Command Palette
Search for a command to run...
InterleaveThinker: Reinforcing Agentic Interleaved Generation
InterleaveThinker: Reinforcing Agentic Interleaved Generation
Dian Zheng Harry Lee Manyuan Zhang Kaituo Feng Zoey Guo Ray Zhang Hongsheng Li
Abstract
Recent image generators have demonstrated impressive photorealism and instruction-following capabilities in single-image generation and editing. However, constrained by their architectures, they cannot achieve interleaved generation (text-image sequence), which has crucial applications in visual narratives, guidance, and embodied manipulation. Even the latest open-source Unified Multimodal Models (UMMs) exhibit limited performance in this regard. In this paper, we introduce InterleaveThinker, the first multi-agent pipeline designed to endow any existing image generator with interleaved generation capabilities. Specifically, we employ a planner agent to organize the image-text input sequence, instructing the image generator on the required execution at each step. Subsequently, we introduce a critic agent to evaluate the generator's outputs, identify samples that deviate from the planned instructions, and refine the instructions for regeneration. To implement this pipeline, we construct the Interleave-Planner-SFT-80k and Interleave-Critic-SFT-112k to perform a format cold-start. Then we develop Interleave-Critic-RL-13k to reinforce the step-wise instruction correction capability within a generation trajectory using GRPO.
One-sentence Summary
InterleaveThinker is the first multi-agent pipeline designed to endow any existing image generator with interleaved generation capabilities by employing a planner agent to organize the image-text input sequence and a critic agent to evaluate outputs and refine instructions, using Interleave-Planner-SFT-80k and Interleave-Critic-SFT-112k for format cold-start and Interleave-Critic-RL-13k with GRPO to reinforce step-wise instruction correction for visual narratives and embodied manipulation.
Key Contributions
- The paper introduces InterleaveThinker, a multi-agent pipeline designed to endow existing image generators with interleaved generation capabilities. This system employs a planner agent to organize image-text sequences and a critic agent to evaluate outputs and refine instructions for regeneration.
- The work constructs Interleave-Planner-SFT-80k and Interleave-Critic-SFT-112k datasets to perform a format cold-start for the pipeline. Additionally, Interleave-Critic-RL-13k is developed to reinforce step-wise instruction correction within generation trajectories using GRPO.
- Experiments demonstrate that the pipeline achieves performance comparable to proprietary models while surpassing existing open-source Unified Multimodal Models on interleaved generation benchmarks. The framework also significantly enhances base models on reasoning benchmarks, with WISE scores increasing from 0.47 to 0.73 and RISE scores leaping from 13.3 to 28.9.
Introduction
Current image generators excel at single-image synthesis but lack native support for interleaved text-image sequences required for visual narratives and embodied manipulation. While Unified Multimodal Models attempt this, they suffer from visual over-reliance and step-wise error accumulation during long-horizon tasks. To address this, the authors introduce InterleaveThinker, a multi-agent pipeline that equips existing image generators with robust interleaved generation capabilities. They employ a Planner agent to outline the full sequence upfront and a Critic agent to evaluate and refine steps using specialized datasets and a dual-reward reinforcement learning strategy for efficient trajectory guidance. This approach eliminates visual over-reliance and significantly outperforms open-source UMMs on generation and reasoning benchmarks.
Dataset
Dataset Composition and Sources
- The authors construct a dedicated pipeline to generate aligned pairs of interleaved instructions, visual states, and critic judgments.
- They curate approximately 40,000 diverse text prompts spanning 8 main categories and 75 sub-categories using Gemini 2.5 Pro.
- Multi-agent trajectories are created where a Planner generates instructions and an Image Generator executes them using Nano Banana Pro or FLUX.2-klein-9B.
- A Critic agent evaluates each step and refines prompts if the generated image deviates from the instruction.
Key Details for Each Subset
- Critic Datasets: The process yields Interleave-Critic-SFT-112k for supervised fine-tuning and Interleave-Critic-RL-13k for reinforcement learning.
