Command Palette
Search for a command to run...
Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
Abstract
We introduce Humanoid-GPT, a GPT-style Transformer with causal attention trained on a billion-scale motion corpus for whole-body control. Unlike prior shallow MLP trackers constrained by scarce data and an agility-generalization trade-off, Humanoid-GPT is pre-trained on a 2B-frame retargeted corpus that unifies all major mocap datasets with large-scale in-house recordings. Scaling both data and model capacity yields a single generative Transformer that tracks highly dynamic behaviors while achieving unprecedented zero-shot generalization to unseen motions and control tasks. Extensive experiments and scaling analyses show that our model establishes a new performance frontier, demonstrating robust zero-shot generalization to unseen tasks while simultaneously tracking highly dynamic and complex motions.
One-sentence Summary
Humanoid-GPT, a GPT-style Transformer with causal attention, achieves unprecedented zero-shot generalization to unseen motions and control tasks by scaling both data and model capacity through pretraining on a unified 2B-frame retargeted corpus, effectively overcoming the data scarcity and agility-generalization trade-offs of prior shallow MLP trackers while tracking highly dynamic whole-body behaviors.
Key Contributions
- Humanoid-GPT is a GPT-style Transformer with causal attention that distills hundreds of reinforcement learning motion experts into a single generative controller. The architecture predicts per-joint PD targets through causal temporal attention, aligning with real-time deployment constraints while scaling cleanly with model capacity beyond shallow MLP limitations.
- Harmonic Motion Embedding (HME) is introduced as a representation learning tool that quantifies and organizes motion diversity directly from raw recordings. This method enables diversity-aware, distribution-balanced sampling during training, preventing overfitting to frequent motion modes while preserving capability across varied behaviors.
- Trained on a curated 2B-frame corpus that unifies major mocap datasets with large-scale in-house recordings, the system achieves robust zero-shot generalization to unseen motions and control tasks. Extensive simulations and real-world deployment on the Unitree-G1 hardware establish explicit scaling laws that map data and model size to tracking accuracy.
Introduction
Humanoid motion tracking is essential for embodied AI systems that must execute robust whole-body behaviors across unseen tasks, styles, and environments. Prior methods typically rely on shallow multilayer perceptrons trained on limited motion datasets, which forces a persistent trade-off between tracking agility and zero-shot generalization. These capacity-constrained architectures also struggle with non-causal design choices and plateau as data volume increases. The authors address these bottlenecks by introducing Humanoid-GPT, a GPT-style Transformer with causal attention trained on a curated 2 billion frame motion corpus. By scaling both data and model capacity while implementing diversity-aware sampling and stable distillation from reinforcement learning experts, the system achieves unified agility and robust zero-shot generalization to highly dynamic and unseen human motions on real hardware.
Dataset

- Composition and Sources: The authors construct a unified motion corpus by aggregating four established datasets: AMASS, LAFAN1, MotionMillion, and PHUMA, which together provide a broad spectrum of human activities and physically grounded motion priors.
- Subset Details and Filtering: The paper does not disclose individual subset sizes or explicit mixture ratios. Instead, the team applies consistent filtering across the entire collection, discarding any sequences that feature explicit object interactions such as sitting on chairs, swimming, or stair climbing to ensure compatibility with plain scene actuation.
- Processing and Augmentation: Every motion sequence is retargeted into the Unitree-G1 humanoid's 29-DoF joint space using an off-the-shelf retargeting framework. To improve temporal variability and speed robustness, the authors apply time-warping augmentation by uniformly accelerating and decelerating each sequence, which expands the final dataset to roughly five times its original size.
- Usage and Training: This curated, physically consistent corpus serves as the foundational training data for Humanoid-GPT and directly enables downstream reinforcement learning-based expert training.
Method
The Humanoid-GPT framework is structured as a two-stage pipeline designed to enable zero-shot tracking of arbitrary human motions by a humanoid robot. The first stage involves training a diverse set of motion experts, each specialized in a specific subset of motion data. To achieve this, the full motion corpus is partitioned into approximately 300 clusters using a novel embedding representation called Harmonic Motion Embedding (HME). This embedding is derived by first training Periodic Autoencoders on data partitions to extract per-joint periodic amplitudes and frequencies. For each motion sequence, the mean and standard deviation of these joint-level harmonic features are aggregated to form a compact HME vector. These vectors are then clustered using K-Means with pairwise distances as the similarity metric, resulting in clusters that contain 1k–2k sequences each, ensuring strong intra-cluster consistency while maintaining broad coverage of the motion distribution.
