Command Palette
Search for a command to run...
MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
Abstract
We present MaxProof, a population-level test-time scaling framework for competition-level mathematical proof in the MiniMax-M3 series. M3 first trains three proof-oriented capabilities—proof generation, proof verification, and critique-conditioned proof repair—using a defense-in-depth generative verifier engineered for low false-positive rate. These capabilities are merged into a single released M3 model. At test time, MaxProof treats the model as a generator, verifier, refiner, and ranker, searches over a population of candidate proofs, and returns one final proof through tournament selection. With MaxProof test-time scaling, the M3 model reaches 35/42 on IMO 2025 and 36/42 on USAMO 2026, exceeding the human gold-medal threshold on both.
One-sentence Summary
MaxProof is a population-level test-time scaling framework for the MiniMax-M3 series that utilizes generative-verifier reinforcement learning to train proof generation, verification, and critique-conditioned repair capabilities, employing tournament selection over a population of candidate proofs to achieve scores of 35/42 on IMO 2025 and 36/42 on USAMO 2026, exceeding the human gold-medal threshold on both.
Key Contributions
- This work introduces MaxProof, a population-level test-time scaling framework for competition-level mathematical proofs within the MiniMax-M3 series. The system trains three proof-oriented capabilities using a defense-in-depth generative verifier engineered for a low false-positive rate before merging them into a single released model.
- During inference, the framework treats the model as a generator, verifier, refiner, and ranker to search over a population of candidate proofs. A final proof is selected through a tournament selection process that aggregates these capabilities.
- Experimental results demonstrate that the M3 model achieves scores of 35/42 on IMO 2025 and 36/42 on USAMO 2026 with this scaling approach. These performance metrics exceed the human gold-medal threshold on both competition benchmarks.
Dataset
- Dataset Composition and Sources
- The authors draw primary training data from public competition sources featuring problem statements and human-written reference solutions.
- Specialized expert models utilize data harvested directly from the Proof Expert's training runs to eliminate additional annotation costs.
- Key Subset Details
- Proof Expert: Problems include annotations for mathematical domains and solving tricks. The team excludes held-out evaluation sets like IMO 2025 and applies near-duplicate filtering.
- Verifier Expert: This set contains tuples of problems, candidates, analyses, errors, and verdicts. The authors select critiques paired with the pessimistic-min score to align with the Proof Expert's reward signal.
- Fixer Expert: This subset captures flawed proofs identified by verdicts such as minor_gaps or fundamentallyWrong.
- Processing and Balancing
- Grading schemes are generated by a strong model using few-shot prompts against human exemplars.
- Difficulty filtering removes problems the previous-generation M2.7 model solves reliably.
- Domain balancing ensures algebra, combinatorics, geometry, and number theory are represented evenly.
- Trick-frequency control smooths high-frequency occurrences while preserving the long tail of rare techniques.
- Class rebalancing adjusts the Verifier dataset to avoid over-representation of extreme verdicts.
- Training Splits and Leakage Prevention
- Data for the Verifier and Fixer experts is split by prompt rather than candidate to prevent leakage from the Proof Expert's distribution.
- The objective avoids a uniform dataset mix to preserve structural information while ensuring no single domain or trick dominates the training process.
Method
The MaxProof framework introduces the MiniMax-M3 model, which is trained to master three core proof-oriented capabilities: proof generation, proof verification, and critique-conditioned proof repair. These capabilities are distilled into three specialized modules known as the Proof Expert, the Verifier Expert, and the Fixer Expert. During the training phase, these experts are developed independently before being merged into a single released model. At inference time, the MaxProof system activates the relevant capabilities through prompting to perform population-level test-time scaling. The complete pipeline, from expert training to the evolutionary search process, is illustrated in the framework diagram.