- Planner Dataset: The Interleave-Planner-SFT-80k combines self-synthesized sequences with external open-source interleaved data.
- Filtering Rules: Filtering removes samples with logical inconsistencies or poor visual quality but applies exclusively to Critic training data.
How the Paper Uses the Data
- Trajectory Decomposition: Full trajectories are decomposed into independent step-wise data to enable single-iteration optimization.
- Score-Based Splitting: An adapted VIEScore system assigns 0 to 10 scores for semantic alignment and visual quality.
- Data Partitioning: Steps with high score variance are allocated to the RL subset while stable high-quality steps go to the SFT subset.
- Mixture Ratio: The authors maintain an empirical 2:1 sample ratio between the SFT and RL subsets.
- Distribution Balancing: Iteration-wise data is resampled to balance binary judgment distributions and prevent biased estimations.
Processing and Construction Details
- Input Truncation: Multimodal inputs are synthesized by interleaving textual plans with final image outputs and randomly truncating the sequence.
- Prompt Constraints: System prompts enforce rules such as prohibiting step prefixes in instruction fields and requiring specific output structures.
- Evaluation Criteria: Critic evaluation focuses on intent matching by comparing original AI-generated images against edited versions.
Method
To address the challenges of visual over-reliance and step-wise error accumulation inherent in Unified Multimodal Models (UMMs), the authors propose InterleaveThinker. This framework introduces a decoupled multi-agent architecture that endows frozen image generators with robust interleaved generation capabilities. The system is designed to handle complex tasks that require alternating between text and image generation without degrading quality over long horizons.
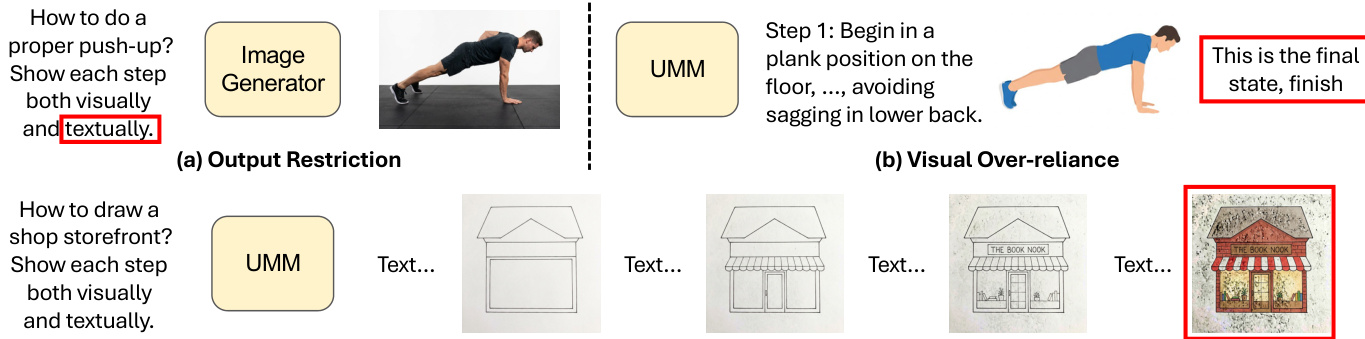
Refer to the figure below to understand the specific problems InterleaveThinker aims to solve, such as output restrictions and visual over-reliance in existing models.
The core of the InterleaveThinker framework is a progressive, closed-loop pipeline comprising three distinct modules: a Planner, a Generator, and a Critic. This architecture decomposes complex interleaved generation tasks into manageable, step-wise executions while incorporating a self-correction mechanism to ensure high-fidelity output. The overall workflow is illustrated in the framework diagram below.
