Command Palette
Search for a command to run...
OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
Abstract
Cloning camera motion from reference videos is an important task in video generation, as videos provide intuitive and precise control. Existing methods either directly use parametric representations that fail to handle multi-shot generation or synthesize cross-paired data, which suffer from data scarcity, resulting in poor performance in complicated camera motion cloning. To address these issues, we introduce a general camera motion representation that encodes cameras as grid motion videos. This camera grid represents the camera parameters visually and supports the integration of diverse trajectories for multi-shot video generation. Building upon this, we propose OmniDirector, a unified framework trained on a million-scale camera grid-video pairs that coordinates characters, actions, and cameras to provide director-level control for multimodal diffusion transformers. Furthermore, we design a novel hierarchical prompt expansion agent that harmoniously integrates different control signals by systematically describing camera motion and visual content through understanding signal relationships. Extensive experiments demonstrate the superior performance and outstanding controllability of our framework.
One-sentence Summary
OmniDirector is a unified framework trained on million-scale camera grid-video pairs that enables general multi-shot camera cloning without cross-paired data by encoding cameras as grid motion videos and utilizing a novel hierarchical prompt expansion agent to coordinate characters, actions, and cameras to provide director-level control for multimodal diffusion transformers, with extensive experiments demonstrating superior performance and controllability.
Key Contributions
- The paper introduces a general camera motion representation that encodes cameras as grid motion videos to support the integration of diverse trajectories for multi-shot video generation.
- OmniDirector is presented as a unified framework trained on million-scale camera grid-video pairs that coordinates characters, actions, and cameras to provide director-level control for multimodal diffusion transformers.
- A novel hierarchical prompt expansion agent is designed to harmoniously integrate different control signals by systematically describing camera motion and visual content through understanding signal relationships. Extensive experiments demonstrate the superior performance and outstanding controllability of the framework.
Introduction