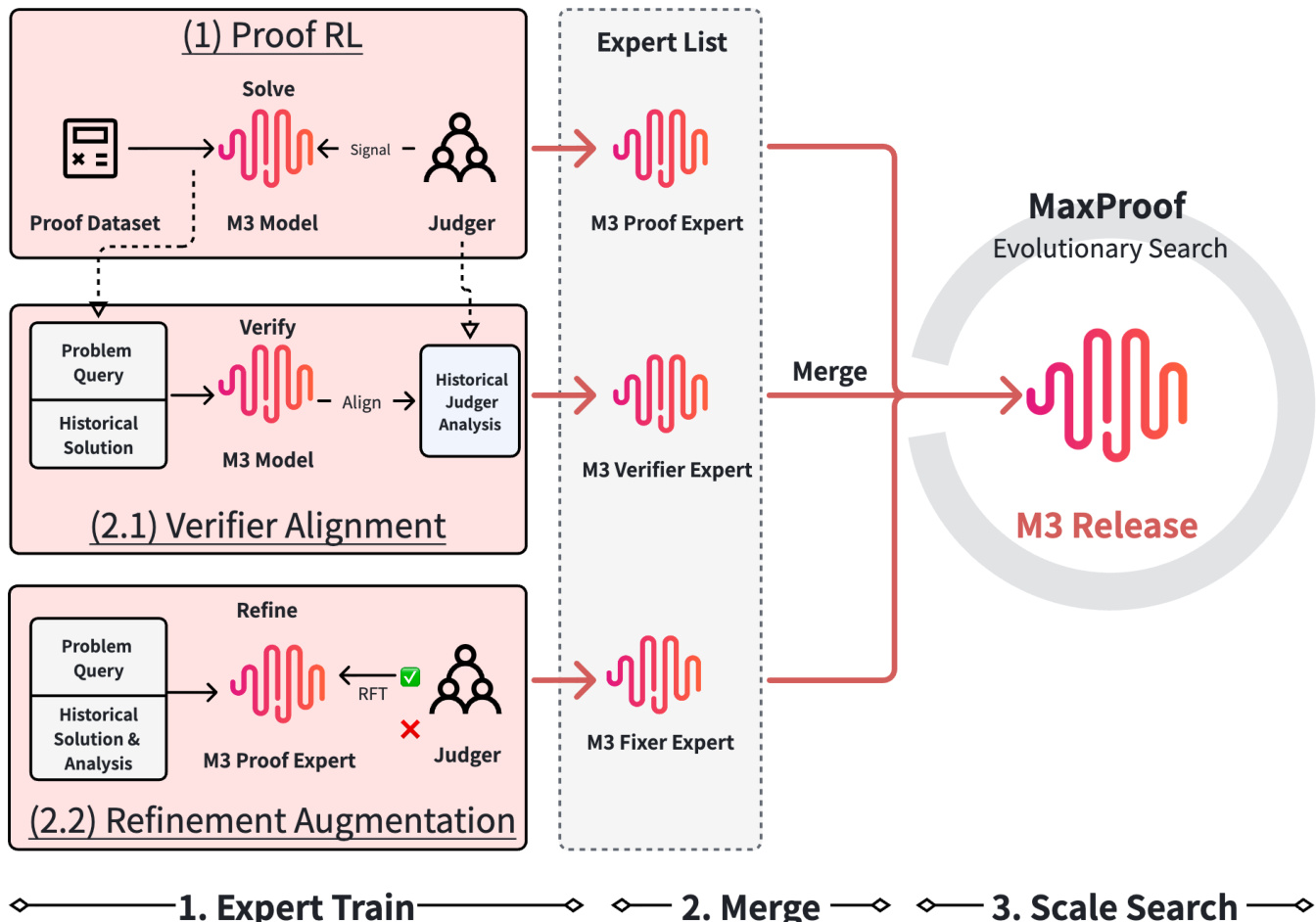
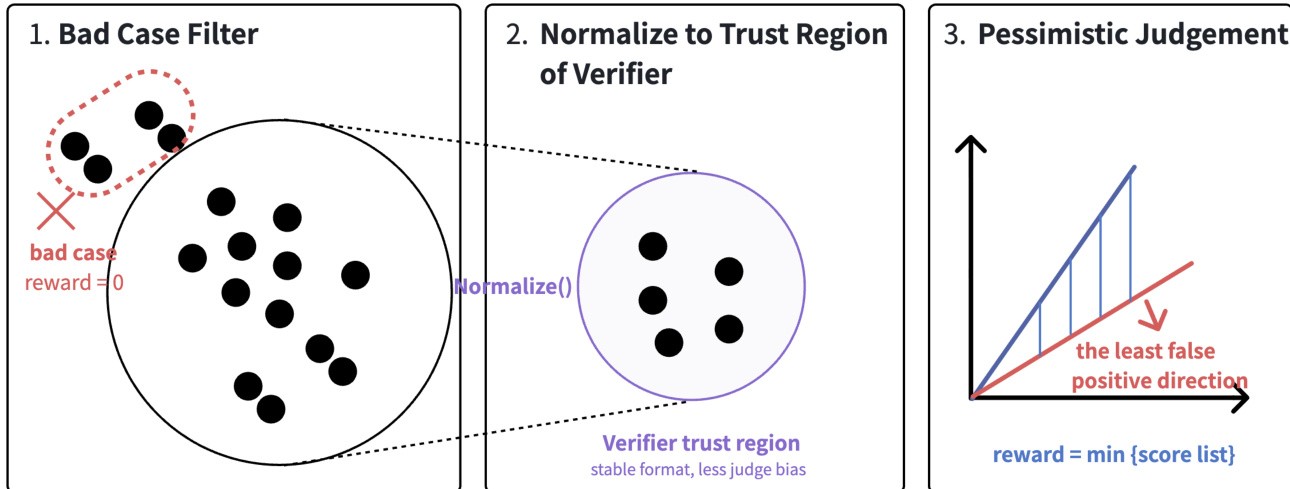
The Proof Expert is trained using long-horizon Reinforcement Learning (RL) to generate proofs that are occasionally close to correct. The reward signal for this process is provided by a defense-in-depth generative verifier. This verifier is critical because it defines the reward landscape for the policy. To ensure stability and prevent reward hacking, the verifier employs a multi-layer defense strategy. This includes filtering bad cases, normalizing solutions to a trust region to reduce format bias, and applying pessimistic judgment through multi-judge scoring. The verifier pipeline details these defensive layers.
The training objective for the Proof Expert utilizes CISPO, an off-policy REINFORCE-style algorithm. For a problem p, a group of G candidate proofs is sampled, and each receives a verifier reward Ri∈[0,7]. The group-normalized advantage Ai is calculated as:
Ai=σR+ϵRi−μR,μR=G1j=1∑GRj,σR=G1j=1∑G(Rj−μR)2To prevent updates from noisy signals, a group-level std-threshold filter is applied, ensuring that a rollout group contributes to the update only if σR>τstd.
The Verifier Expert is trained to perform aligned error finding rather than simple score prediction. It is prompted to produce a structured output containing an <assessment> block, an <errors> block, and a <verdict>. This formulation ensures the model reads the proof to localize errors before committing to a verdict. The Fixer Expert is trained via Rejection-Sampling Fine-Tune (RSFT) on triples of (problem, flawed_proof, verification_analysis). It learns to repair proofs by addressing specific critiques while preserving correct parts, using the same conservative verifier to validate successful repairs.