Each motion expert is trained via a reinforcement learning (RL) approach based on Proximal Policy Optimization (PPO) to track all sequences within its assigned cluster. The policy, denoted as π:G×S↦A, maps the current privileged robot state stpriv.—which includes per-joint positions and velocities, root angular velocity, projected gravity, and the previous control action—and the target reference pose qtref to low-level motor actions at. The policy outputs actions that are converted into actuator torques through a PD controller. The motion tracking objective is to drive the robot's state to match the target pose gt=qtref while maintaining balance and dynamic stability. The reward function is formulated at the body keypoint level, incorporating position, orientation, and velocity consistency terms for critical body parts. Specifically, the keypoint reward Rkp(t) is composed of position, rotation, and velocity components, each using an exponential form to softly penalize deviations, along with additional penalties for self-contact and smoothness to ensure physically grounded and stable tracking.

The second stage of the pipeline is a distillation process that consolidates the knowledge of all trained motion experts into a single unified policy. This is achieved through a Transformer-based generalist tracker Gθ, which employs the DAgger framework to distill expert behaviors. The distillation process is reformulated as a sequence modeling problem, where the input token embedding et is constructed by concatenating the current proprioceptive state st and the target reference pose qtref. A sequence of length H containing these tokens is fed into the Transformer with a temporal causal mask, allowing the model to capture long-horizon dependencies and temporal consistency. The actions at all output positions are supervised by the corresponding history of teacher outputs, enabling efficient training over multiple timesteps in a single pass. The loss function is defined as L(Gθ(et−H+1:t),a^t−H+1:t), where a^t−H+1:t is the concatenated sequence of teacher actions. During inference, a queue of maximal H history tokens serves as input, and the output at the last position is used as the current control target.
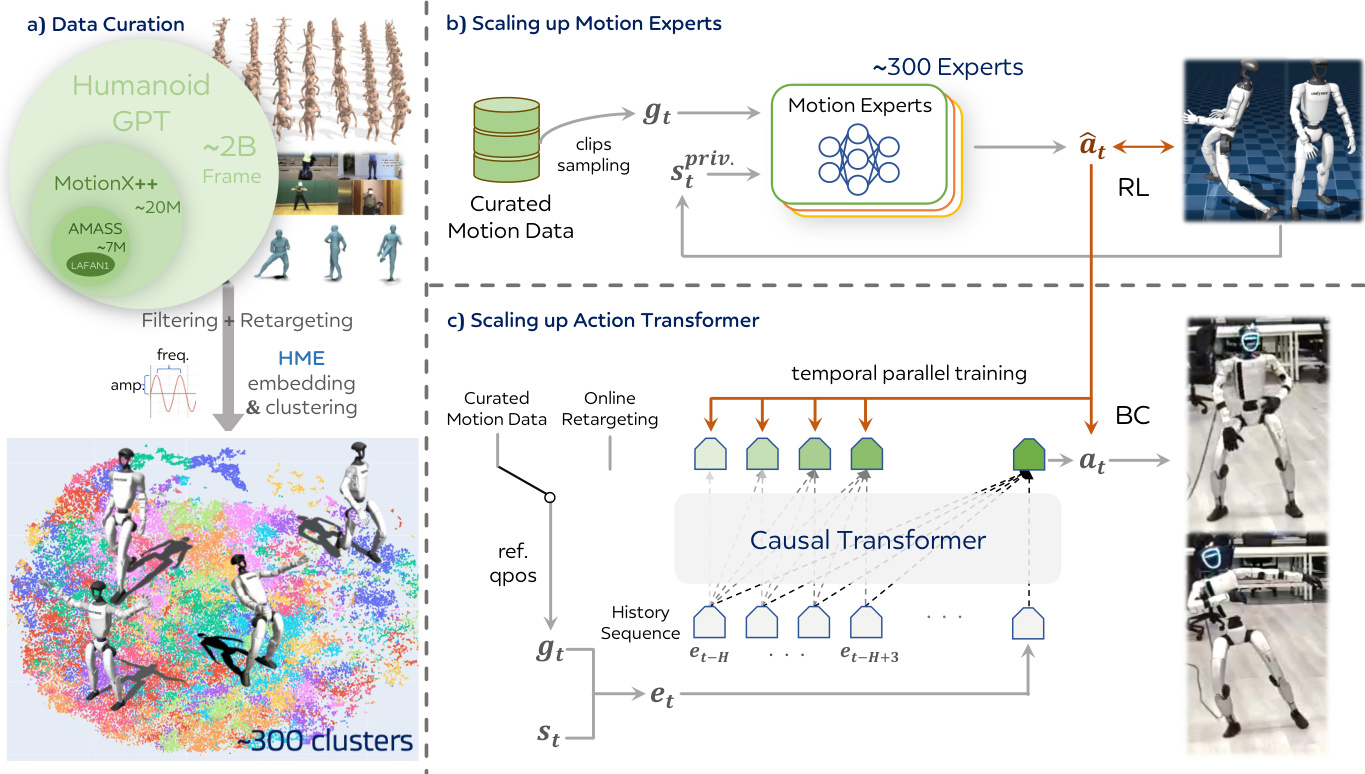
