Command Palette
Search for a command to run...
Continual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments
Continual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments
Parth Asawa Christopher M. Glaze Gabriel Orlanski Ramya Ramakrishnan Benji Xu Asim Biswal Vincent Sunn Chen Frederic Sala Matei Zaharia Joseph E. Gonzalez
Abstract
Continual learning, the ability of AI systems to improve through sequential experience, has attracted substantial interest, but no high-quality benchmark exists to evaluate it. We introduce Continual Learning Bench (CL-BENCH), the first difficult, expert-validated benchmark designed to measure whether LLM-based systems genuinely improve with experience. CL-BENCH spans six diverse domains (software engineering, signal processing, disease outbreak forecasting, database querying, strategic game-playing, and demand forecasting), each validated by domain experts and designed so that tasks share a learnable latent structure (codebase layout, disease outbreak dynamics, opponent strategies) that a stateful system can discover online but a stateless one cannot. We evaluate frontier models across several agent architectures, from naive in-context learning (ICL) to dedicated memory systems, introducing a gain metric to isolate learning from prior capabilities. We find that these systems leave headroom for improved continual learning: agents frequently overfit to immediate observations or fail to reuse knowledge across instances, and dedicated memory systems do not fix this—in fact, naive ICL outperforms systems dedicated to memory management.
One-sentence Summary
The authors introduce Continual Learning Bench, an expert-validated benchmark spanning six diverse domains with learnable latent structures to measure whether LLM-based systems genuinely improve with experience in real-world stateful environments, revealing that agents frequently overfit to immediate observations and naive in-context learning outperforms dedicated memory systems.
Key Contributions
- Continual Learning Bench (CL-BENCH) is introduced as the first difficult, expert-validated benchmark designed to measure whether LLM-based systems genuinely improve with experience across six diverse domains. Tasks within the benchmark contain discoverable latent structures that require stateful systems to learn online rather than relying on static pretrained knowledge.
- A gain metric is introduced to isolate genuine learning from prior capabilities by measuring the performance difference between systems with online experience and stateless baselines. The metric defines when measured improvement reflects online learning of environment-specific structure rather than static model capability.
- Evaluation of frontier models across several agent architectures demonstrates that current systems leave headroom for improved continual learning performance. Results indicate that agents frequently overfit to immediate observations and naive in-context learning outperforms systems dedicated to memory management.
Introduction
Building large language model systems that improve through sequential experience is essential for real-world applications like software engineering agents and decision-support agents. Existing evaluation protocols rely on proxies such as recall or language modeling loss that fail to verify if a system truly learns environment-specific latent structure online. The authors introduce Continual Learning Bench (CL-BENCH) to measure whether AI systems improve through sequential experience across six diverse domains. Their framework utilizes tasks with discoverable latent structures and concept drift to minimize reliance on pretrained knowledge while defining a gain metric to isolate stateful learning from static capability.
Dataset
Dataset Composition and Sources
- The benchmark spans six diverse domains including software engineering, database analytics, epidemiological forecasting, RF spectrum monitoring, sales forecasting, and strategic gaming.
- Data is sourced from real-world repositories like SWE-bench and the Amazon Products Metadata dataset, then curated to ensure tasks contain learnable latent structure not recoverable from pretraining.
Key Details for Each Subset
- Codebase Adaptation: Contains 19 issues from jazzband/tablib and jd/tenacity repositories. Instances are filtered for problem statements over 600 characters and patches between 8 and 300 lines.
- Database Exploration: Features 40 natural-language questions on a SQLite database of 50K Amazon products. The schema is obfuscated and undergoes a migration halfway through the sequence.
- Cohort Studies: Consists of 20 instances across five study blocks, each providing a unique SQLite database with distinct demographic variables and coding conventions.
- Exploitable Poker: Includes 120 hands of Texas Hold'em against deterministic opponent policies across five stages to test strategy inference.
- Sales Prediction: Comprises 12 instances spanning forecast years 2027 to 2038 across three store locations with rotating visible data.
- RF Spectrum Monitoring: Presents 90 scans where agents report occupied spectrum using IoU scoring.
Model Usage and Evaluation
- The authors evaluate systems using a full schedule of instances processed sequentially from start to finish.
- Performance is measured via normalized gain to isolate online learning from underlying model capability.
- Systems are compared against a stateless baseline to determine if memory or state management improves efficiency or accuracy over time.
Processing and Validation
- Each task undergoes review by two authors and two to three domain experts to validate realism and learning potential.
- Data transformations include schema obfuscation, unit modification, and the injection of distractor columns to prevent shallow exploration.
- Instances are partitioned into boundary and within-variant sets to analyze adaptation at concept switches.
