shuffled to prevent positional shortcuts.
- Filtering rules: Only trajectories demonstrating goal-directed search behavior are kept. Questions that yield no correct trajectory across five attempts are removed from the final collection. The text does not specify fixed train-validation splits or static mixture ratios, relying instead on the dynamic traj-tiered assembly process.
-
Metadata Construction and Additional Details
- Metadata generation: Each sample includes the question text, ground-truth answer, a set of gold entities with their corresponding Wikipedia passages, and the complete agent trajectory log.
- Processing constraints: The dataset relies entirely on encyclopedic knowledge, which may limit reasoning diversity. The quality and difficulty of distractors depend directly on the capabilities of the deployed search agent.
Method
The LongTraceRL framework consists of two primary components: a data construction pipeline and a reinforcement learning framework. The data construction pipeline generates long-context training data by synthesizing agent-derived distractors, while the reinforcement learning framework integrates both outcome-based and process-based rewards to guide model training.
The data construction process begins with a multi-hop question generation step, where a path of entities is derived from a random walk on a knowledge graph, such as Wikipedia. Each node in the path represents an entity with associated descriptions, and the task is to construct a multi-hop question that requires step-by-step reasoning to reach the final answer, which corresponds to an attribute of the last node in the path. As shown in the figure below, the generated question must be concise, include up to twice the number of unique clues as entities, and ensure that the answer is uniquely determined by the reasoning chain.

The framework then proceeds to collect agent search trajectories by simulating an agent that performs a sequence of search and open operations to answer the generated question. This process yields a path with gold entities and documents, forming the basis for the training data. The trajectories are further processed through tiered distractor extraction, where documents are categorized based on their relevance and citation status. This includes identifying gold documents that are cited in the reasoning chain, tier-1 documents that are opened but not cited, and tier-2 documents that are searched but not opened, all of which are used to build a challenging long-context assembly.
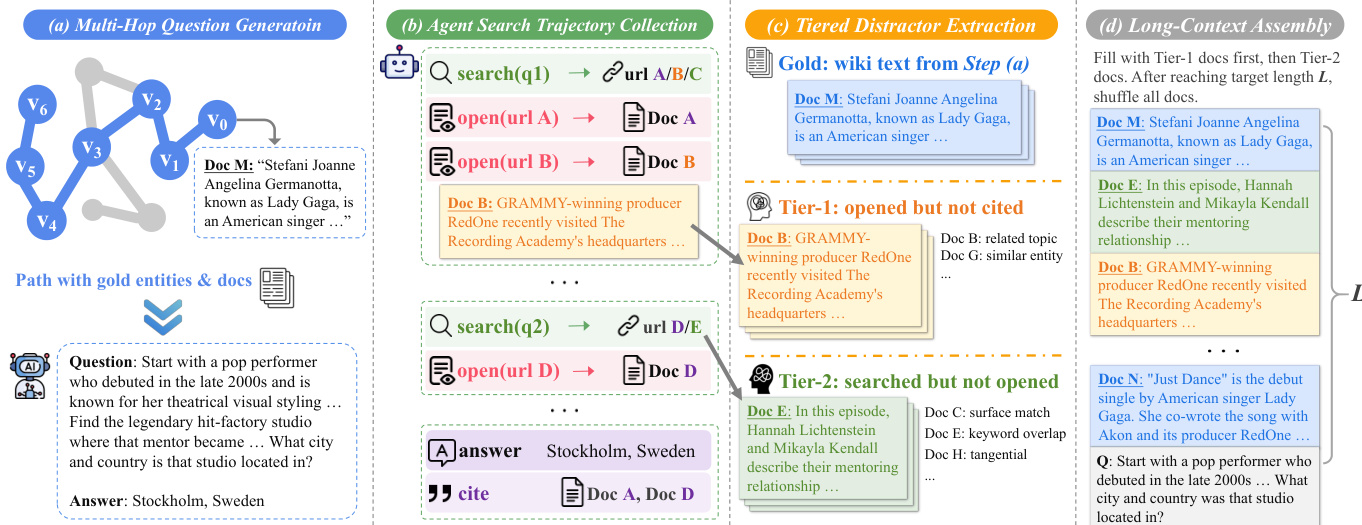
In the reinforcement learning phase, the framework employs Group Relative Policy Optimization (GRPO) as the underlying algorithm. The reward function is designed as a composite of an outcome reward and a rubric reward. The outcome reward is binary, evaluating whether the model's final answer is correct, as determined by an LLM judge. The rubric reward measures the recall of gold entities in the model's response, calculated as the ratio of gold entities present in the response to the total number of gold entities.