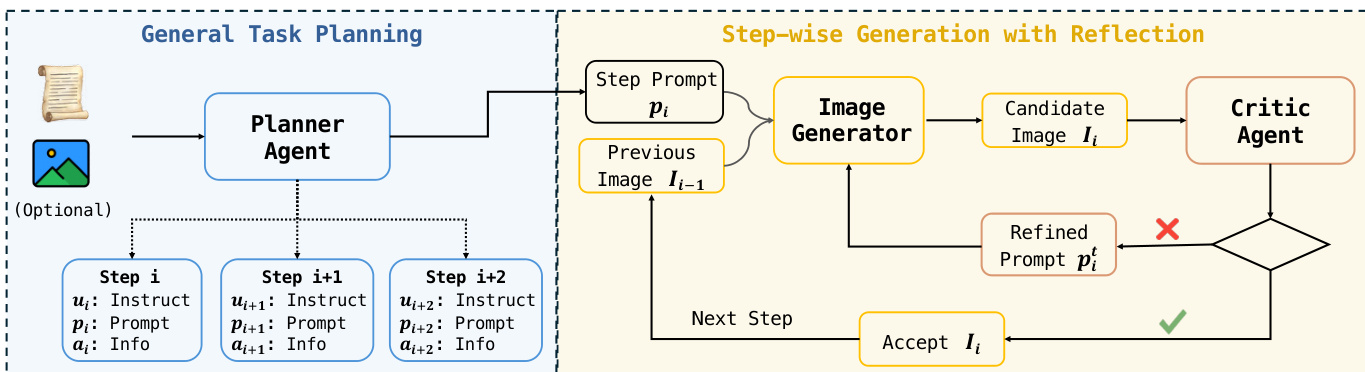
The process begins with the Planner module. Given an input sequence S, the Planner analyzes the user request and translates it into an N-step execution plan. For each step i∈{1,…,N}, the Planner generates a step instruction ui, a model-friendly initial prompt pi adapted from ui, and auxiliary text ai which provides necessary knowledge-based elaboration. This planning process is formulated as:
{(ui,pi,ai)}i=1N=Planner(S).Next, the Generator module executes the plan. At step i and refinement iteration t∈{1,Tmax}, the Generator takes the current refined prompt rit (where ri0=pi) and the image from the previous step Ii−1 to produce the current image Iit. For the initial step, I0 is defined as a blank canvas. The generation equation is:
Iit=Generator(rit,Ii−1).To ensure strict alignment with the intended instructions, the Critic module provides quantitative feedback and prompt optimization. The Critic evaluates the transition from the pre-execution image Ii−1 to the post-execution image Iit. It outputs a binary judgment jit, a newly refined prompt rit+1, and a reasoning process Rit:
(jit,rit+1,Rit)=Critic(Ii−1,Iit,pi,rit).This generation-evaluation loop iterates until a positive judgment is obtained or the maximum iteration count is reached. A detailed example of this workflow, visualizing the lifecycle of a frog from eggs to a mature organism, is shown below.

To support the training of these agents, the authors construct a dedicated data pipeline. This pipeline involves text prompt construction across diverse categories, multi-agent trajectory generation, and critic data filtering. The process results in high-quality datasets specifically designed for interleaved generation tasks. The data construction and splitting strategy are detailed in the figure below.
