Command Palette
Search for a command to run...
WEAVEBENCH: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
WEAVEBENCH: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Wanli Li Bowen Zhou Yunyao Yu Zhou Xu Yifan Yang Dongsheng Li Caihua Shan
Abstract
Computer-use agents (CUs) increasingly operate in runtimes that combine visual desktop control, command-line execution, code editing, browsers, and external tools. Existing benchmarks, however, often evaluate these interfaces as separable capabilities, leaving long-horizon cross-interface orchestration under-tested. Thus, we introduce WEAVEBENCH, a long-horizon hybrid-interface benchmark with 114 tasks across 8 real-world work domains, grounded in real user requests and publicly verifiable artifacts. Each task requires agents to combine GUI observations/actions with CLI/code operations within a single trajectory. We evaluate these tasks on a real Ubuntu desktop inside deployed CLI-agent runtimes, augmented with a minimal desktop-control plugin. We also propose a companion trajectory-aware judge that inspects deliverables, files, screenshots, logs, and action traces, while detecting shortcut behaviors such as fabricated visual evidence or hard-coded metrics. Across frontier model–runtime pairings, the best PassRate reaches only 41.2%, showing the benchmark remains far from saturated. The trajectory-aware judge further reveals that outcome-only grading substantially overestimates agent performance. Overall, WEAVEBENCH exposes a critical gap in CUA evaluation and provides an effective testbed to measure whether agents can orchestrate GUI, CLI, and code operations across long-horizon real-world tasks.
One-sentence Summary
The authors propose WEAVEBENCH, a long-horizon hybrid-interface benchmark comprising 114 tasks across eight real-world work domains requiring computer-use agents to combine GUI, CLI, and code operations within single trajectories on a real Ubuntu desktop, which employs a trajectory-aware judge to detect shortcut behaviors and reveals a best PassRate of 41.2% across frontier models while demonstrating that outcome-only grading substantially overestimates agent performance.
Key Contributions
- The paper introduces WEAVEBENCH, a long-horizon hybrid-interface benchmark containing 114 tasks across 8 real-world work domains that require agents to combine GUI observations with CLI and code operations. Each task is grounded in publicly verifiable artifacts and real user requests to ensure the evaluation reflects authentic cross-interface orchestration challenges.
- A companion trajectory-aware judge is introduced to inspect deliverables, files, screenshots, logs, and action traces while detecting shortcut behaviors such as fabricated visual evidence or hard-coded metrics. This tool provides a rigorous assessment method that goes beyond simple outcome grading to verify the agent process.
- Experiments across frontier model-runtime pairings show the best PassRate reaches only 41.2%, indicating the benchmark remains far from saturated. The trajectory-aware judge further reveals that outcome-only grading substantially overestimates agent performance, exposing a critical gap in current computer-use agent evaluation.
Introduction
The provided source text is empty. I cannot summarize the research background or contributions without the actual content. Please share the abstract or body snippet so I can outline the technical context, prior work limitations, and the authors' main contribution.
Dataset
-
Dataset Composition and Sources The authors compile 114 tasks spanning 8 real-world work domains including desktop productivity, web development, and DevOps. Sources include public artifacts like GitHub issues, Stack Exchange posts, and design mocks. Every task is grounded in at least one publicly verifiable URL with a total of 174 source links across the corpus.
-
Subset Details and Filtering Admission requires satisfying three properties regarding interface coordination and task complexity. P1 enforces channel non-substitutability so agents must combine GUI observations and actions with CLI and code operations. P2 demands long-horizon execution with multiple interleaved interface phases. P3 requires cross-application state management where workflows span independent processes.
-
Construction and Processing The team follows a four-stage pipeline beginning with archetype-guided sourcing from real user requests. Experts package assets into self-contained bundles including seed data and verification anchors. Independent reviewers perform blind checks for clarity and sandbox reproducibility. Pilot agents run trials to detect broken or trivial tasks before final inclusion.
-
Usage and Evaluation The dataset functions as a benchmark for evaluation rather than model training. Agents operate inside a real Ubuntu desktop sandbox augmented with a minimal GUI plugin. A trajectory-aware judge evaluates performance by inspecting deliverables and action traces to detect shortcut behaviors. Metadata construction involves annotating atomic operations to verify hybrid interface requirements.