To ensure comparability across different questions, the raw rubric score is normalized within each group of responses by dividing it by the maximum raw rubric score in the group, rescaling the reward to a [0, 1] range. A positive-only reward strategy is applied to prevent reward hacking, where the rubric reward is only granted to responses with correct final answers. The final reward is a weighted combination of the outcome and normalized rubric rewards, where the hyperparameter α controls the balance between outcome and process supervision. This design enables the model to be incentivized to produce high-quality reasoning that is grounded in the relevant evidence.
Experiment
The evaluation tests the proposed long-context reinforcement learning method across multiple model families and five reasoning benchmarks, comparing it against established baselines and systematic ablations to isolate the impact of key training components. Results demonstrate that the approach consistently enhances multi-hop reasoning and contextual grounding, primarily driven by a rubric reward that encourages deliberate, entity-aligned thinking. Further validation confirms that carefully curated trajectory-based distractors and a positive-only reward constraint are essential for maintaining training stability and preventing shortcut-taking behaviors. Ultimately, the method fosters deeper contextual comprehension by forcing models to resolve conflicting cues, disambiguate references, and strictly adhere to nuanced question constraints.
The authors evaluate the performance of LONGTRACERL across multiple long-context reasoning benchmarks using different model sizes and configurations. Results show that incorporating a rubric reward component significantly improves performance, particularly on challenging benchmarks, and that the effectiveness of the method is sensitive to the weight of the rubric reward. The best results are achieved with a balanced reward configuration, while removing the positive-only strategy or using weaker distractor designs leads to performance degradation. The method achieves consistent improvements across all benchmarks when a rubric reward is included, with the strongest gains observed on the most challenging AA-LCR benchmark. The performance is sensitive to the weight of the rubric reward, with an intermediate value yielding the best overall results and higher or lower values leading to degradation. Removing the positive-only reward strategy results in a clear performance drop, especially on reasoning-intensive tasks, indicating its role in preventing reward hacking.

The authors compare different distractor strategies for training long-context reasoning models, focusing on how the confusability of distractors affects model performance. The traj-tiered strategy, which generates distractors based on a multi-tiered trajectory, produces the highest overlap with rubric entities and leads to the best overall performance. In contrast, random and search-based distractors show significantly lower entity overlap and result in poorer performance. The results indicate that more challenging distractors, particularly those closely aligned with the reasoning path, improve model learning. The traj-tiered distractor strategy achieves the highest overlap with rubric entities and the best performance on downstream benchmarks. Random and search-based distractors exhibit low entity overlap with the reasoning path, leading to weaker training signals and lower model performance. Distractor confusability, measured by entity recall, strongly correlates with downstream performance, highlighting its importance in training data quality.
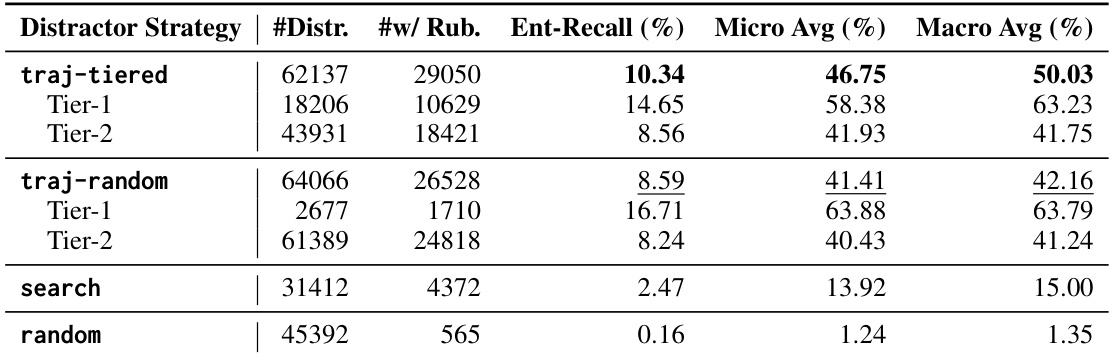
The authors evaluate the performance of LONGTRACERL across multiple long-context reasoning benchmarks using different distractor strategies. Results show that the trajectory-tiered distractor method achieves the highest average score, outperforming random, search-based, and trajectory-random alternatives, particularly on the AA-LCR benchmark. The method consistently improves upon the base model and other baselines across all evaluated benchmarks. The trajectory-tiered distractor strategy achieves the highest average performance across all benchmarks compared to random, search-based, and trajectory-random alternatives. LONGTRACERL significantly improves the base model's performance on the AA-LCR benchmark, achieving the best score among all methods. The method shows consistent improvements across multiple benchmarks, with the highest average score observed when using the trajectory-tiered distractor strategy.

The authors evaluate the performance of LONGTRACERL on multiple long-context reasoning benchmarks using different LLM backbones. Results show that the positive-only reward strategy significantly improves performance across all benchmarks compared to the positive&negative variant, with the highest gains observed on AA-LCR and MRCR. The method consistently outperforms the baseline across all evaluated models and benchmarks. The positive-only reward strategy achieves the highest average score across all benchmarks, outperforming the positive&negative variant. The method shows the most significant improvement on the AA-LCR and MRCR benchmarks, indicating stronger performance on challenging reasoning tasks. Performance gains are consistent across different model sizes and families, demonstrating robustness to model scale and architecture.

