Command Palette
Search for a command to run...
SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
Abstract
Spatial reasoning, the ability to determine where objects are, how they relate, and how they move in 3D, remains a fundamental challenge for vision-language models (VLMs). Tool-augmented agents attempt to address this by augmenting VLMs with specialist perception modules, yet their effectiveness is bounded by the action interface through which those tools are invoked. In this work, we study how the design of this interface shapes the agent's capacity for open-ended spatial reasoning. Existing spatial agents either employ single-pass code execution, which commits to a full analysis strategy before any intermediate result is observed, or rely on a structured tool-call interface that often offers less flexibility for freely composing operations or tailoring the analysis to each task. Both designs offer limited flexibility for open-ended, complex 3D/4D spatial reasoning. We therefore propose SpatialClaw, a training-free framework for spatial reasoning that adopts code as the action interface.
One-sentence Summary
This work proposes SpatialClaw, a training-free framework for vision-language models that adopts code as the action interface to enable freely composing operations and address the flexibility limitations of single-pass code execution and structured tool-call interfaces in open-ended, complex 3D and 4D spatial reasoning.
Key Contributions
- This work introduces SpatialClaw, a training-free framework for spatial reasoning that adopts code as the action interface to support open-ended 3D/4D spatial reasoning. The design enables agents to write code turn-by-turn in response to intermediate execution results rather than committing to a full program beforehand.
- The study contributes domain-specific design choices through controlled comparisons against alternative action interfaces and trace-level analyses. These evaluations identify when the code action interface helps and determine which spatial analysis patterns drive performance gains.
- The framework adds no parameters to the backbone vision-language model, allowing existing models to be extended with stronger spatial reasoning ability without additional training data or fine-tuning. This configuration transfers across backbones and benchmarks without modification to increase the practical value of deployed vision-language models.
Introduction
Spatial reasoning remains a fundamental challenge for vision-language models because they struggle to compose geometric evidence like depth and motion from raw pixels alone. Prior tool-augmented agents are constrained by action interfaces that either commit to a full analysis strategy before observing intermediate results or restrict flexibility through rigid structured commands. The authors introduce SpatialClaw, a training-free framework that treats code as the action interface within a stateful Python kernel. This design enables the agent to write executable cells per step conditioned on prior outputs, allowing for flexible composition of perception results and dynamic adaptation to complex 3D and 4D tasks. Across 20 benchmarks, the system achieves significant accuracy gains without requiring model-specific fine-tuning.
Dataset
- The authors resize all input images such that the long edge does not exceed 768 pixels while preserving the original aspect ratio to bound per-frame token costs.
- The agent VLM receives at most 32 frames as visual context, with longer video inputs sampled at uniform temporal intervals to yield 32 key frames.
- Multi-image inputs are truncated to the first 32 images in the sequence.
- A persistent kernel retains the full sampled frame sequence, allowing any frame to be revisited via show() or forwarded to a perception tool in subsequent steps.
- Samples containing multiple videos maintain each as an independent frame sequence to enable the agent to analyze and compare them independently.
Method
The authors propose SpatialClaw, a training-free agent framework designed to enhance spatial reasoning capabilities by replacing single-pass code execution and structured tool-call interfaces with a persistent, multi-turn Python kernel. This design allows the agent to compose perception outputs with numerical primitives, inspect intermediate state, and revise analysis over multiple steps. The core of the system is an iterative agentic loop wrapped around a stateful execution environment.
Refer to the framework diagram below for the overall architecture of the five-stage loop that governs the agent's behavior.