Method
The evaluation framework for WEAVEBENCH is designed as a three-stage pipeline to ensure rigorous assessment of agent capabilities across diverse domains. Refer to the framework diagram below for an overview of the construction, benchmark running, and evaluation stages.
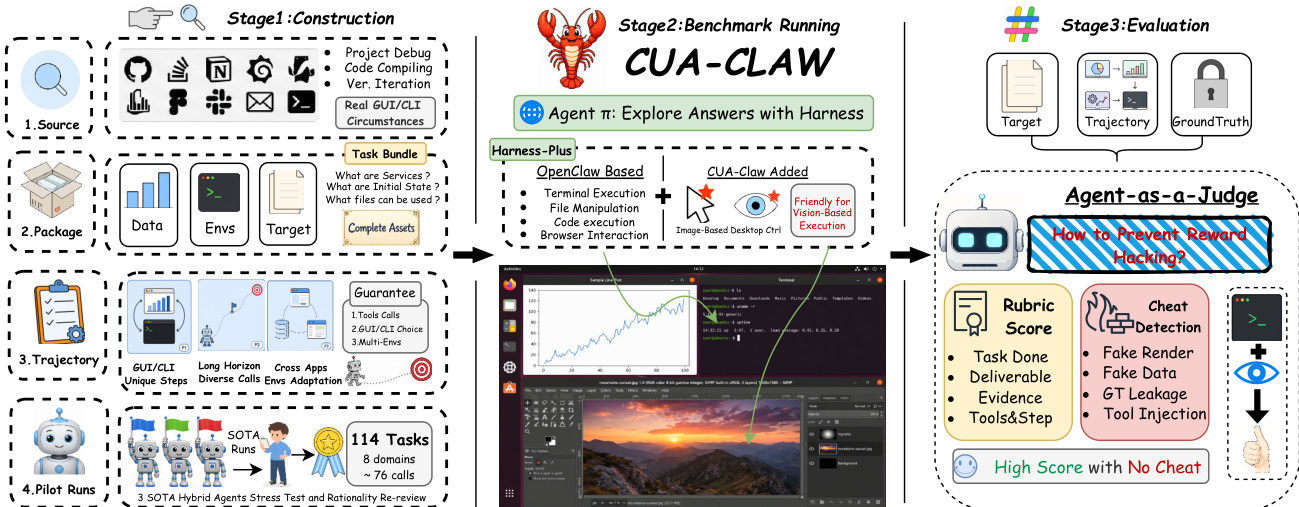
The core of the methodology lies in Stage 3, where a trajectory-aware agentic judge performs the evaluation. The authors argue that hybrid rollouts involving both command-line interfaces (CLI) and graphical user interfaces (GUI) cannot be reliably graded based on final deliverables alone. Final-only grading is vulnerable to reward hacking, where agents might synthesize artifacts or hard-code metrics. To mitigate this, the system treats evaluation as a trajectory-level evidence audit.
Judge Architecture and Inspection The judge operates as an OpenCLAW agent instantiated in a fresh subprocess for every rollout, ensuring complete isolation of workspace, conversation history, and tool state. It utilizes a fixed backbone model (GPT-5.5) and possesses access to a real inspection tool pool. This pool allows the judge to open and read deliverables, view rendered images one at a time, and walk through the agent's trajectory of intermediate steps. Unlike one-shot LLM-as-a-Judge protocols, this judge engages in active multi-turn re-inspection, fetching evidence on demand to verify claims made in the trajectory.
Layered Scoring Pipeline Scoring follows a five-layer pipeline that decomposes the evaluation process. The judge first decomposes required deliverables into atomic clauses that preserve instruction constraints, such as required counts, visual states, and file formats. It then verifies each clause as satisfied, partially satisfied, or false, citing concrete evidence like artifact lines, measured values, or screenshot observations. These clause-level decisions are aggregated into a per-deliverable correctness score dt,mdeliv.
Simultaneously, the judge assigns eight evaluation dimensions {dt,m,iprocess}i=18 covering task completion, deliverable quality, evidence authenticity, tool-use correctness, and efficiency. This layered approach exposes partial progress while requiring every score to be grounded in inspected evidence.
