Command Palette
Search for a command to run...
Qwen-Image-Flash: Beyond Objective Design
Qwen-Image-Flash: Beyond Objective Design
Abstract
Few-step distillation has become an effective strategy for accelerating advanced visual generative models, yet prior work has largely focused on distillation objectives. In this work, we revisit few-step distillation from a complementary perspective, focusing on the training recipe that critically shapes student performance. Using Qwen-Image-2.0 as a representative case, we systematically investigate three factors in unified text-to-image generation and instruction-guided image editing distillation: data composition, teacher guidance, and task mixture. Our empirical analysis reveals several non-obvious behaviors, which motivate the development of Qwen-Image-Flash. Overall, our results suggest that effective few-step distillation requires not only carefully designed objectives, but also principled organization of the broader training pipeline.
One-sentence Summary
Qwen-Image-Flash accelerates advanced visual generative models through few-step distillation by prioritizing a principled training recipe over objective design, systematically optimizing data composition, teacher guidance, and task mixture for unified text-to-image generation and instruction-guided image editing.
Key Contributions
- This work presents a systematic empirical investigation into three training pipeline factors for few-step distillation: data composition, teacher guidance, and task mixture for unified text-to-image generation and instruction-guided image editing.
- Guided by these findings, Qwen-Image-Flash is introduced as a unified student model distilled from Qwen-Image-2.0 that delivers high-quality generation and editing capabilities with only 4 NFEs.
- Experimental results demonstrate that the distilled model matches the teacher foundation model across both tasks, confirming that effective few-step distillation requires a principled organization of the broader training pipeline.
Introduction
Modern visual generative models have evolved into powerful foundation systems capable of text-to-image synthesis and instruction-guided editing, yet their iterative sampling processes impose high computational costs and latency that hinder deployment in latency-sensitive applications. While prior research has primarily optimized distillation objectives to compress these multi-step processes into few-step students, standard training recipes often falter in complex scenarios due to teacher-student distribution mismatches and suboptimal data mixing. The authors leverage this gap to systematically analyze how data composition, teacher guidance, and task mixture shape distillation outcomes, introducing a stepwise multi-teacher strategy and optimized task balancing. Building on these empirical findings, they develop Qwen-Image-Flash, a unified model that achieves high-fidelity generation and editing in just four sampling steps, demonstrating that robust few-step distillation depends on a holistic training pipeline rather than objective design alone.

Dataset

- Dataset Composition and Sources: The authors introduce T2I-Bench and Editing-Bench to systematically evaluate few-step text-to-image generation and editing models. These benchmarks replace conventional datasets like MS-COCO, GenEval, and T2I-CompBench, which the authors note provide limited insight into the specific degradation patterns of modern fast sampling techniques.
- Subset Details: The authors compile T2I-Bench with 1,800 evaluation cases distributed evenly across three categories, allocating 600 samples per category. Editing-Bench is similarly constructed to assess editing capabilities, though exact sample counts are not detailed in the provided excerpts.
- Data Usage and Processing: The authors deploy these benchmarks as a rigorous evaluation suite rather than a training corpus. They utilize Gemini 3.1 Pro and GPT 5.5 as automated preference-based evaluators to score generated images. These models assess perceptual quality, visual fidelity, and alignment with human preference, with higher scores indicating superior output.
- Evaluation Focus and Processing: The authors curate the datasets to expose performance drops in few-step sampling, specifically targeting dense text rendering, structured layouts, prompt adherence, diversity, and fine visual details. Evaluation relies on predefined system prompts and LLM-driven preference scoring instead of traditional metrics like FID or CLIP-based alignment. The provided excerpts focus on benchmark construction and automated scoring rather than training preprocessing, cropping, or metadata generation.
Method
The authors leverage flow matching as a continuous-time framework for learning generative dynamics, which defines a transport process between data and noise by prescribing a probability path and learning the corresponding velocity field. Let x∼pdata represent a data point and ϵ∼pnoise be an independent noise sample, where pnoise is typically set to N(0,I). Following prior work, the linear path is used:
zt=(1−t)x+tϵ,t∈[0,1].
This path interpolates from the data distribution at t=0 to the noise distribution at t=1. The condition c encodes side information such as labels or text embeddings. Under this interpolation, the velocity field along the path is ϵ−x, and flow matching trains a parameterized vector field vθ(zt,t,c) to predict this velocity via the loss:
\ell_{\mathrm{FM}}(\pmb{\theta}) = \mathbb{E}_{t, \pmb{x}, \pmb{\epsilon}} \left[ \left\| \pmb{v}_\pmb{\theta}(\pmb{z}_t, t, \pmb{c}) - (\pmb{\epsilon} - \pmb{x}) \right\|^2 \right].