Method
The authors establish a rigorous protocol for benchmark construction to ensure tasks effectively measure learning capabilities. Refer to the workflow diagram for the three-stage process. This pipeline begins with Task Design, focusing on domain and instance sequences. It proceeds to Expert Validation, where panels verify criteria such as headroom, shared structure, and learning mechanisms. Finally, a Decision phase categorizes tasks as Reject, Refine, or Accept based on a three-axis rating of realism, reusability, and improvement.
To quantify learning, the authors introduce a comparative framework distinguishing between stateful and stateless systems. Refer to the continual learning system diagram. A stateless baseline processes each instance xt independently, defined by πt=π(xt). In contrast, a stateful system conditions on the full history Ht−1, allowing it to accumulate knowledge. The core metric, Gain, isolates the value of this accumulated state. It is calculated as the difference between the reward achieved by the stateful system rtsf and the stateless baseline rtsl for each instance, aggregated over the task schedule as g=∑t=1N(rtsf−rtsl).
The practical dynamics of this framework are visualized in the agent interaction loop. Refer to the framework diagram showing the agent's lifecycle. During a Cold Start phase (Q1), the agent must explore the environment from scratch, utilizing queries to discover schema details. As the agent accumulates Past Experience (Q10), it leverages known structures to answer questions more efficiently, requiring fewer queries. However, the system must also handle concept drift, such as a Database Migration (Q25). In this phase, previously learned information becomes stale, for instance due to renamed columns, and blindly reusing past experience leads to failure. The agent must detect this drift and discard outdated knowledge to re-explore, demonstrating the necessity of adaptive memory management.
Finally, the authors decompose the normalized gain to analyze the stability-plasticity tradeoff. This involves separating the gain into a stability component, which measures the retention of useful structure across variants, and a plasticity component, which measures adaptation to new information within a variant. This decomposition allows for a granular assessment of how well a system balances retaining old knowledge against learning new patterns.
Experiment
This study introduces CL-BENCH, a benchmark spanning six real-world domains designed to evaluate how frontier language models improve from sequential experience across various agent architectures. Experiments comparing full-context in-context learning against dedicated memory systems reveal that simple context preservation often outperforms specialized continual learning mechanisms in both performance and cost efficiency. Although learning dynamics vary significantly by task, the results indicate that reliable online adaptation remains an open problem as dedicated memory systems generally fail to justify their computational cost.
The authors evaluate frontier language models across various continual learning agent architectures on the CL-BENCH benchmark. Results indicate that full-context In-Context Learning (ICL) serves as a strong baseline, frequently outperforming dedicated memory systems like ACE in terms of learning gain and cost efficiency. While the ACE system achieves the highest cumulative reward, it does so at a significantly higher financial cost compared to top-performing ICL configurations. Full-context ICL configurations consistently rank highly for cumulative gain, often outperforming dedicated memory mechanisms. The ACE system achieves the highest cumulative reward but incurs the highest financial cost among the evaluated systems. Several configurations, including those using Codex and Gemini models, exhibit negative cumulative gain, indicating a failure to improve over stateless baselines.
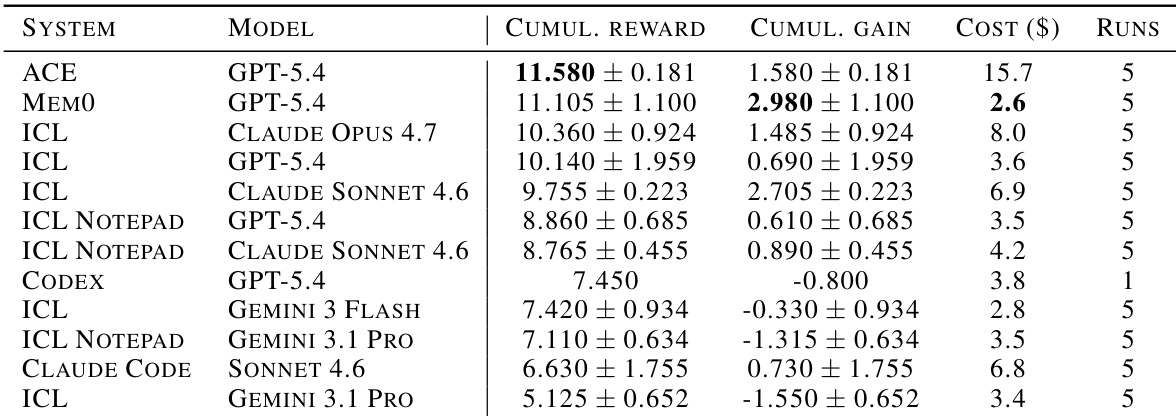
The study evaluates frontier language models using different agent architectures to assess their capacity for continual learning. Findings demonstrate that naive In-Context Learning serves as a robust baseline, frequently outperforming dedicated memory mechanisms in both reward and cost efficiency. While specialized systems like ICL Notepad achieve significant learning gains, they often lag behind full-context ICL in absolute performance metrics. Full-context ICL configurations consistently secure the highest cumulative rewards among all tested system-model pairs. Dedicated memory systems incur substantially higher operational costs without achieving proportionally higher performance gains. ICL Notepad achieves the highest cumulative gain, indicating strong adaptation to sequential experience despite lower overall reward scores.