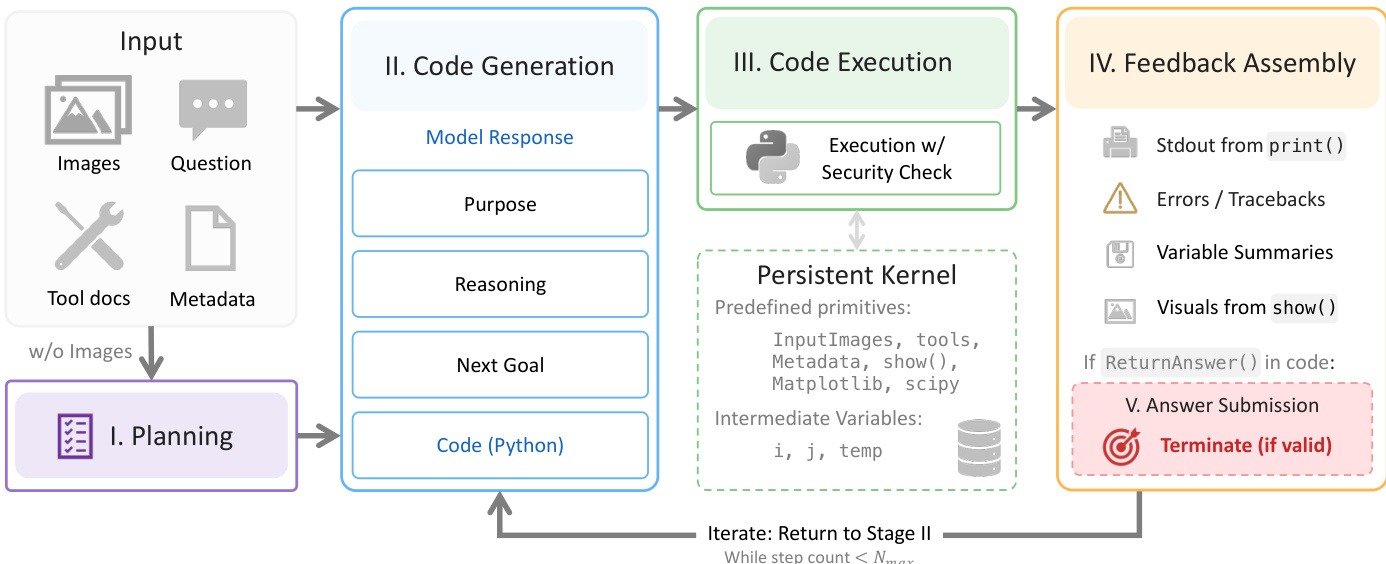
The process begins with Planning, where a separate LLM session generates an analysis plan based on the question and tool documentation, without viewing the input images. This plan is then passed to the main agent for Code Generation, where the model produces a Python cell implementing the next analysis action. This code is executed within a Persistent Kernel that maintains shared program state across execution steps. The kernel is pre-loaded with input frames, metadata, and a suite of primitives spanning perception modules (e.g., depth estimation, segmentation) and scientific libraries (e.g., NumPy, SciPy).
Following execution, the system performs Feedback Assembly, compiling standard output, variable summaries, and any rendered images into the context for the next turn. If the agent has not yet submitted a valid answer via the ReturnAnswer() function, the loop iterates back to code generation. This iterative structure enables the agent to treat spatial conclusions as claims that must be cross-checked against multiple evidence sources.
The advantage of this persistent, iterative approach is illustrated in the comparison of different action interfaces. While single-pass code requires the agent to commit to a complete strategy without observing intermediate results, and structured tool-calls restrict each step to a single named invocation, SpatialClaw allows for flexible composition and revision.
Refer to the figure below which demonstrates how the agent identifies and corrects errors through intermediate verification.