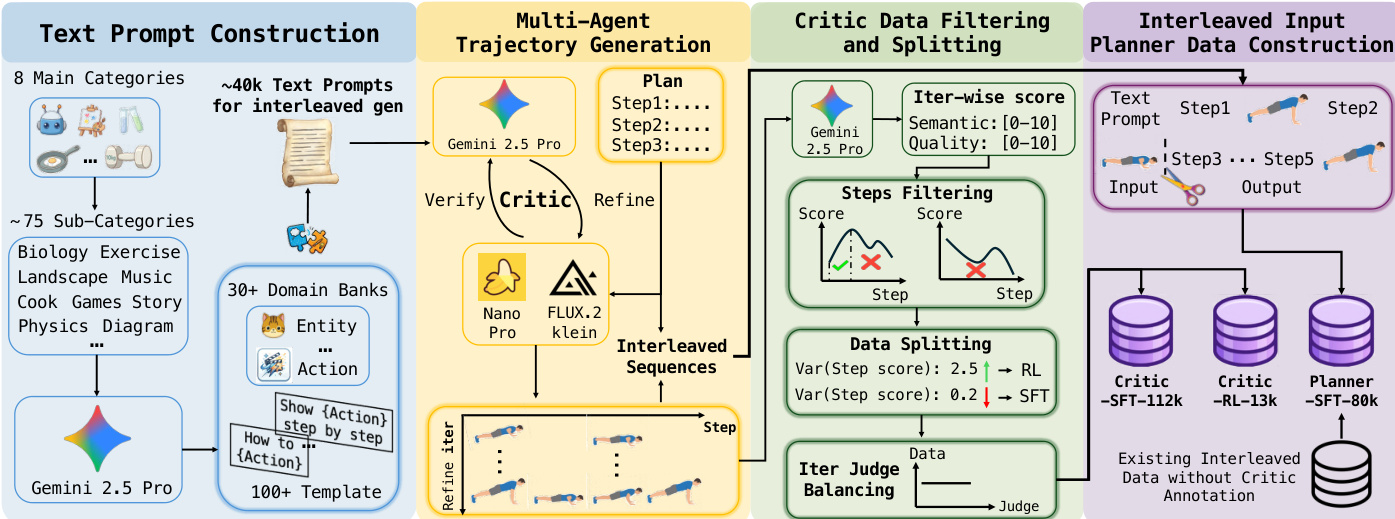
The training scheme follows a two-stage pipeline. First, Supervised Fine-Tuning (SFT) is applied to the Planner and Critic to establish a multi-agent format cold-start. The Planner is trained on the Interleave-Planner-SFT-80k dataset, while the Critic is trained on Interleave-Critic-SFT-112k. Following SFT, the authors employ Reinforcement Learning (RL) using the GRPO algorithm to reinforce the Critic's correction capabilities. To handle the computational cost of long trajectories, they propose a dual-reward strategy. This strategy utilizes an Accuracy Reward (Racc) to measure judgment correctness and a Step-wise Reward (Rstep) to evaluate the effectiveness of prompt refinements. The final reward R is a weighted combination:
R=0.5∗Rformat+0.5∗(αRacc+(1−α)Rstep)The effectiveness of this framework is demonstrated across various domains, including visual narratives, guidance, world interaction, and robotic manipulation. The following figure showcases the system's ability to generate coherent sequences for tasks such as character battles, text rendering, and object manipulation.

Experiment
The evaluation assesses the InterleaveThinker framework across interleaved generation and reasoning tasks using models for both in domain evaluation and generalization capabilities. Results indicate that the multi agent pipeline significantly outperforms existing methods by mitigating visual overreliance and stepwise error accumulation while maintaining high textual fidelity. Further ablation studies confirm the necessity of distinct planner and critic roles alongside combined rewards to ensure effective refinement, although the system cannot correct errors from unknown generator concepts.
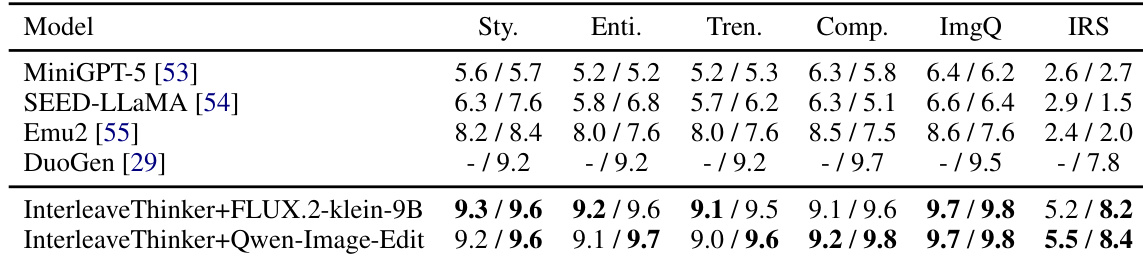
The authors evaluate the InterleaveThinker framework on the CoMM benchmark, comparing its performance against several existing open-source models. Results demonstrate that integrating InterleaveThinker with different image generators consistently outperforms baseline models across style, entity consistency, trend alignment, completeness, and image quality metrics. The framework proves particularly effective in text-image alignment, achieving the highest scores in this category compared to competitors, while also showing generalizability across different base models. InterleaveThinker significantly surpasses existing open-source models across all evaluated metrics on the CoMM benchmark. The framework demonstrates strong generalizability, achieving further performance gains when integrated with the Qwen-Image-Edit model. Text-image alignment scores are notably higher for the proposed method compared to baseline approaches.