The overall framework is designed to leverage the strengths of the Transformer architecture, including parallel sequence supervision and autoregressive temporal prediction. This design allows the model to implicitly learn position-invariant temporal prediction, enabling stable and physically consistent control outputs even at the beginning of an episode where historical information is limited. The framework is further enhanced by a scalable causal Transformer for motion tracking, which fits the online tracking constraint of not accessing future observations and scales better than MLP and non-causal variants. The combination of diverse motion priors, scalable architecture, and balanced distribution sampling ensures the model's ability to generalize across a wide range of motion targets.
Experiment
The evaluation spans controlled MuJoCo simulations and real-world deployments on a Unitree-G1 humanoid to assess zero-shot motion tracking, data scaling trends, and architectural robustness. Experiments demonstrate that expanding both motion corpus diversity and Transformer capacity yields consistent improvements in stability and generalization, while outperforming MLP and TCN baselines that suffer from early saturation and overfitting. Real-world tests confirm strong zero-shot transfer across highly dynamic, unseen choreographies and live teleoperation, with hardware-aware optimizations ensuring the scaled model maintains the low-latency inference speeds required for real-time whole-body control.
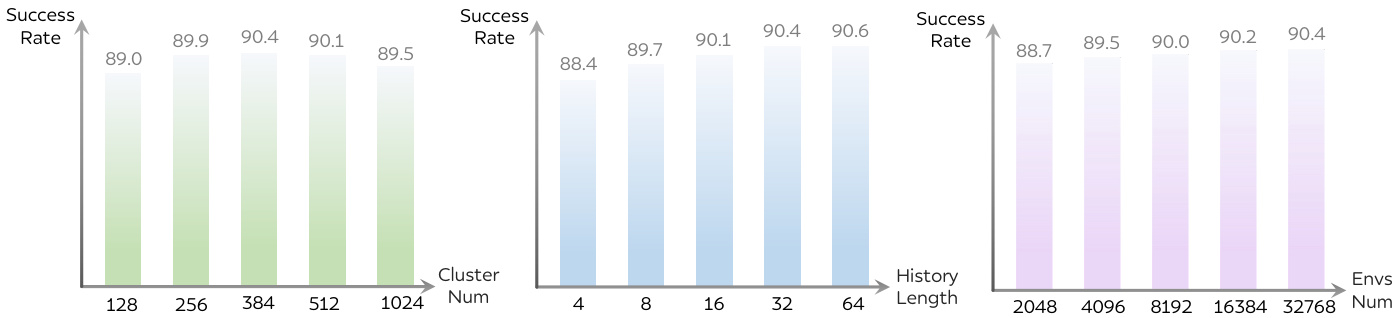
The authors analyze the impact of various architectural and training factors on the performance of their humanoid motion tracking model, focusing on zero-shot generalization. Results show that increasing the number of clusters, history length, and environment count improves tracking success rate, indicating that richer and more diverse training conditions enhance model stability and generalization. The model demonstrates robust performance across different configurations, with optimal settings balancing complexity and effectiveness. Increasing the number of clusters improves tracking success rate, suggesting that better motion clustering enhances model performance. Longer history lengths lead to higher success rates, indicating improved temporal modeling capabilities. A larger number of environments during training results in better tracking performance, highlighting the importance of diverse training conditions.