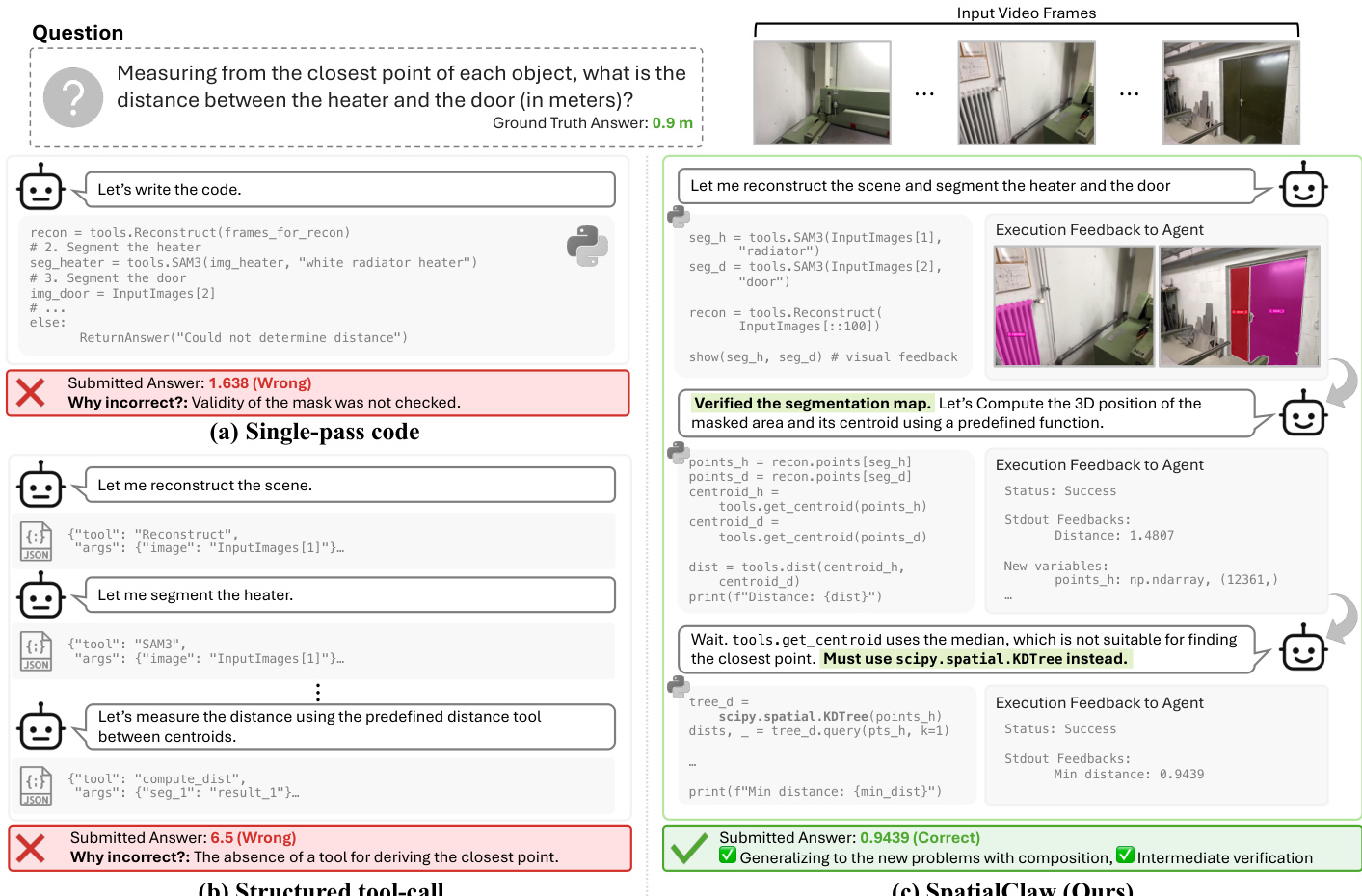
In the example shown, the agent initially attempts to compute distance using centroids derived from a median calculation. Upon receiving execution feedback indicating the method was unsuitable for finding the closest point, the agent revises its strategy in the next turn to utilize scipy.spatial.KDTree. This capability to inspect intermediate masks, depth maps, or numerical summaries and subsequently refine the code allows the system to generalize to new problems through composition and intermediate verification, rather than relying on static tool definitions. The kernel exposes specific entry points such as tools.Reconstruct for 3D geometry and tools.SAM3 for segmentation, ensuring that all intermediate results remain accessible as ordinary Python variables for future steps.
Experiment
SpatialClaw is evaluated across 20 spatial reasoning benchmarks and six visual language model backbones to compare its code-based action interface against structured tool calls and single-pass code alternatives. Results demonstrate that this design consistently outperforms baselines, especially in tasks requiring multi-step geometric composition, while generalizing across models without specific tuning. Further analysis confirms the agent spontaneously adapts tool usage to question types and maintains comparable performance even without predefined utility functions, indicating the action interface itself drives performance gains rather than model capacity.