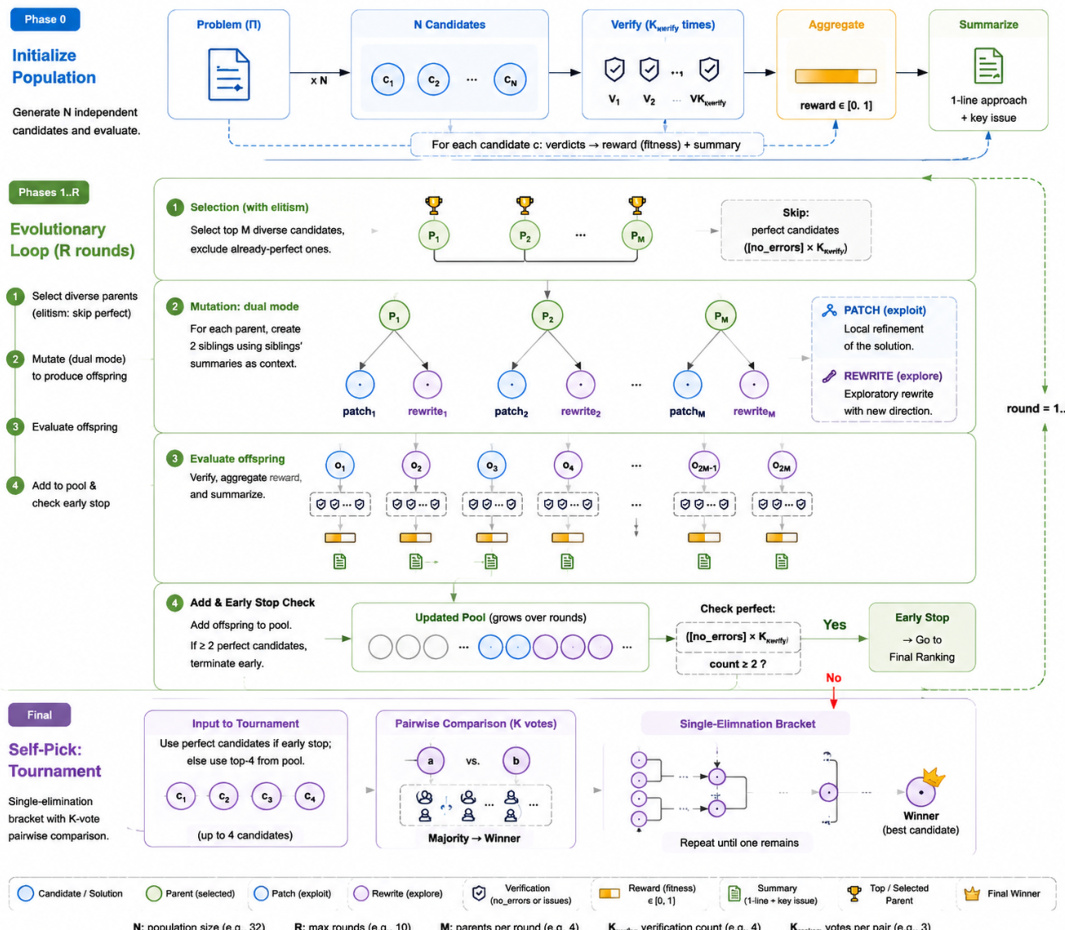
At test time, MaxProof treats the merged M3 model as a generator, verifier, refiner, and ranker to scale performance through population search. The process begins by initializing a population of N independent candidates. In each round of the evolutionary loop, the system selects diverse parents, applies dual-mode mutation (PATCH for local refinement and REWRITE for exploratory exploration), and evaluates the offspring using the verifier. The archive is updated with new candidates, and the process continues until an early stop condition is met or the round budget is exhausted. Finally, a pairwise tournament selects the best candidate from the top archive entries. The detailed evolutionary loop and selection process are shown in the diagram below.
The Proof Expert generates outputs in a structured, step-by-step format that mirrors human mathematical reasoning. This includes sections for understanding the problem, determining key conditions, analyzing specific cases, and eliminating alternative possibilities. An example of this policy output structure demonstrates how the model breaks down complex tiling problems into logical steps, explicitly checking for necessary and sufficient conditions.

Experiment
The M2 cycle identified critical reward hacking vulnerabilities in single judge verification, prompting the development of a layered M3 verifier pipeline designed to suppress format manipulation and semantic shortcuts. Evaluation demonstrates that while the base M3 model achieves competitive standalone scores on mathematical proof benchmarks, the MaxProof framework substantially improves contest performance by leveraging test time scaling to refine and select high quality proofs. These findings confirm that structured system design can effectively narrow the gap to frontier models, although challenges remain in selection accuracy and solving problems beyond the base model capability ceiling.