After training, samples are generated by initializing z1 from the noise prior and integrating the learned ODE backward from t=1 to t=0, yielding xθ=z1+∫10vθ(zt,t,c)dt.
To distill a multi-step teacher into a few-step student, the authors adopt the Distilled Model Distillation (DMD) framework. Given an input noise variable ϵ and condition c, the student generates a clean sample xθ=Gθ(ϵ,c). To compare the student with the teacher at noisy intermediate states, an additional noise sample ξ∼pnoise is drawn, and the student sample is perturbed as xt=(1−t)xθ+tξ with t∼pt. The DMD objective encourages the conditional distribution induced by the student to align with that of the teacher, expressed as a KL divergence:
ℓDMD(θ)≜DKL(pstu(xθ∣c)∥ptea(xθ∣c)).
Rather than optimizing this divergence directly, DMD uses a gradient estimator based on the difference between the score fields of the student and teacher distributions:
\nabla_{\pmb{\theta}} \ell_{\mathrm{DMD}}(\pmb{\theta}) = \mathbb{E}_{\pmb{\epsilon}, \pmb{\xi}, t} \left[ \left( \nabla_{\pmb{\theta}} x_\pmb{\theta} \right)^\top \left( \pmb{s}_{\mathrm{stu}}(\pmb{x}_t, t, \pmb{c}) - \pmb{s}_{\mathrm{real}}(\pmb{x}_t, t, \pmb{c}) \right) \right].
Here, sstu is estimated using an auxiliary score network trained on student-generated samples, while sreal is derived from the pretrained teacher.
To stabilize distillation when using multiple teachers with complementary downstream capabilities, the authors propose step-wise multi-teacher guidance. Instead of relying on a fixed teacher, this strategy combines a stable base teacher with task-specialized teachers. At the k-th selected distillation step, the real-score guidance is defined as a weighted sum:
sreal(k)(xt,t,c)=∑m=0Mλk,m(c)sm(k)(xt,t,c),
where sm(k) is the real-score estimate from teacher Tm at step k, and λk,m(c)∈[0,1] denotes the contribution weight under condition c, satisfying ∑m=0Mλk,m(c)=1. This formulation enables smooth guidance from the base teacher while selectively incorporating task-specific information. The corresponding DMD objective becomes:
\nabla_{\pmb{\theta}} \ell_{\mathrm{DMD}}^{(k)}(\pmb{\theta}) = \mathbb{E}_{\pmb{\epsilon}, \pmb{\xi}, t} \left[ \left( \nabla_{\pmb{\theta}} x_\pmb{\theta} \right)^\intercal \left( \pmb{s}_{\mathrm{stu}}(\pmb{x}_t, t, \pmb{c}) - \sum_{m=0}^{M} \lambda_{k,m}(\pmb{c}) \pmb{s}_m^{(k)}(\pmb{x}_t, t, \pmb{c}) \right) \right].
Experiment
The experiments evaluate few-step text-to-image distillation by systematically varying training data composition, teacher specialization, and task-mixture ratios. Qualitative analysis reveals that coherent single-category training data generalizes more effectively than diverse or directly aligned datasets, while relying on task-specialized teachers introduces optimization instability and structural misalignment. Additionally, joint distillation demonstrates that a balanced generation-editing task mixture maximizes instruction-following capabilities and unexpectedly enhances overall text-to-image generation through complementary visual-textual supervision.
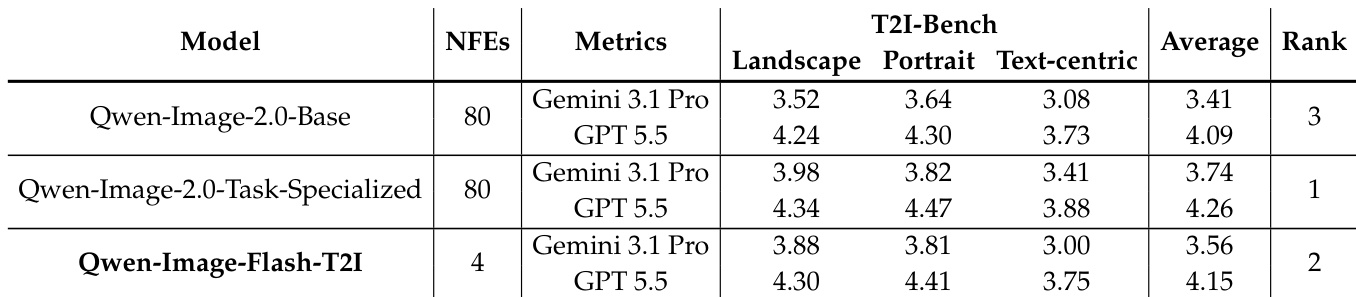
The authors evaluate joint distillation of text-to-image and image editing capabilities under varying task-mixture ratios. Results show that a balanced mixture of T2I and editing data leads to the strongest editing performance, while also improving T2I generation quality compared to T2I-only distillation. The performance is sensitive to the ratio, with insufficient editing data failing to transfer editing behavior and a balanced ratio enabling effective instruction-following and visual quality. A balanced mixture of T2I and editing data achieves the best editing performance and outperforms the teacher model. Editing supervision improves T2I generation quality rather than degrading it. Insufficient editing data fails to transfer editing behavior, while a balanced ratio enables strong instruction following and visual fidelity.