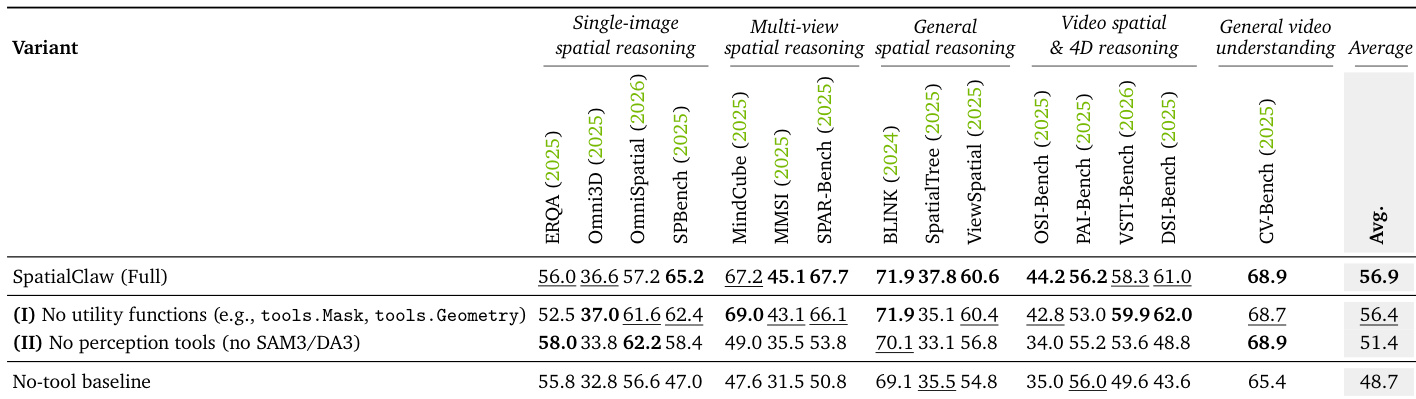
The authors conduct an ablation study to determine the contribution of utility functions and perception tools to SpatialClaw's performance. Results indicate that removing pre-defined utility functions has a minimal impact on performance, suggesting the code-based interface allows the model to substitute these with on-the-fly numerical computation. Conversely, removing perception tools leads to a significant performance decrease, though the remaining action interface still outperforms the baseline without any tools. Removing utility functions yields performance comparable to the full model, demonstrating the flexibility of the code-based action interface. The full model variant achieves the best overall results across all evaluated reasoning categories. Eliminating perception tools causes a notable drop in accuracy, yet the system still outperforms the no-tool baseline.
The authors evaluate SpatialClaw against Single-pass Code and Structured tool-call interfaces across thirteen meta-categories of spatial reasoning. Results show that SpatialClaw secures a net advantage over both baselines in the majority of categories, with the most significant performance lifts observed in tasks requiring chained geometric computation across frames or viewpoints. SpatialClaw demonstrates superior performance over Single-pass Code, particularly in camera motion and multi-view viewpoint reasoning tasks. The model maintains a consistent win margin against Structured tool-call, validating the flexibility of its code-as-action interface. Performance gains are minimal or slightly negative in categories like spatial planning and size estimation where perception quality may be the limiting factor.