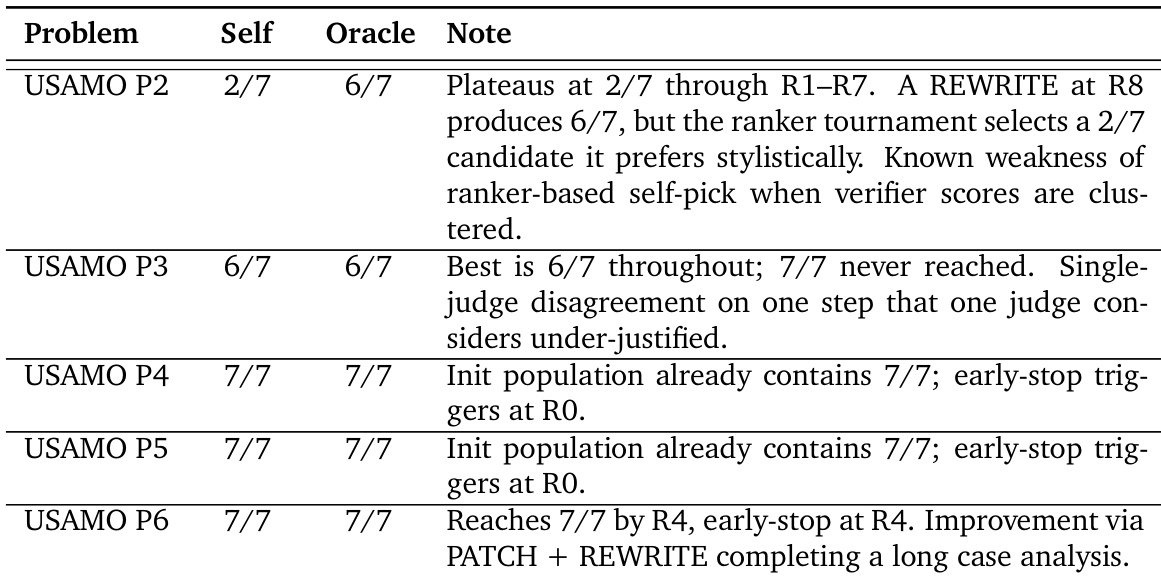
The the the table details the per-problem performance of the M3 model combined with the MaxProof framework, comparing the system's final selection against the best solution found in the search population. It highlights a discrepancy where the system selected a suboptimal solution on one problem despite a better one being available, while successfully finding perfect proofs on others. The system achieved perfect scores on several problems, with early stopping triggered immediately for some due to the initial population containing correct solutions. A significant selection loss occurred on USAMO P2, where the ranker preferred a stylistically different but lower-scoring candidate over a higher-scoring solution found later in the search. USAMO P3 remained at a high but imperfect score for both self-pick and oracle-best, indicating the model failed to generate a perfect proof within the configured search rounds.
The authors evaluate the model's performance on two mathematics contests by comparing its self-selected solutions against the best solutions found within the search population. The results demonstrate that the system successfully identifies and selects perfect proofs for most problems, though specific failures in selection accuracy and base capability are observed on harder problems. The system matched the best possible search result on most problems, achieving perfect scores across both contests. One USAMO problem showed a large gap between the best available proof and the system's final selection. The hardest IMO problem resulted in zero points, suggesting the base model lacked a viable approach for that specific challenge.
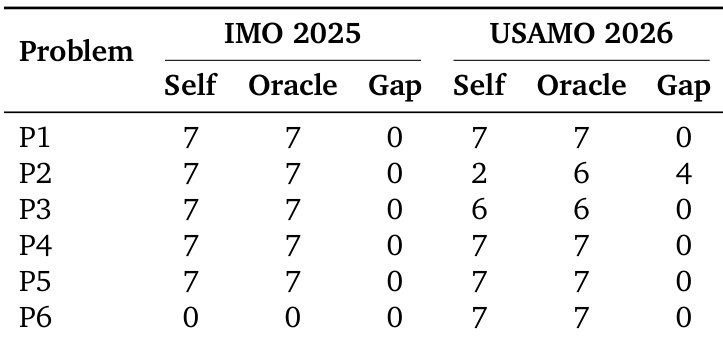
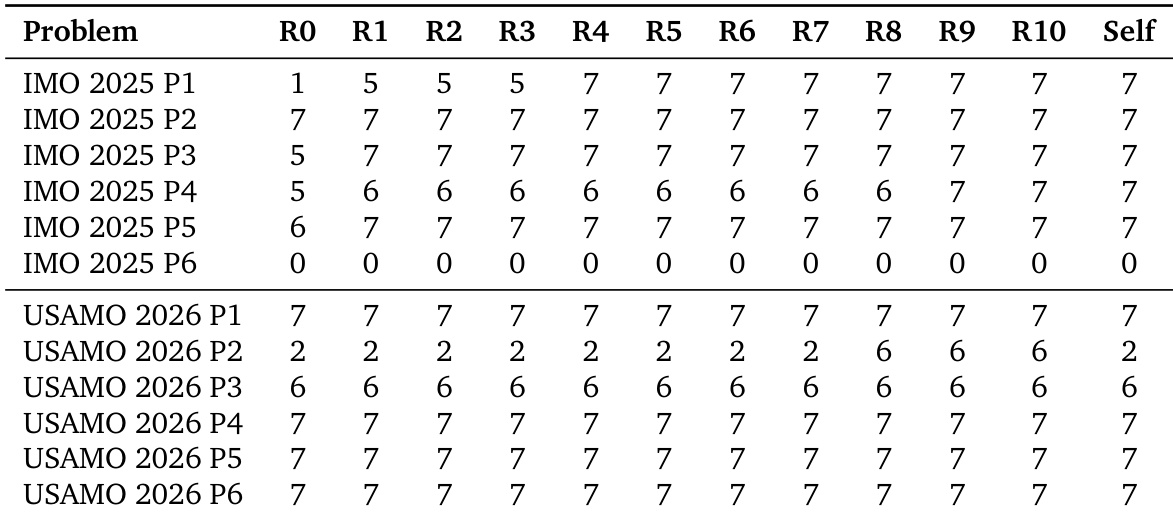
The the the table presents the performance evolution of the M3 model across multiple refinement rounds on mathematical contest benchmarks. While the majority of problems converge to the highest possible score early in the process, specific cases highlight distinct limitations including complete failure to solve, stagnation at partial credit, and selection errors where better solutions are overlooked. The majority of problems reach the maximum score within the early refinement stages. One specific problem fails to improve from the initial attempt across all rounds. One case shows the population finding a higher-scoring solution in later rounds, but the final selection fails to capture it.