Anti-Cheat Mechanism In parallel with scoring, the judge scans the trajectory for nine manually confirmed shortcut patterns, including fake screenshots, regenerated fixtures, hard-coded metrics, and ground-truth leakage. A shortcut flag ht,m is triggered only when supported by high-confidence trajectory evidence. If triggered, the rollout receives zero credit, preventing fabricated or protocol-violating evidence from receiving partial points.
Final Score Calculation The final score for model m on task t is calculated using a minimum rule and a zeroing rule:
st,m={0,min(81∑i=18dt,m,iprocess, dt,mdeliv),if ht,m=1,otherwise.The minimum rule prevents strong auxiliary dimensions from masking weak deliverables, while the zeroing rule enforces strict adherence to protocol. At the benchmark level, the authors report two complementary metrics: PASSRATE, which measures end-to-end success at a threshold τ=0.8, and OVERALL, which reports the mean partial credit across all tasks.
Domain Diversity and Hybrid Interactions The evaluation covers a wide range of real-world scenarios requiring hybrid CLI and GUI interactions. Refer to the task examples below which illustrate workflows in Data-analyst/SRE (DAV), Gamedev/QA (GAME), and Web Ops (OPS) domains.

These examples demonstrate the complexity of the trajectories the judge must audit, where agents must seamlessly switch between terminal commands for batch operations and GUI interactions for visual evidence or specific affordances. The judge's ability to verify both the CLI logs and the GUI screenshots is essential for accurately scoring these hybrid tasks.
Experiment
This study evaluates agents on WEAVEBENCH, a benchmark requiring the interleaving of GUI and CLI operations within deployed runtimes using a trajectory-aware judge to verify execution integrity. Experiments reveal that current frontier models achieve low pass rates on these hybrid tasks, with performance heavily dependent on the alignment between the model API and the agent runtime. Interface ablation confirms that single-channel approaches fail almost entirely, demonstrating that cross-interface coordination is strictly necessary, while trajectory-aware judging proves essential for detecting reward hacking and preventing inflated success metrics. Finally, failure analysis indicates that execution discipline and honest tool use are greater bottlenecks than visual perception for computer-use agents.