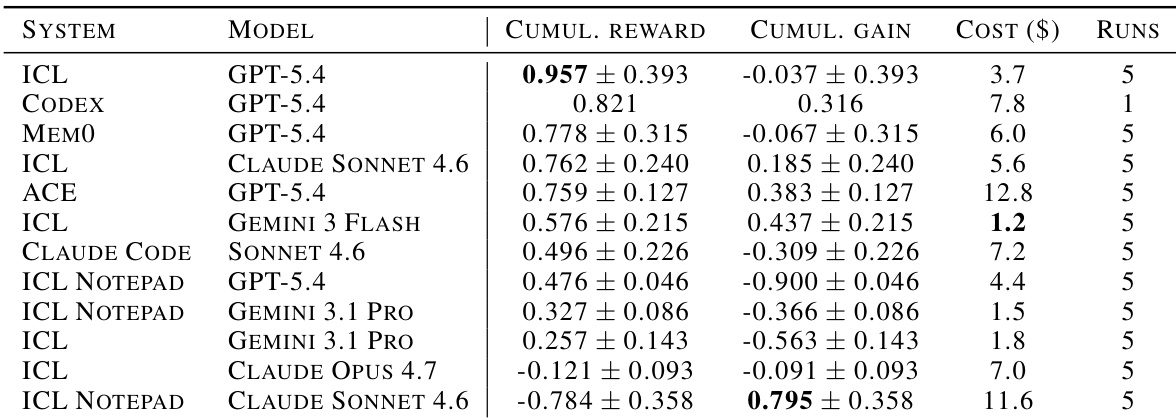
The authors evaluate various frontier language models and agent architectures on the CL-BENCH benchmark to assess continual learning capabilities. Results indicate that full-context In-Context Learning (ICL) serves as a strong baseline, with the Claude Sonnet 4.6 model achieving leading aggregate reward and gain among all tested configurations. In contrast, dedicated memory systems like ACE and ICL Notepad generally underperform relative to their higher computational costs or fail to match the effectiveness of simple context preservation. Full-context ICL with Claude Sonnet 4.6 achieves top-tier cumulative reward and gain across the benchmark tasks. Dedicated memory systems such as ACE incur significantly higher costs without translating that expense into proportionally higher performance gains. ICL variants dominate the cost-efficiency frontier, outperforming complex agent memory mechanisms in both reward and economic efficiency.
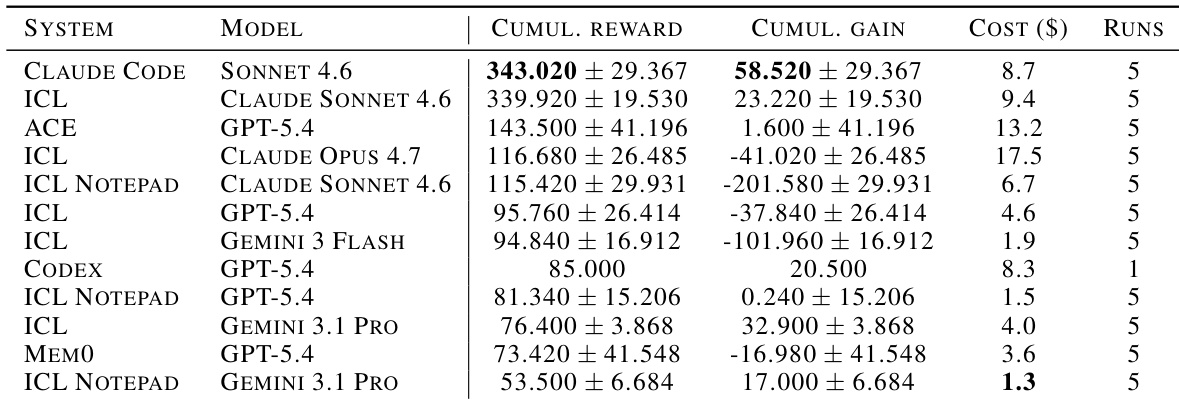
The authors evaluate frontier language models equipped with various continual learning architectures, finding that full-context In-Context Learning (ICL) serves as a strong baseline. Results indicate that ICL-based systems frequently occupy top positions in cumulative gain, while dedicated memory systems often incur higher costs for lower relative performance. ICL-based systems consistently rank in the top positions for cumulative gain, demonstrating the effectiveness of full-context preservation. Cost efficiency analysis indicates that ICL variants outperform dedicated memory systems like ACE, which incur high costs for lower gains. Simple context preservation mechanisms prove more effective than structured memory paradigms such as ICL Notepad, which show lower rewards despite similar model backbones.