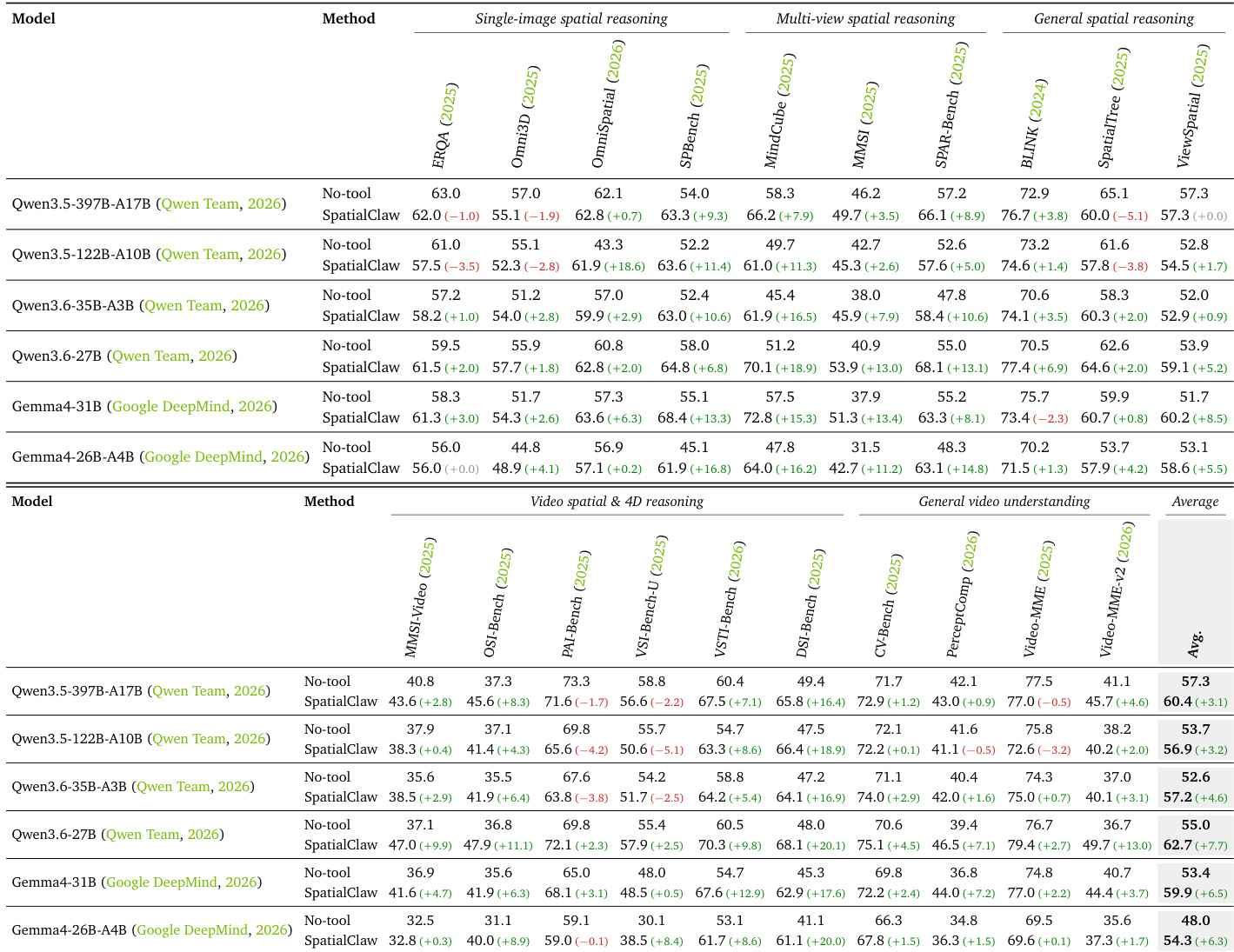
The authors evaluate SpatialClaw against a no-tool baseline across six different vision-language model backbones and twenty spatial reasoning benchmarks. The results demonstrate that SpatialClaw consistently outperforms the baseline across all model sizes, with particularly significant improvements observed in multi-view and video spatial reasoning tasks that require complex geometric computation. SpatialClaw shows consistent performance gains over the no-tool baseline across all evaluated backbone models, ranging from 26B to 397B parameters. The method achieves its most pronounced improvements in video spatial and multi-view reasoning categories, which benefit from iterative multi-step geometric computation. The action interface design generalizes effectively without requiring model-specific tuning or pre-defined utility tools.
The authors compare their proposed method, SpatialClaw, against three existing spatial agents: VADAR, pySpatial, and SpaceTools Toolshed. Results demonstrate that SpatialClaw consistently outperforms all baselines across the diverse set of benchmarks, achieving the highest accuracy in every category. While SpaceTools Toolshed generally ranks second, VADAR shows limitations in supporting video or multi-image inputs compared to the other approaches. SpatialClaw achieves the highest performance scores across all evaluated benchmark categories. SpaceTools Toolshed generally outperforms single-pass code baselines like VADAR and pySpatial but falls short of SpatialClaw. VADAR does not support video or multi-image reasoning tasks, resulting in missing performance data for those specific benchmarks.
