Command Palette
Search for a command to run...
Learning from Your Own Mistakes: Constructing Learnable Micro-Reflective Trajectories for Self-Distillation
Learning from Your Own Mistakes: Constructing Learnable Micro-Reflective Trajectories for Self-Distillation
Zhilin Huang Hang Gao Ziqiang Dong Yuan Chen Yifeng Luo Chujun Qin Jingyi Wang Yang Yang Guanjun Jiang
Abstract
Self-distillation improves reasoning in large language models by using the model's own rollouts as training signal, typically through implicit logit-level alignment that minimizes KL divergence toward a privileged target distribution. However, because this supervision is generated via uncontrolled sampling, it provides no diagnostic insight into the model's specific errors or corrective guidance for its individual failure patterns. Consequently, the model learns to imitate a privileged distribution rather than receiving fine-grained corrections that pinpoint where and why its reasoning fails. In this paper, we propose Trajectory-Augmented Policy Optimization (TAPO), which advances self-distillation from implicit distributional alignment to explicit trajectory construction. During RL training, the model produces both correct and incorrect rollouts to the same query, and TAPO leverages this contrastive structure to construct micro-reflective corrections, new training trajectories that retain the model's erroneous reasoning up to the point of failure, then insert a natural-language diagnosis and corrected reasoning guided by a correct reference from the same sampling group. Since each trajectory is anchored in the learner's own prefix and solutions, the corrective signal preserves the model's on-policy distribution to a greater extent than the position-wise alignment imposed by KL-based methods. To integrate these trajectories, TAPO introduces difficulty-aware candidate selection at the model's capability boundary and decoupled advantage estimation to prevent gradient contamination. Experiments on AIME 2024, AIME 2025, and HMMT 2025 show that TAPO achieves consistent improvements over GRPO under the same number of training steps. Further analysis demonstrates that TAPO strengthens both first-pass reasoning and error-correction effectiveness.
One-sentence Summary
The authors propose Trajectory-Augmented Policy Optimization (TAPO), a self-distillation framework that advances beyond implicit logit-level alignment by constructing explicit micro-reflective trajectories from contrastive correct and incorrect rollouts, retaining the model's erroneous reasoning up to the failure point and then inserting a natural-language diagnosis and corrected reasoning guided by a correct reference, thereby providing fine-grained, interpretable supervision to improve large language model reasoning.
Key Contributions
- TAPO advances self-distillation from implicit distributional alignment to explicit trajectory construction by creating new trajectories that preserve the model’s erroneous reasoning up to the point of failure and then insert a natural-language diagnosis and corrected reasoning guided by a correct rollout from the same GRPO sampling group.
- The approach incorporates difficulty-aware ZPD candidate selection, decoupled advantage estimation, and out-of-distribution token suppression to integrate these micro-reflective corrections into single-pass policy-gradient training without multi-turn loops or extra teacher models.
- Evaluations on AIME 2024, AIME 2025, and HMMT 2025 show consistent improvements over GRPO and OPSD, with DSR and ERR analysis confirming gains in both first-pass reasoning and error correction, while ablation studies validate each component.
Introduction
In reinforcement learning for reasoning, algorithms like GRPO sample multiple candidate solutions per problem to compute group-relative advantages, but the contrast between correct and incorrect outputs is only used implicitly during advantage normalization. Self-distillation methods provide dense token-level supervision yet offer no structured representation of the error-to-correction transition, and multi-turn error-driven approaches incur extra generation cost or require rich feedback that is unavailable in math reasoning tasks with binary correctness signals. The authors propose TAPO, which constructs explicit micro-reflective corrective trajectories from the model’s own erroneous prefixes found within GRPO sampling groups, turning the implicit contrastive signal into learnable supervision that teaches the model to diagnose and recover from its mistakes in a single-pass training framework.
Method
The authors propose Trajectory-Augmented Policy Optimization (TAPO), a framework that advances self-distillation from implicit distributional alignment to explicit trajectory construction. The core idea is to construct learnable corrective trajectories anchored in the model's own errors while remaining within its distributional neighborhood.
Before RL training, the authors perform a cold-start phase to equip the model with the ability to follow structured trajectory construction prompts and analyze its own errors. This phase constructs training examples by sampling responses, partitioning them into correct and incorrect groups, and building micro-reflective corrective trajectories.