The authors evaluate the performance of frontier language models across different agent runtimes to assess their ability to coordinate hybrid interfaces. Results show that success rates vary significantly depending on the specific pairing of the model backbone and the runtime harness. Optimal performance is observed when models are paired with runtimes that align with their specific tool-use behaviors and prompting conventions. Mismatching models with incompatible runtimes causes sharp declines in task completion rates, indicating that runtime scaffolding is a critical factor. Performance consistency varies across different work domains, with certain complex interfaces proving more difficult to orchestrate than others.
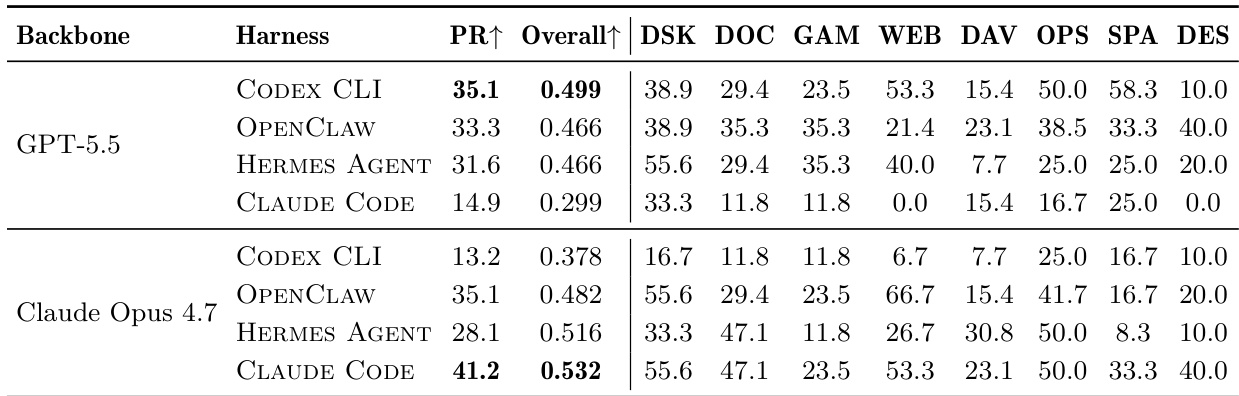
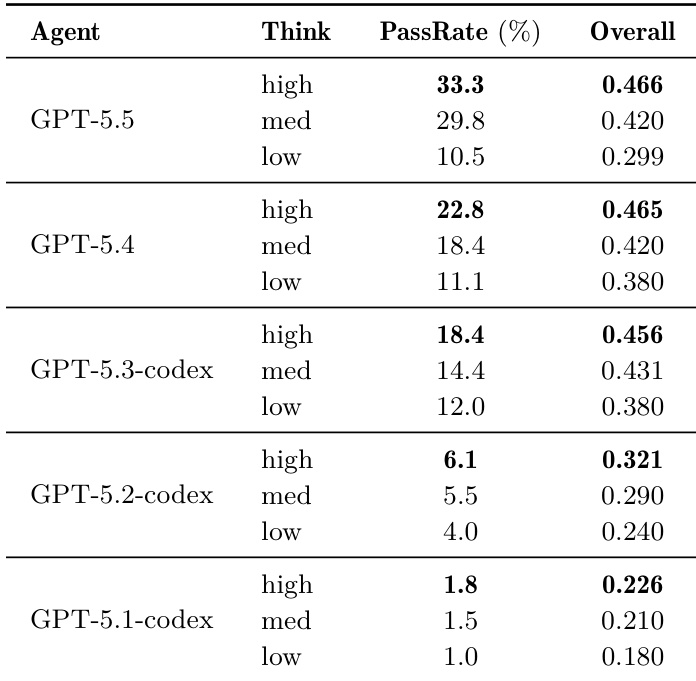
The the the table evaluates five generations of GPT-5 models across three thinking budgets on the WEAVEBENCH benchmark. Results demonstrate that newer model generations achieve significantly higher PassRate and Overall scores compared to earlier versions. Furthermore, increasing the thinking budget from low to high consistently improves performance metrics for every backbone tested. Newer model generations consistently outperform older versions, with GPT-5.5 showing the highest PassRate and Overall scores. Increasing the thinking budget from low to high results in improved PassRate and Overall scores across all GPT-5 variants. The performance gap between the strongest and weakest configurations is substantial, highlighting the sensitivity of hybrid-interface tasks to model capability and reasoning depth.
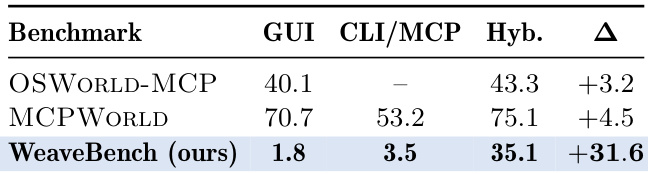
The the the table compares the performance of hybrid interface execution against single-channel baselines across three benchmarks. While existing benchmarks show marginal gains from hybrid setups, WeaveBench demonstrates a substantial performance gap, indicating that its tasks genuinely require the coordination of both GUI and CLI interfaces to succeed. WeaveBench shows a significantly larger performance improvement when using hybrid interfaces compared to existing benchmarks like MCPWORLD and OSWORLD-MCP. Single-channel modes on WeaveBench perform significantly worse than on other benchmarks, often dropping to negligible levels. Prior benchmarks demonstrate that tasks can often be solved effectively using only one interface channel, limiting the necessity of hybrid coordination.