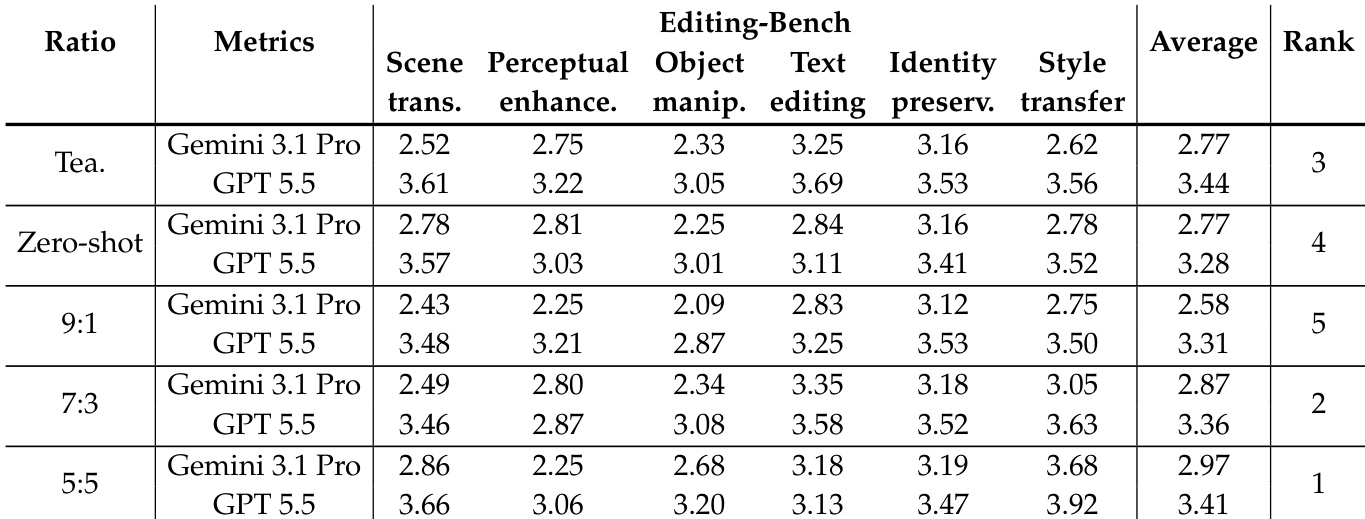
The authors compare the performance of different models on T2I-Bench, evaluating their capabilities across landscape, portrait, and text-centric categories. Results show that a distilled 4-NFE student model achieves competitive performance compared to the multi-step teacher, with varying strengths depending on the evaluation metric and category. A distilled student model achieves strong performance across T2I-Bench categories, with results close to the multi-step teacher on some metrics. The distilled model shows a trade-off in performance, with higher scores on some metrics and lower scores on others compared to the teacher. Performance varies across evaluation metrics, indicating different strengths in handling landscape, portrait, and text-centric tasks.
