Command Palette
Search for a command to run...
MiniMax Sparse Attention
MiniMax Sparse Attention
Abstract
Ultra-long-context capability is becoming indispensable for frontier LLMs: agentic workflows, repository-scale code reasoning, and persistent memory all require the model to jointly attend over hundreds of thousands to millions of tokens—yet the quadratic cost of softmax attention makes this untenable at deployment scale. We introduce MiniMax Sparse Attention (MSA), a blockwise sparse attention built upon Grouped Query Attention (GQA). A lightweight Index Branch scores key-value blocks and independently selects a Top-k subset for each GQA group, enabling group-specific sparse retrieval while maintaining efficient block-level execution; the Main Branch then performs exact block-sparse attention over only the selected blocks. Designed around a principle of simplicity and scalability, MSA is deliberately streamlined, making it straightforward to deploy efficiently across a broad range of GPUs. To translate sparsity into practical speedups, we co-design MSA with a GPU execution path that uses exp-free Top-k selection and KV-outer sparse attention to improve tensor-core utilization under block-granular access. On a 109B-parameter model with native multimodal training, MSA performs on par with GQA while reducing per-token attention compute by 28.4x at 1M context. Paired with our co-designed kernel, MSA achieves 14.2x prefill and 7.6x decoding wall-clock speedups on H800.
One-sentence Summary
The authors introduce MiniMax Sparse Attention (MSA), a blockwise sparse attention mechanism built upon Grouped Query Attention (GQA) featuring a lightweight Index Branch for Top-k block selection that reduces per-token attention compute by 28.4x at 1M context on a 109B-parameter model and achieves 14.2x prefill and 7.6x decoding speedups on H800 when paired with co-designed GPU kernels.
Key Contributions
- MiniMax Sparse Attention (MSA) is introduced as a blockwise sparse attention mechanism built upon Grouped Query Attention, utilizing a lightweight Index Branch to select top-k key-value blocks for each group. The design maintains efficient block-level execution while enabling group-specific sparse retrieval through max-pooling scoring and retaining the most recent block for stability.
- MSA is co-designed with a specialized GPU execution path that employs exp-free Top-k selection and KV-outer sparse attention to translate theoretical sparsity into practical speedups. This approach improves tensor-core utilization under block-granular access and fuses auxiliary computations to handle skewed block popularity without atomic updates.
- Experiments on a 109B-parameter Mixture of Experts model trained with a 3T-token budget demonstrate that MSA matches Grouped Query Attention on downstream benchmarks. MSA achieves 14.2x prefill and 7.6x decoding wall-clock speedups on H800 GPUs while reducing per-token attention compute by 28.4x at 1M context.
Introduction
As large language models shift toward long-horizon agentic workflows, ultra-long context windows become critical for tasks such as production code deployment and web navigation. However, standard softmax attention creates severe compute and memory bottlenecks due to quadratic scaling, and existing hybrid or sparsified architectures often fail to balance quality with efficiency. The authors present MiniMax Sparse Attention, which retains essential sparse softmax components to maximize hardware reuse while employing blockwise token selection. They further co-design the algorithm with specialized GPU kernels to enable efficient execution, delivering significant speedups at 1M context length while matching the performance of Grouped Query Attention.
Method
The authors introduce MiniMax Sparse Attention (MSA), a blockwise sparse attention mechanism designed to scale Grouped Query Attention (GQA) to ultra-long contexts. The core architecture decomposes the attention layer into two distinct components: a lightweight Index Branch responsible for selecting relevant context, and a Main Branch that performs the actual attention computation. This design allows the model to maintain efficient block-level execution while dynamically adapting the receptive field.