Camera motion is essential for shaping narrative depth in video generation, yet achieving precise control remains challenging. Existing parametric methods fail to handle multi-shot transitions and struggle with semantic alignment, while implicit approaches relying on cross-paired data suffer from scarcity and information leakage. To address these issues, the authors introduce OmniDirector, a unified framework designed for Multi-Modal Diffusion Transformers. They propose a camera grid representation that encodes camera parameters as motion videos in an empty 3D scene to decouple motion from content. This approach enables training on million-scale data without requiring cross-paired samples. Additionally, they design a hierarchical prompt expansion agent to seamlessly integrate camera motion with subject and object controls during inference.
Method
The authors propose OmniDirector, a framework designed to achieve general multi-shot camera cloning by decoupling camera motion from scene content. The core innovation is the Camera Grid representation, which abstracts complex camera movements into a visual signal that can be processed alongside standard video content.
Refer to the framework diagram below:
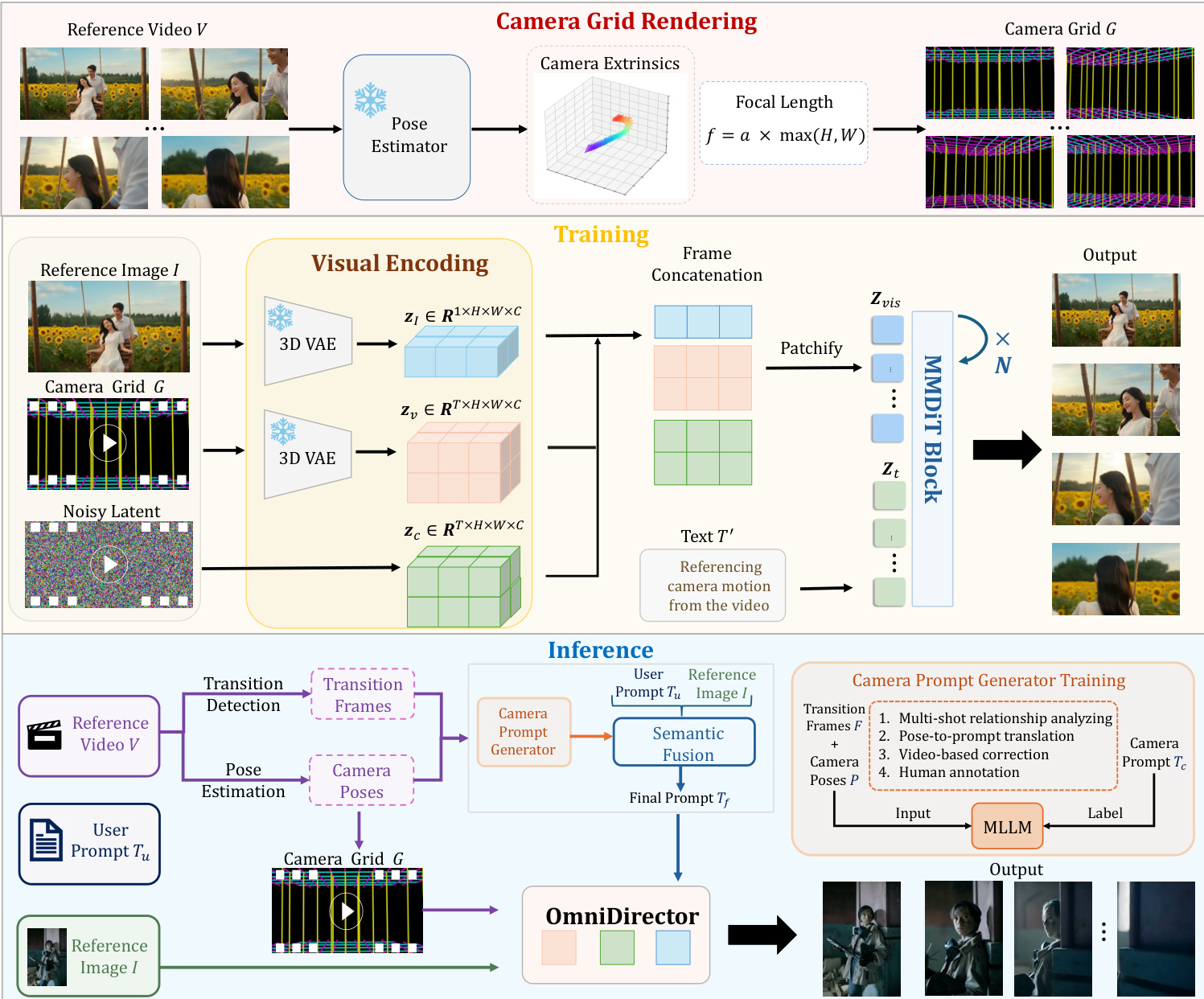
The method begins with Camera Grid Rendering. To simulate spatial transformations, the authors model the environment as an empty room containing only 3D grid lines. Specifically, they generate grid points on X-Z planes to represent the floor and ceiling, and construct vertical line segments to form a tubular boundary structure surrounding the camera trajectory. This creates a visual tunnel wall effect that clearly presents the geometric structure and motion path. For special effects like fisheye distortion or dolly zoom, the rendering scheme is modified using specific optical models, such as the Kannala–Brandt model, to reproduce characteristic visual distortions.
During the training phase, the architecture leverages a 3D Variational Autoencoder (3D VAE) to encode the inputs. The reference image I, the camera grid G, and the noisy video latent Zv are encoded into latent representations zI, zc, and zv. These modalities are concatenated along the frame dimension to form a unified spatiotemporal representation zvis=Concat(zI,zv,zc). This combined latent is then patchified into token sequences Zvis. Simultaneously, the text condition T′ is processed through a text encoder to produce text tokens Zt. The model utilizes a Multimodal Diffusion Transformer (MMDiT) backbone where visual and text tokens interact through joint attention mechanisms, allowing text semantics to modulate the visual generation process while maintaining alignment between visual signals. To ensure the model strictly adheres to the camera grid geometry, a self-reconstruction objective is incorporated into 30% of the training samples. In these cases, the target video is replaced by the camera grid itself, forcing the model to parse the geometric structure rather than relying on spurious correlations.