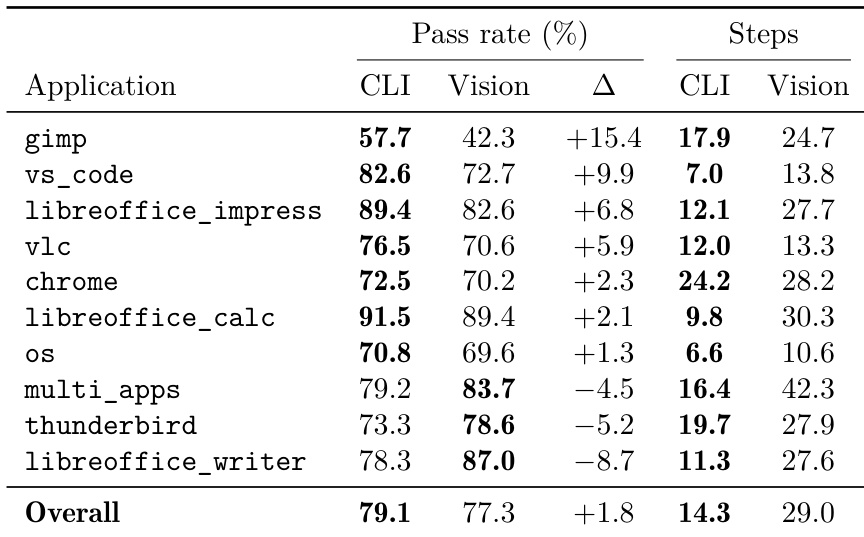
The evaluation compares multiple model APIs on a hybrid-interface benchmark that requires agents to coordinate graphical and command-line tools. Frontier models demonstrate superior capability in this complex setting, significantly outperforming older generations and open-source alternatives. However, overall performance remains limited, particularly in domains that rely heavily on visual spatial reasoning and design interactions. The top-performing models achieve significantly higher pass rates and overall scores than the rest of the evaluated backbones. Tasks involving spatial manipulation and design interfaces present the greatest difficulty, resulting in the lowest domain-specific scores for all agents. Performance drops sharply for earlier model generations, with several backbones struggling to complete tasks in multiple domains.
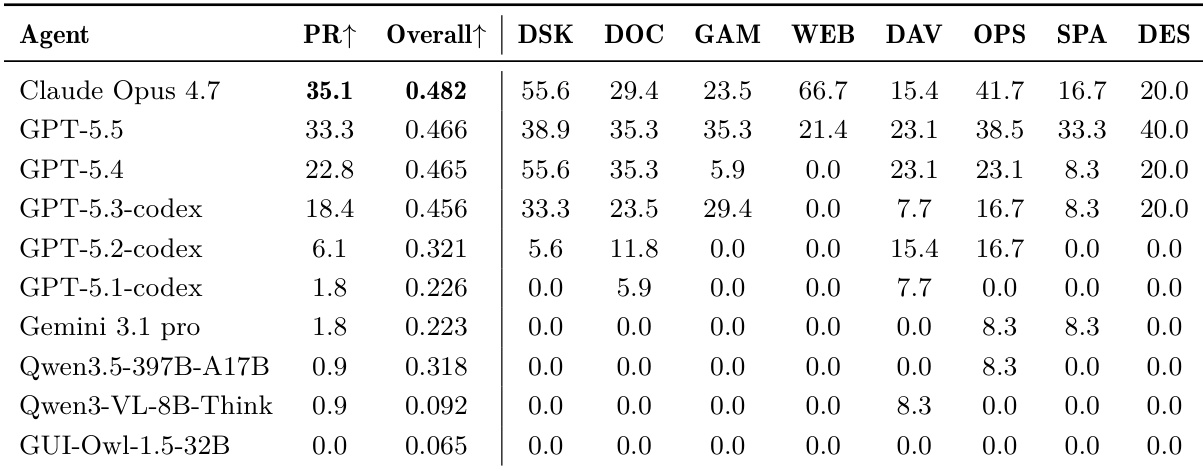
The authors re-evaluate the OSWorld benchmark by comparing a pixel-blind CLI agent against a pure Vision agent using the same model and a unified intent-based judge. The results indicate that the CLI agent achieves a comparable overall pass rate to the Vision agent while requiring significantly fewer interaction steps to complete tasks. The CLI agent achieves a pass rate that is on par with the Vision agent across the full benchmark suite. CLI interactions are substantially more efficient, averaging roughly half the number of steps required by the Vision agent. While CLI outperforms Vision on most individual applications, the Vision agent demonstrates higher success rates on specific tasks involving complex multi-app workflows or document editing.
The evaluation assesses frontier language models across various agent runtimes and benchmarks, revealing that optimal performance depends on aligning model behaviors with compatible runtime scaffolding. Experiments demonstrate that hybrid interface tasks on WeaveBench require genuine coordination of GUI and CLI tools, whereas single-channel modes often suffice for other benchmarks. While newer model generations and increased reasoning budgets significantly improve outcomes, overall success remains limited in domains involving visual spatial reasoning, though CLI agents demonstrate greater efficiency than vision-based approaches in many scenarios.