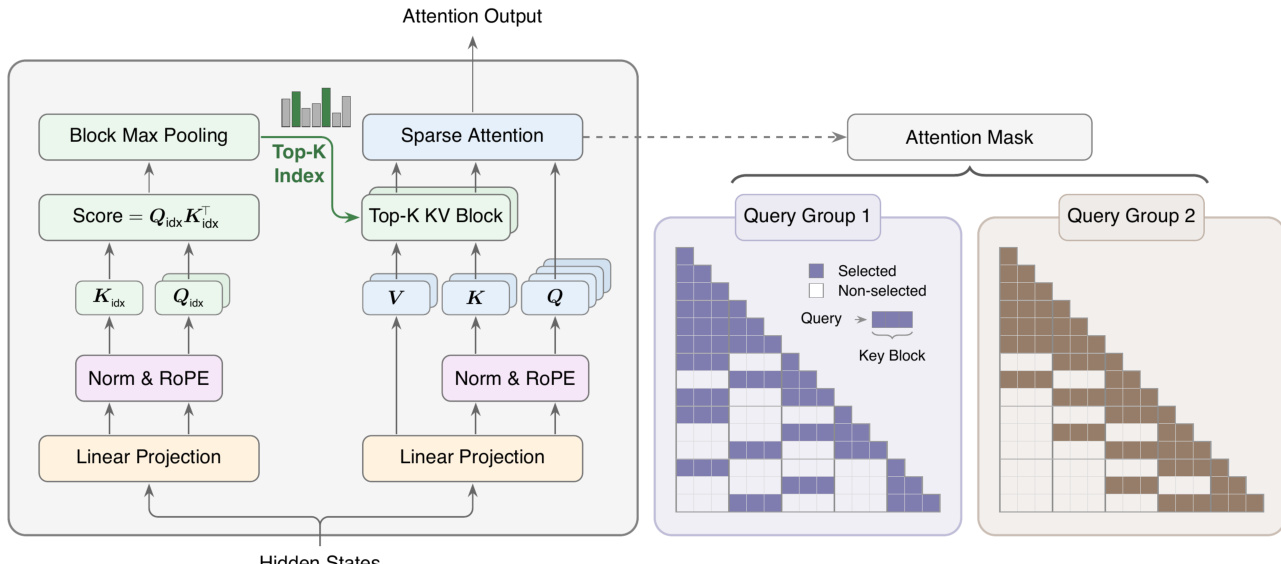
As illustrated in the framework diagram, the process begins with the input hidden states passing through linear projections and normalization layers. The architecture then splits into the Index Branch and the Main Branch. The Index Branch operates independently for each GQA group to identify the most relevant key-value blocks from the causal context. It first computes a score for every visible key token using a dot-product between the index query and index key vectors. To reduce routing overhead and ensure regular memory access, these token-level scores are aggregated to the block level using Block Max Pooling. The system then selects the Top-K blocks with the highest scores for each query group. Notably, the local block containing the current query position is always included in the selection to preserve immediate context.
Once the block indices are determined, the Main Branch executes the attention mechanism. Instead of attending to the full sequence, it restricts the softmax attention calculation to only the tokens residing within the selected blocks. This significantly reduces the computational complexity from quadratic to linear with respect to the sequence length, provided the number of selected blocks remains small. The output is generated by gathering the Key and Value vectors from the selected blocks and computing the standard scaled dot-product attention.
To train this two-stage system effectively, the authors employ a specialized procedure. Since the Top-K selection operation is non-differentiable, the Index Branch cannot be trained directly via the standard language modeling loss. Instead, the authors utilize a KL divergence loss to align the probability distribution of the Index Branch with that of the Main Branch on the selected tokens. This auxiliary loss provides a direct learning signal for the indexer to mimic the attention patterns of the full-attention backbone. To ensure stability and prevent the auxiliary loss from disrupting the main model parameters, the Gradient Detach mechanism is applied to the Index Branch input. This ensures the KL loss updates only the index projections. Additionally, an Indexer Warmup phase is used where the model initially runs full attention to initialize the index projections before switching to sparse attention. This combination of architectural design and training strategy enables MSA to achieve significant speedups without compromising model performance.
Experiment
The experiments evaluate a sparse attention mechanism across two 109B-scale training routes on a multimodal model against full-attention baselines. Results confirm that the design preserves training stability and model quality while delivering substantial efficiency gains via optimized top-k selection and reduced computational FLOPs. Further analysis indicates that dynamic token selection surpasses fixed patterns and that critical attention structures such as sinks arise naturally without requiring hard-coded architectural priors.