For inference, the system employs a Hierarchical Prompt Expansion Agent to harmonize heterogeneous control signals. First, a Camera Prompt Generator analyzes transition frames and camera poses to produce a specific camera motion description Tc. This description is then fused with the user prompt Tu and the reference image I via a Semantic Fusion module to create a final prompt Tf. This unified prompt guides the OmniDirector model to generate the output video. Additionally, an Adaptive Classifier-Free Guidance strategy is applied, where the visual unconditional input is set to a black background and the text prompt includes a completely static camera description. A coarse-to-fine denoising schedule is also used, injecting camera grid features during the high-noise regime to establish global structure before refining local details.
Experiment
OmniDirector is evaluated on a diverse validation set to assess camera control accuracy, shot transition consistency, and content leakage against state-of-the-art baselines. Comparative results demonstrate that the proposed method surpasses existing approaches by faithfully cloning complex trajectories and maintaining semantic coherence in multi-shot scenarios without significant content leakage. Ablation studies and emergent capability tests further validate that the design choices enhance signal fusion and enable generalization to diverse input signals like raw video without retraining.
The authors evaluate their proposed method, OmniDirector, against several state-of-the-art baselines across camera control, transition accuracy, and leakage rates. The results indicate that their approach consistently outperforms competitors, achieving the highest precision in camera pose estimation and shot transitions while minimizing unwanted reference video leakage. The proposed method achieves the best performance in camera accuracy metrics, showing the lowest rotation and translation errors among all compared approaches. OmniDirector demonstrates superior transition accuracy with the highest temporal and semantic precision, while baseline methods lack support for semantic evaluation. The approach significantly reduces leakage rates at both frame and shot levels, contrasting with other methods that exhibit substantial content leakage from the reference video.

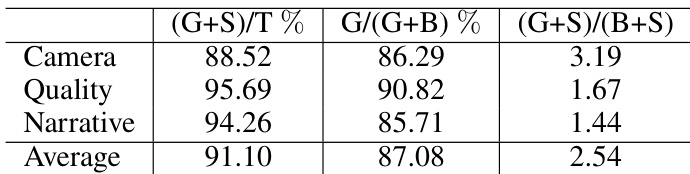
The authors present a pairwise comparison evaluating camera control, visual quality, and narrative consistency against a baseline method. The results indicate superior performance across all dimensions, with the proposed approach achieving high preference rates and favorable outcome ratios particularly in visual quality and camera trajectory adherence. Visual quality received the highest proportion of favorable or equivalent ratings compared to the baseline. Camera control exhibited the strongest ratio of positive to negative outcomes among the evaluated categories. Narrative consistency demonstrated solid performance with high agreement rates, though with a lower favorable ratio than the other dimensions.
The ablation study evaluates the contributions of Semantic Fusion, Transition Prompt Engineering, and Adaptive CFG to the overall performance of the OmniDirector model. Results indicate that the complete configuration achieves superior camera accuracy, transition precision, and minimal content leakage compared to removing individual components. Specifically, the absence of inter-shot modeling severely impacts semantic consistency during transitions, while removing adaptive guidance degrades camera motion fidelity. The full model configuration yields the best camera accuracy and lowest leakage rates across all settings. Excluding transition prompt engineering causes a significant degradation in the semantic precision of shot transitions. Semantic fusion is essential for reducing reference video leakage and maintaining accurate camera pose estimation.

The authors evaluate OmniDirector against leading baselines using quantitative metrics and human pairwise comparisons to assess camera control, transition accuracy, visual quality, and narrative consistency. Comparative results indicate the proposed approach consistently outperforms competitors by achieving superior precision in camera pose estimation and shot transitions while significantly minimizing reference video leakage. Additionally, an ablation study confirms that the full model configuration is essential for maintaining semantic consistency and camera motion fidelity, as removing individual components leads to notable performance degradation.