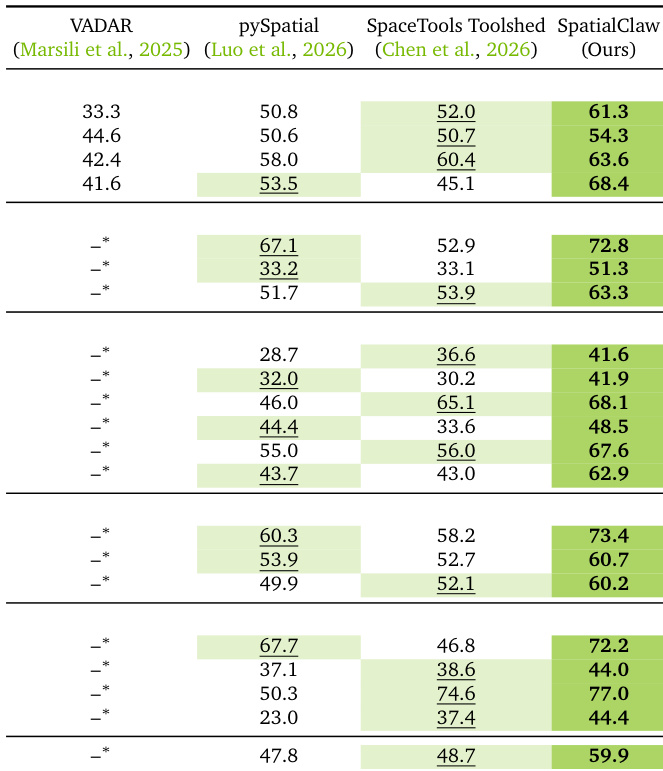
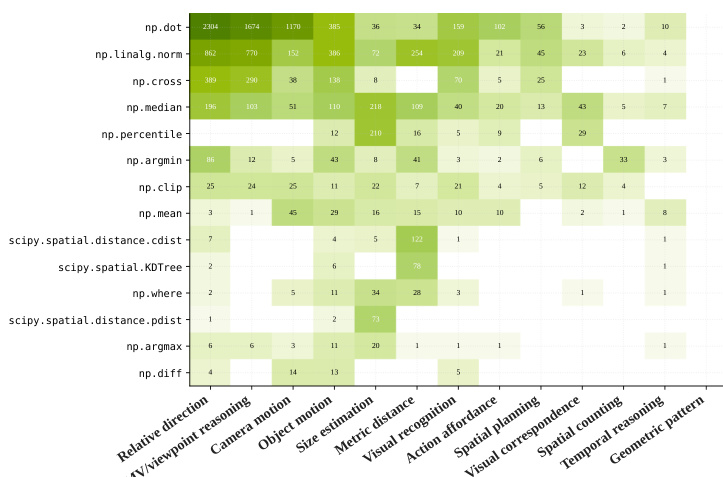
The heatmap illustrates how the agent adapts its tool usage based on the specific spatial reasoning task. It reveals a clear specialization where distance-related tasks rely on spatial indexing and norms, while direction tasks utilize dot products, demonstrating that the agent selects appropriate geometric primitives based on question semantics without hard-coded routing. Direction-based tasks rely primarily on dot products and angular calculations. Distance estimation tasks heavily utilize spatial indexing and vector norm operations. The agent spontaneously composes tools based on task semantics without category-specific prompt engineering.
The evaluation assesses SpatialClaw through ablation studies and comparisons against various baselines and backbones across diverse spatial reasoning benchmarks. Results indicate that the code-based action interface provides significant flexibility by allowing the model to substitute utility functions, while perception tools remain essential for optimal performance. SpatialClaw consistently achieves superior accuracy over competing agents across varying model sizes, especially in tasks requiring chained geometric computation, and demonstrates the ability to spontaneously compose tools based on question semantics.