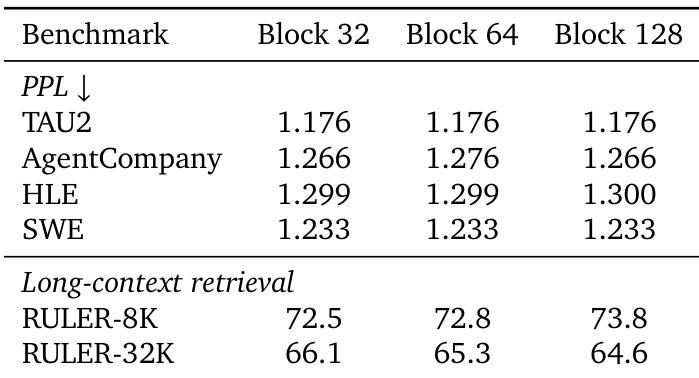
The authors investigate the impact of varying key-value block sizes on model performance, comparing configurations of 32, 64, and 128 to balance efficiency and quality. Results indicate that perplexity metrics remain stable across different block sizes, suggesting that larger blocks can be utilized to improve kernel efficiency without significant degradation in general language capabilities. Long-context retrieval performance varies by task length, with the 8K setting showing improvement at larger block sizes while the 32K setting shows a slight decline. Perplexity benchmarks including TAU2 and SWE show consistent results across all tested block sizes. Long-context retrieval on the 8K setting improves slightly as the block size increases from 32 to 128. Retrieval performance on the 32K setting shows a gradual decrease as block size increases, though the overall impact is reported as limited.
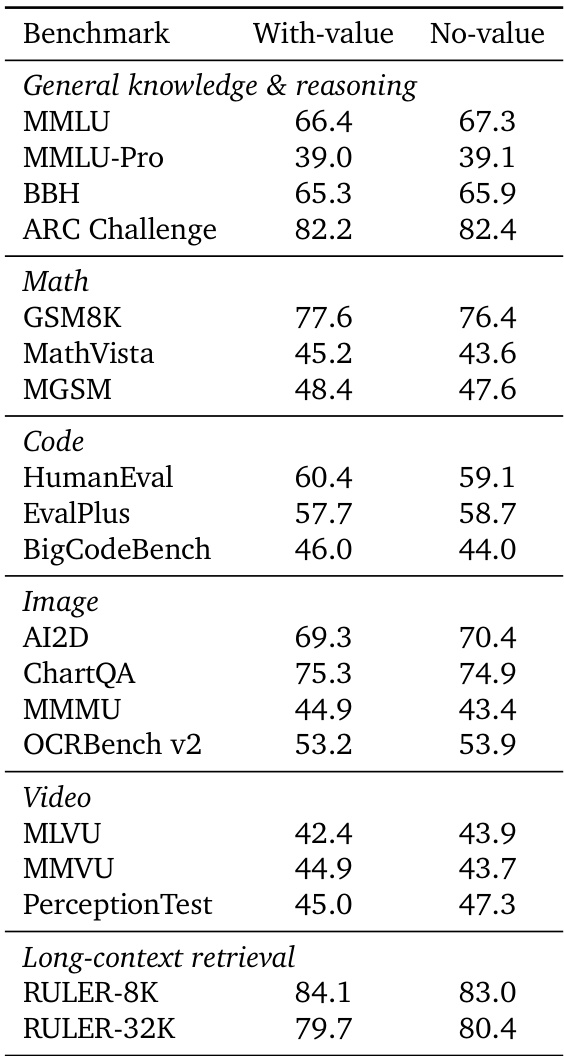
The authors compare a model configuration with an index value head against a variant without it to evaluate the necessity of the additional computation. Results indicate that removing the value head does not lead to systematic degradation, as performance differences are small and benchmark-dependent. The variant without the value head performs better on general reasoning, while the version with the value head retains advantages in math and code tasks. The no-value variant achieves superior scores on general knowledge and reasoning benchmarks. The with-value variant demonstrates stronger performance on math and code evaluation tasks. Results on multimodal and long-context retrieval benchmarks are mixed, showing no consistent dominance for either configuration.
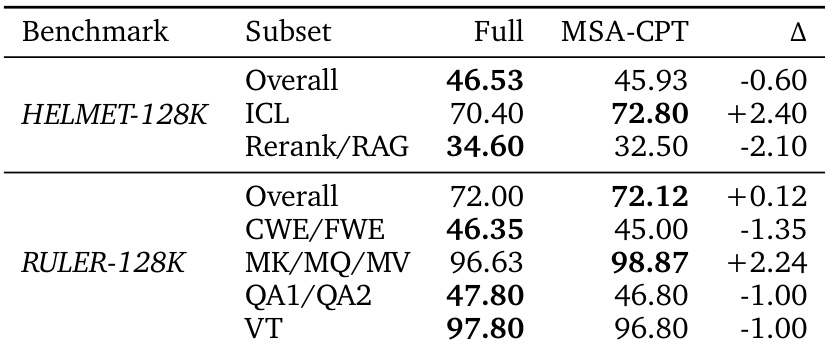
The authors evaluate the MSA-CPT model on long-context benchmarks to assess its effectiveness after an extension training stage. Results indicate that the sparse model remains competitive with the Full-Attention baseline, preserving long-context capabilities despite operating under a highly restricted attention budget. MSA-CPT maintains competitive overall scores on both HELMET and RULER benchmarks relative to the Full baseline. Performance improvements are observed in specific categories such as In-Context Learning and multi-hop reasoning tasks. While some retrieval and question-answering subsets show slight decreases, the model generally preserves long-context capabilities.