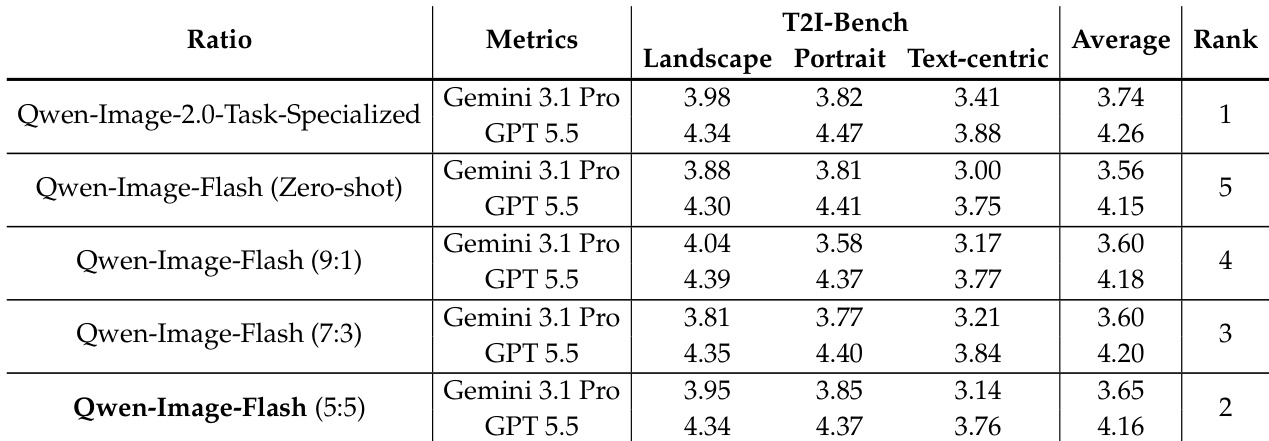
The authors examine the impact of task-mixture composition in joint T2I-editing distillation, focusing on how varying the ratio of text-to-image to editing data affects both editing performance and T2I generation quality. Results show that a balanced mixture of T2I and editing data leads to the strongest editing transfer while also improving overall T2I generation, indicating that editing supervision provides complementary signals rather than causing degradation. A balanced T2I-to-editing data ratio enables the strongest editing transfer and improves T2I generation quality. Insufficient editing data leads to weak editing supervision and poor performance, while a balanced mixture provides dense and effective task-specific guidance. Editing supervision enhances T2I generation rather than degrading it, suggesting complementary visual-textual learning benefits.
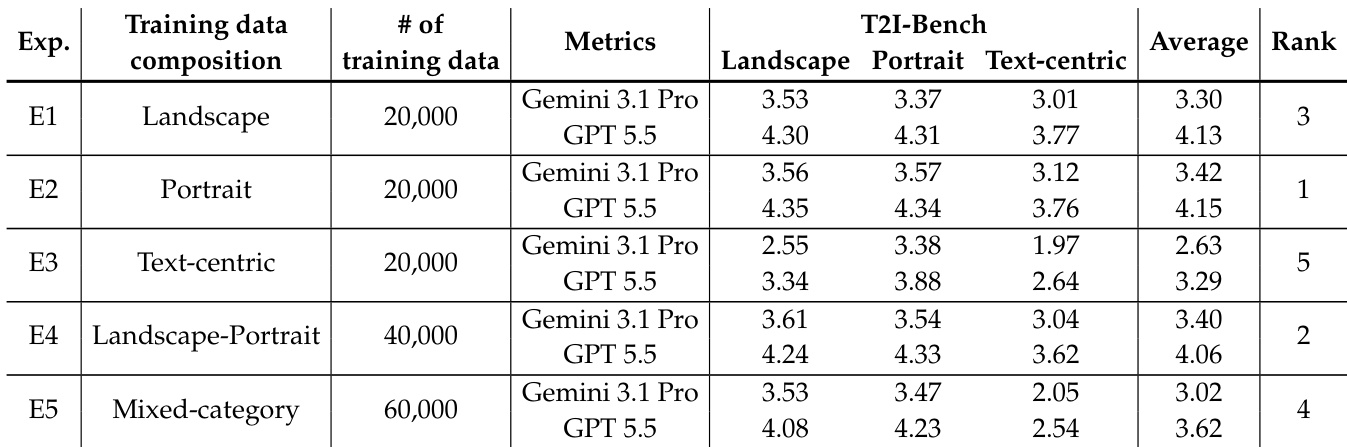
The authors examine how different training data compositions affect the performance of text-to-image distillation models, focusing on both general image generation and text-centric synthesis. Results show that single-category training data, such as landscape or portrait, leads to stronger performance across all evaluation categories compared to mixed or text-centric-only data, indicating that data diversity does not necessarily improve outcomes and may even degrade performance. The best-performing configuration is portrait-only training, which outperforms more diverse setups despite not being directly aligned with the text-centric task. Single-category training data leads to better overall performance than mixed or text-centric-only data Text-centric-only training performs worse than landscape or portrait-only training on all evaluation splits A balanced mixture of categories does not outperform the best single-category configuration
The experiments evaluate a distilled text-to-image model by varying task-mixture ratios and training data compositions to validate the interplay between generation fidelity and editing capability. Results demonstrate that a balanced ratio of text-to-image and editing data during joint distillation maximizes editing transfer while simultaneously enhancing overall generation quality, confirming that editing supervision acts as a complementary signal. Conversely, restricting training to single visual categories consistently outperforms mixed or text-focused datasets, indicating that broad data diversity does not necessarily improve generalization. Ultimately, the accelerated student model achieves competitive performance against the multi-step teacher across diverse evaluation categories, effectively capturing task-specific strengths despite architectural simplifications.