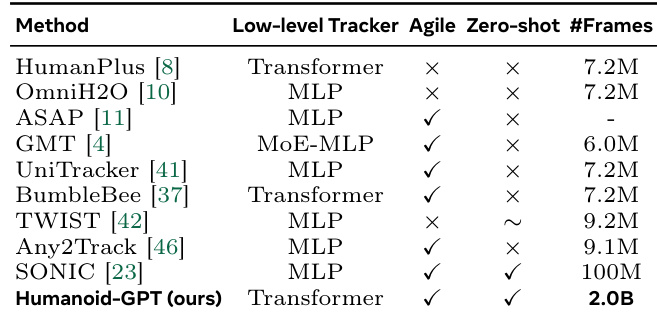
The authors compare different backbone architectures for humanoid motion tracking, evaluating their performance across multiple metrics. Results show that Humanoid-GPT variants outperform other methods, with Humanoid-GPT-B achieving the best balance of low position and velocity errors across all tested backbones. The comparison highlights the effectiveness of Transformer-based models over alternatives like GMT, TWIST, and Any2Track in maintaining tracking accuracy and stability. Humanoid-GPT variants achieve lower position and velocity errors compared to other backbone architectures. Humanoid-GPT-B demonstrates the best overall performance in both MPJPE and MPJVE metrics. Transformer-based models outperform alternative backbones such as GMT, TWIST, and Any2Track in tracking accuracy and stability.

The authors analyze the impact of data and model scaling on zero-shot humanoid tracking performance, demonstrating that larger datasets and higher-capacity Transformer models consistently improve stability and accuracy. Results show that Transformers scale more effectively than MLPs and TCNs, with significant gains in tracking precision and robustness, particularly when trained on extensive motion data. The model achieves strong zero-shot generalization in both simulation and real-world settings, maintaining high-fidelity whole-body tracking across diverse, complex motions without task-specific adaptation. Larger datasets and higher-capacity Transformers consistently improve tracking stability and accuracy in zero-shot scenarios. Transformers outperform MLP and TCN baselines in both scaling efficiency and tracking precision, especially with large-scale data. The model demonstrates strong zero-shot generalization, successfully tracking diverse, high-dynamic motions in real-world deployments without task-specific tuning.

The authors compare various humanoid tracking methods, focusing on the impact of model architecture, data scale, and zero-shot generalization. Results show that Transformer-based models, particularly when trained on large-scale motion data, achieve superior tracking performance and stability compared to MLP-based approaches. The study demonstrates that scaling both the dataset and model capacity leads to consistent improvements in zero-shot tracking accuracy and real-world transfer. Transformer-based models outperform MLP-based methods in zero-shot tracking accuracy and stability Larger datasets and model capacities consistently improve tracking performance across all metrics The proposed method achieves strong zero-shot generalization in real-world settings without task-specific fine-tuning
The authors conduct experiments to evaluate the scaling properties and zero-shot generalization of Humanoid-GPT, a humanoid motion tracker. They analyze how model and data scaling affect tracking performance in simulation and real-world settings, demonstrating that larger models and datasets improve stability and accuracy, while also showing strong zero-shot transfer from simulation to physical hardware. The study includes ablation studies on architectural choices and training configurations to understand their impact on performance. Larger models and datasets consistently improve tracking accuracy and stability in simulation and real-world settings. Humanoid-GPT achieves strong zero-shot generalization, successfully tracking diverse and complex motions on real hardware without task-specific fine-tuning. The model's performance scales effectively with data and capacity, outperforming baseline architectures that saturate or overfit with increased size.

The experiments evaluate architectural design, training configurations, and model scaling to validate zero-shot humanoid motion tracking across simulation and real-world environments. Results indicate that richer training conditions, extended temporal history, and Transformer-based backbones consistently enhance tracking stability and accuracy over alternative architectures. Scaling both data volume and model capacity yields steady performance gains without overfitting, confirming the framework's effective generalization to complex motions. Ultimately, the method demonstrates robust simulation-to-reality transfer without task-specific fine-tuning, establishing its scalability and practical utility.