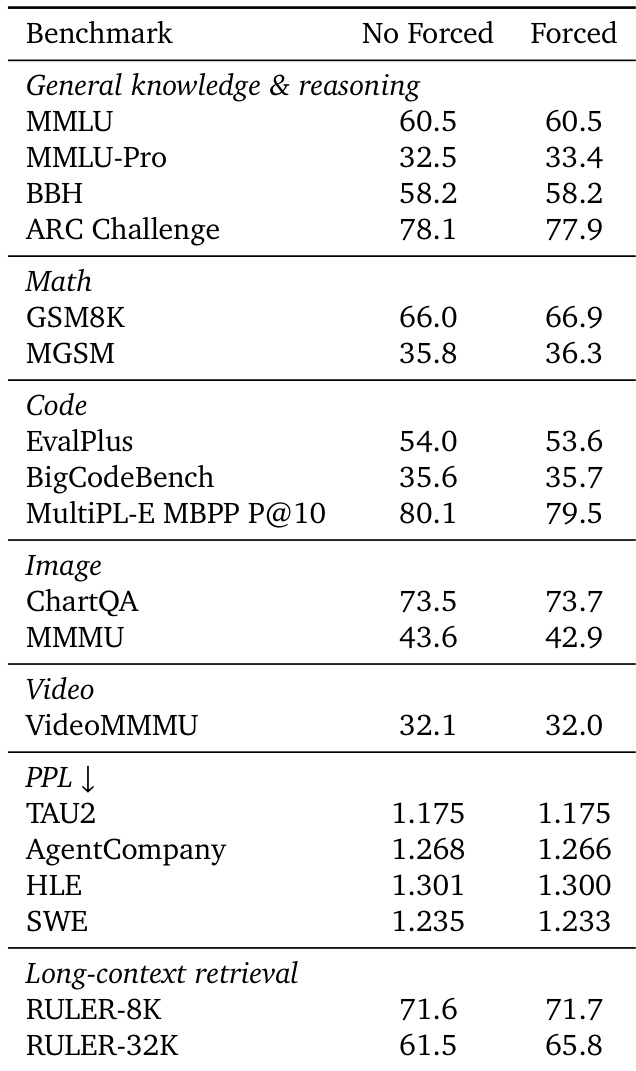
The authors evaluate the necessity of hard-coding specific attention blocks, such as the sequence start and local windows, by comparing a model with these constraints against one without. Results show that removing these forced selections has negligible effects on standard benchmarks for reasoning, code, and perplexity. This indicates that the sparse attention mechanism naturally learns to prioritize important tokens like attention sinks without explicit intervention. Performance on general knowledge and reasoning benchmarks remains consistent regardless of whether specific blocks are forced. Perplexity metrics show comparable stability between the forced and unforced configurations. The model autonomously develops attention patterns for sinks and local context, eliminating the need for hard-coded selection rules.
The authors benchmark a specialized top-k selection kernel against standard torch.topk and TileLang implementations on an H800 GPU. The results demonstrate that their method consistently achieves the lowest latency across all tested sequence lengths and block configurations. The performance advantage is particularly pronounced in the deployed setting, where the speedup over baselines is maximized. The proposed kernel is consistently faster than both torch and TileLang across all tested settings. The largest performance gains are observed in the deployed configuration. The efficiency advantage is preserved even as sequence length scales up to 512K and block counts increase.

The authors evaluate architectural choices and efficiency optimizations by testing key-value block sizes, value head configurations, and attention mechanisms against standard baselines. Results indicate that larger block sizes improve efficiency without degrading general capabilities, while removing the index value head creates task-dependent trade-offs rather than systematic loss. Additionally, the sparse attention model maintains competitive long-context performance against full attention baselines and autonomously learns token prioritization without hard-coded constraints, while a specialized top-k kernel achieves superior latency across scaled sequence lengths.