The authors evaluate their InterleaveThinker framework on a reasoning-based benchmark to assess image generation capabilities across diverse knowledge domains. The results demonstrate that integrating this framework with base models leads to substantial performance improvements across all tested categories. These enhanced models achieve the highest scores among open-sourced approaches, outperforming previous state-of-the-art baselines. InterleaveThinker significantly boosts the performance of base models across all knowledge categories including Biology, Physics, and Chemistry. The framework is model-agnostic, showing consistent improvements when applied to different base architectures like FLUX.2-klein-9B and Qwen-Image-Edit-2511. The proposed method achieves the best overall performance among open-sourced models, surpassing strong baselines like BAGEL.
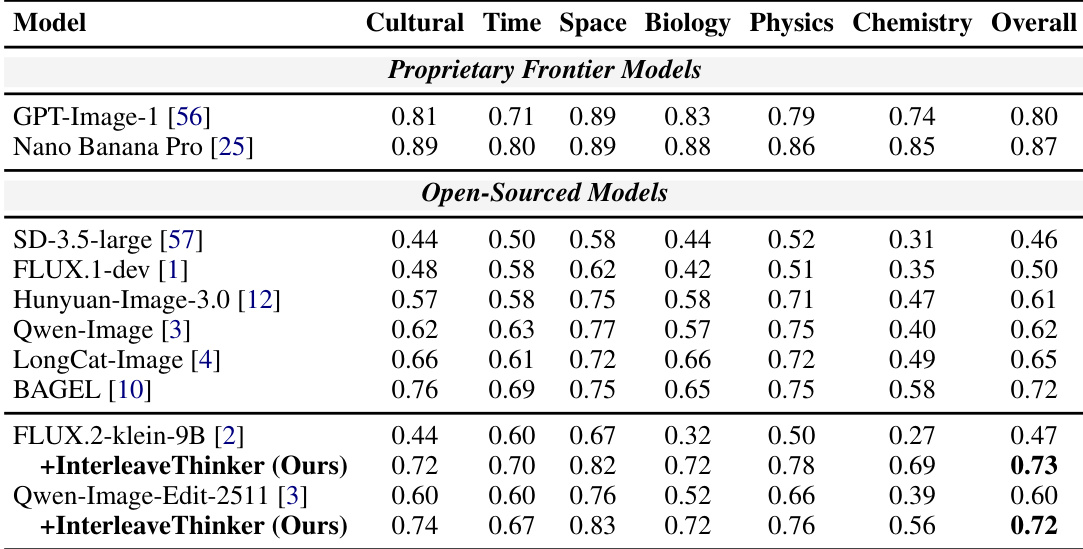
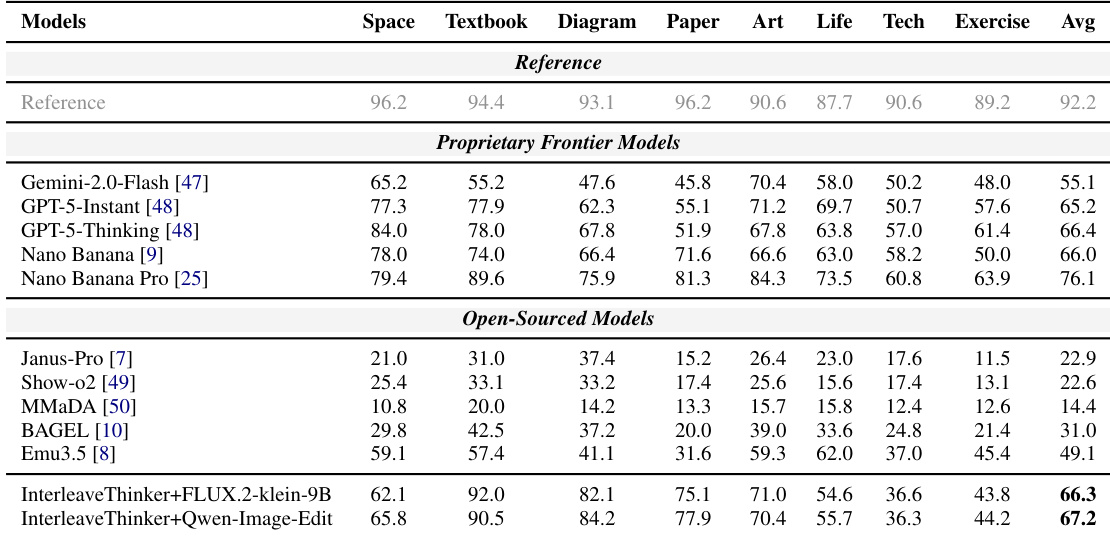
The authors evaluate their InterleaveThinker framework on the UEval benchmark, comparing it against reference, proprietary, and open-sourced models. The results demonstrate that their multi-agent pipeline significantly outperforms existing open-source models and achieves performance comparable to leading proprietary models. The proposed InterleaveThinker framework significantly outperforms existing