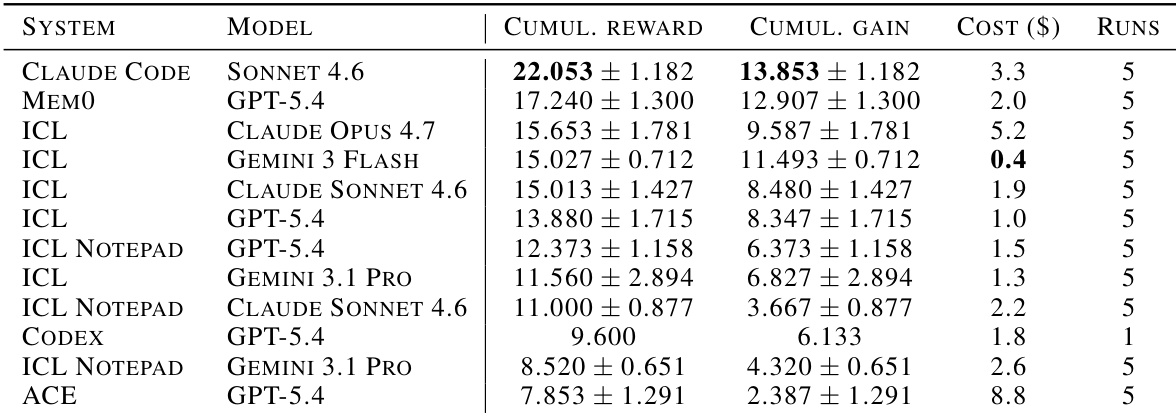
The authors evaluate frontier language models with various agent architectures on a continual learning benchmark to assess their ability to improve from sequential experience. Results indicate that In-Context Learning (ICL) and its variants consistently achieve the highest cumulative reward and gain compared to dedicated memory systems like ACE or Mem0. Additionally, ICL configurations demonstrate superior cost efficiency, with the Gemini Flash variant offering the lowest cost while maintaining strong performance. ICL and ICL Notepad configurations occupy the top positions for cumulative reward and gain in the evaluation. Dedicated memory systems such as ACE and Codex show lower performance relative to their operational costs. The ICL configuration with Gemini Flash offers the best cost efficiency among all tested systems.
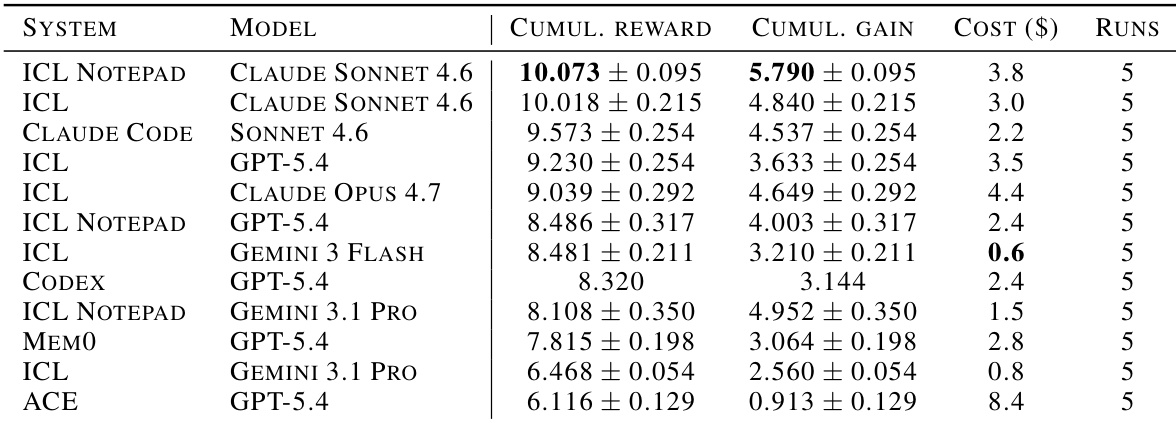
The study evaluates frontier language models across various continual learning agent architectures on the CL-BENCH benchmark to validate their capacity for sequential improvement. Results indicate that full-context In-Context Learning serves as a strong baseline, frequently outperforming dedicated memory systems in terms of learning gain and cost efficiency. Although specialized systems achieve high rewards, they incur significantly higher financial costs without delivering proportionally higher performance gains.