The authors evaluate the merged M3 model on two mathematical proof benchmarks, comparing it against several frontier closed-source systems without using the MaxProof scaling framework. The results indicate that while M3 demonstrates strong capabilities, particularly on answer-based tasks, it still trails the leading models in proof construction quality. M3 outperforms Opus 4.7 on both the proof construction and answer benchmarks. The model trails the top-performing systems like GPT-5.5 and Gemini 3.1 Pro across both evaluation sets. The performance gap between M3 and the leading models is narrower on the answer benchmark than on the proof construction benchmark.

The authors evaluate the M3 model on IMO 2025 and USAMO 2026, comparing a standard one-shot setup against the MaxProof test-time scaling framework. Results show that MaxProof provides a substantial performance boost over the baseline on both contests, with the gain appearing more pronounced on USAMO 2026. This demonstrates the framework's ability to convert base model capabilities into stronger contest-level results. MaxProof significantly outperforms the one-shot baseline on both mathematical proof benchmarks. The performance gain is larger for USAMO 2026 than for IMO 2025. The test-time scaling framework effectively stabilizes high-level problem solving.
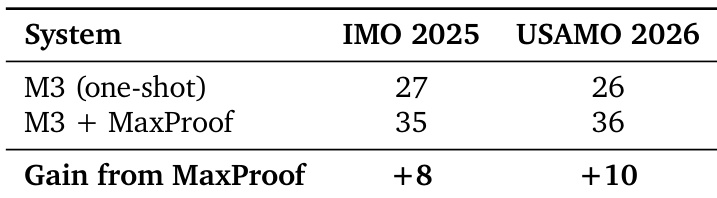
The experiments evaluate the M3 model on mathematical contest benchmarks using the MaxProof framework to compare the final selection against the best solution found in the search population and evaluate performance against other frontier systems. Results demonstrate that MaxProof provides a substantial performance boost over the standard baseline, allowing the system to achieve perfect scores on most problems despite occasional selection errors that overlook superior candidates. Although the model outperforms some competitors, it continues to trail leading closed source systems in proof construction quality, particularly on the hardest challenges where base capability limitations remain evident.