open-sourced models across all categories. The method achieves competitive results with proprietary frontier models, particularly excelling in Textbook and Diagram tasks. Integrating the framework with the Qwen-Image-Edit model yields better overall performance than using the FLUX.2-klein-9B generator.
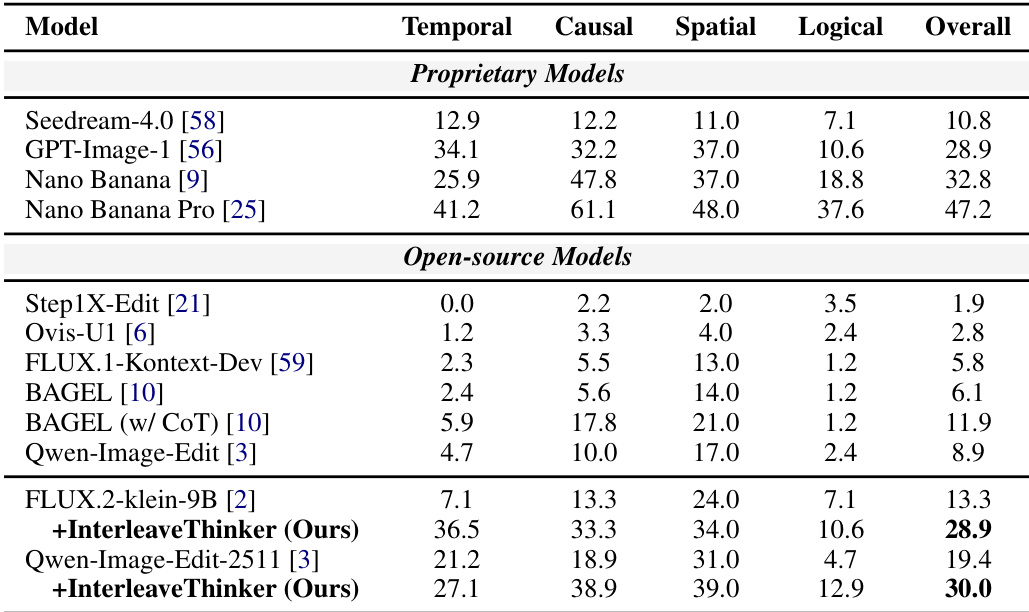
The authors evaluate the InterleaveThinker framework on reasoning benchmarks, comparing it against proprietary and open-source baselines. The results demonstrate that integrating InterleaveThinker with base models like FLUX.2-klein-9B and Qwen-Image-Edit-2511 leads to substantial performance gains across temporal, causal, spatial, and logical reasoning categories. While top proprietary models remain superior, the enhanced open-source models achieve competitive results, outperforming several existing baselines. Integrating InterleaveThinker with base models yields substantial performance improvements across all reasoning categories compared to the original open-source models. The enhanced Qwen-Image-Edit-2511 model achieves competitive results, surpassing specific proprietary baselines like GPT-Image-1 in overall performance. The framework demonstrates strong generalizability, effectively boosting capabilities in spatial and causal reasoning tasks for different underlying architectures.