The authors evaluate their method, LONGTRACERL, against several baselines on multiple long-context reasoning benchmarks using different models. Results show that LONGTRACERL consistently achieves the highest average performance across all model scales, significantly outperforming other methods, particularly on challenging benchmarks like AA-LCR and LongReason. The improvements are attributed to the rubric reward and positive-only strategy, which guide the model to generate more accurate and grounded reasoning responses. LONGTRACERL achieves the highest average scores across all models and benchmarks compared to all baselines. The method shows the most significant gains on challenging benchmarks, particularly AA-LCR and LongReason, where it substantially outperforms other approaches. The performance improvements are primarily driven by the rubric reward and positive-only strategy, which encourage accurate and grounded reasoning without reward hacking.
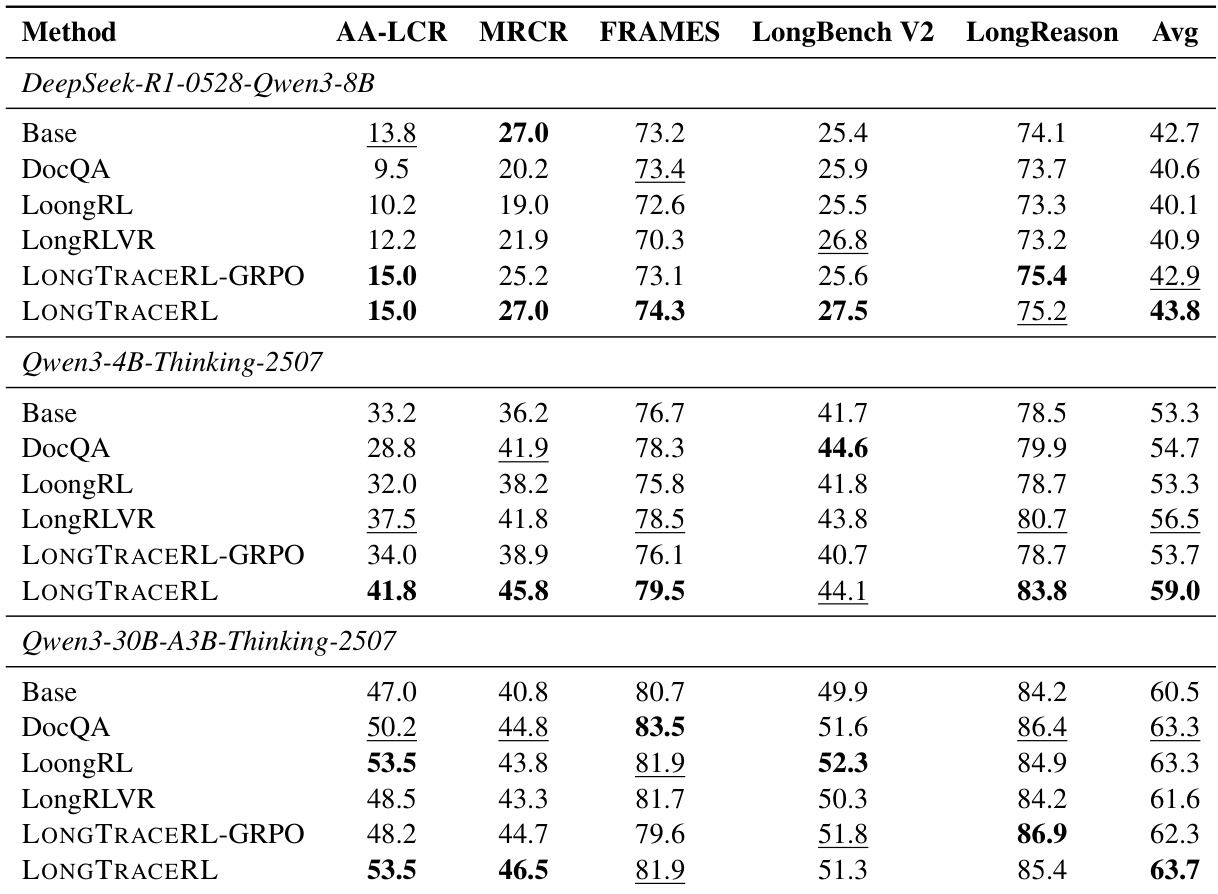
Evaluated across multiple long-context reasoning benchmarks and model configurations, LONGTRACERL demonstrates consistent superiority over baselines through targeted component analyses. The experiments validate that a balanced rubric reward significantly enhances performance on challenging tasks, while trajectory-tiered distractors with high entity overlap provide stronger training signals than random alternatives. Additionally, restricting rewards to positive signals effectively prevents reward hacking and improves reasoning accuracy across different model architectures. Collectively, these findings confirm that the synergistic integration of rubric-guided rewards, high-quality distractors, and positive-only feedback drives more accurate and grounded long-context reasoning.