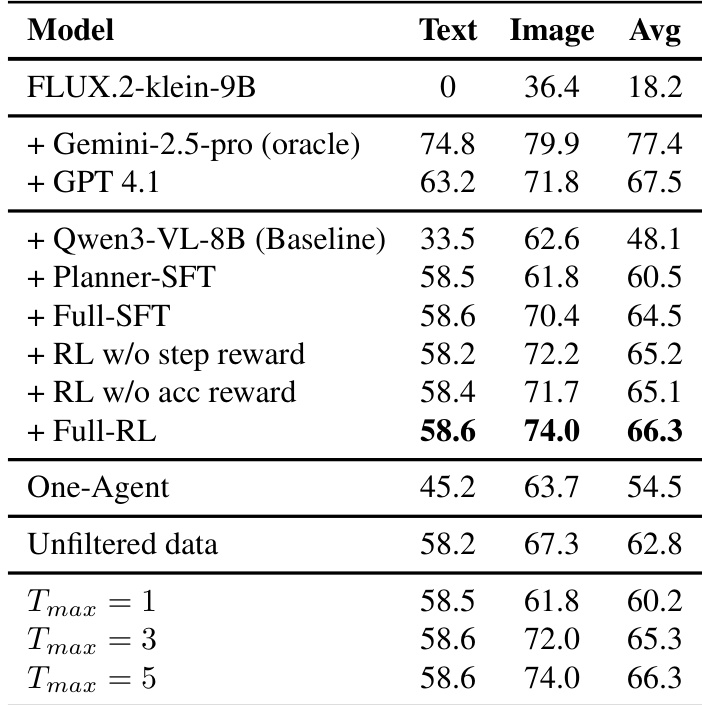
The the the table presents an ablation study on the UEval benchmark using the FLUX.2-klein-9B image generator to validate the InterleaveThinker framework. The results demonstrate that the raw generator fails at interleaved tasks, while the multi-agent pipeline significantly boosts performance, particularly through the Planner-SFT stage which drastically improves text scores. The best results are achieved with the Full-RL configuration, which outperforms single-agent baselines and unfiltered data variants, while increasing refinement iterations consistently enhances output quality. The raw image generator alone fails to generate interleaved text, while the multi-agent baseline successfully enables text generation capabilities. Fine-tuning the Planner causes a massive surge in text scores, and the full RL configuration achieves the best overall performance by optimizing both text and image quality. Separating the planner and critic roles proves superior to a unified one-agent approach, and increasing the maximum refinement iterations consistently improves performance.
The InterleaveThinker framework is evaluated across diverse benchmarks such as CoMM and UEval to assess image generation and reasoning capabilities against open-source and proprietary baselines. Experiments demonstrate that integrating this framework with base models consistently outperforms existing open-source approaches in areas like text-image alignment and logical reasoning while achieving competitiveness with proprietary systems. Furthermore, ablation studies confirm that the multi-agent pipeline and specific configurations like Full-RL are essential for enabling interleaved tasks and maximizing output quality compared to raw generators.