During RL training, the model produces both correct and incorrect rollouts for the same query. TAPO leverages this contrastive structure through Micro-Reflective Trajectory Construction. As shown in the figure below:
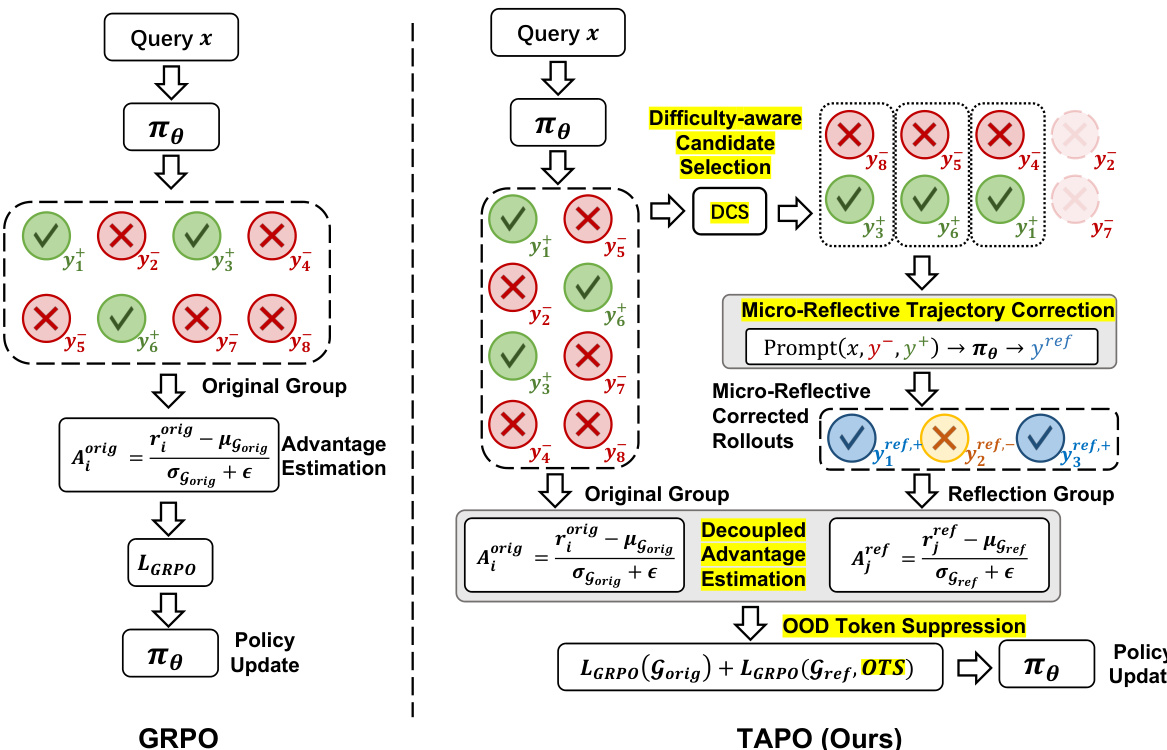
First, Difficulty-Aware Candidate Selection (DCS) identifies queries within the model's Zone of Proximal Development (ZPD). A query is eligible if it has at least npos correct responses and nneg incorrect responses. This condition naturally partitions problems into mastered, ZPD, and beyond-capability zones, creating an emergent curriculum as the model improves. For eligible queries, incorrect responses are paired with correct references.
Next, Trajectory Synthesis constructs a prompt presenting the original question, the incorrect response, and the correct reference. The model is instructed to analyze the error and construct a corrective trajectory. This micro-reflective trajectory preserves the model's erroneous reasoning up to the point of failure, inserts a natural-language diagnosis and corrected reasoning, and continues to the final answer.
To integrate these trajectories into advantage-based RL, the authors introduce Decoupled Advantage Estimation (DAE). Appending constructed trajectories to the original group would inflate the group mean reward, causing advantage contamination and penalizing response length. To resolve this, advantages are computed independently for the original group Gorig and the reflection group Gref. The advantage for each response in the original group is computed as:
Aiorig=σGorig+ϵriorig−μGorigSimilarly, for the reflection group:
Ajref=σGref+ϵrjref−μGrefThe final training loss combines both groups:
LTAPO=LGRPO(Gorig)+λ⋅Lref(Gref)Finally, to maintain stable optimization, the authors apply OOD Token Suppression (OTS) to the reflection trajectory loss. Since the construction process may produce tokens that deviate from the model's natural generation distribution, a distribution alignment score is computed for each token yt:
st=logpθ(yt∣x,y<t)+H[pθ(⋅∣x,y<t)]This score is converted into a multiplicative weight wt, down-weighting out-of-distribution corrective tokens while preserving the learning signal from in-distribution reasoning portions. The reflection trajectory loss is then computed as:
Lref=−T1t=1∑Twt⋅min(ρt⋅Aref, clip(ρt,1−ϵ,1+ϵ)⋅Aref)Experiment
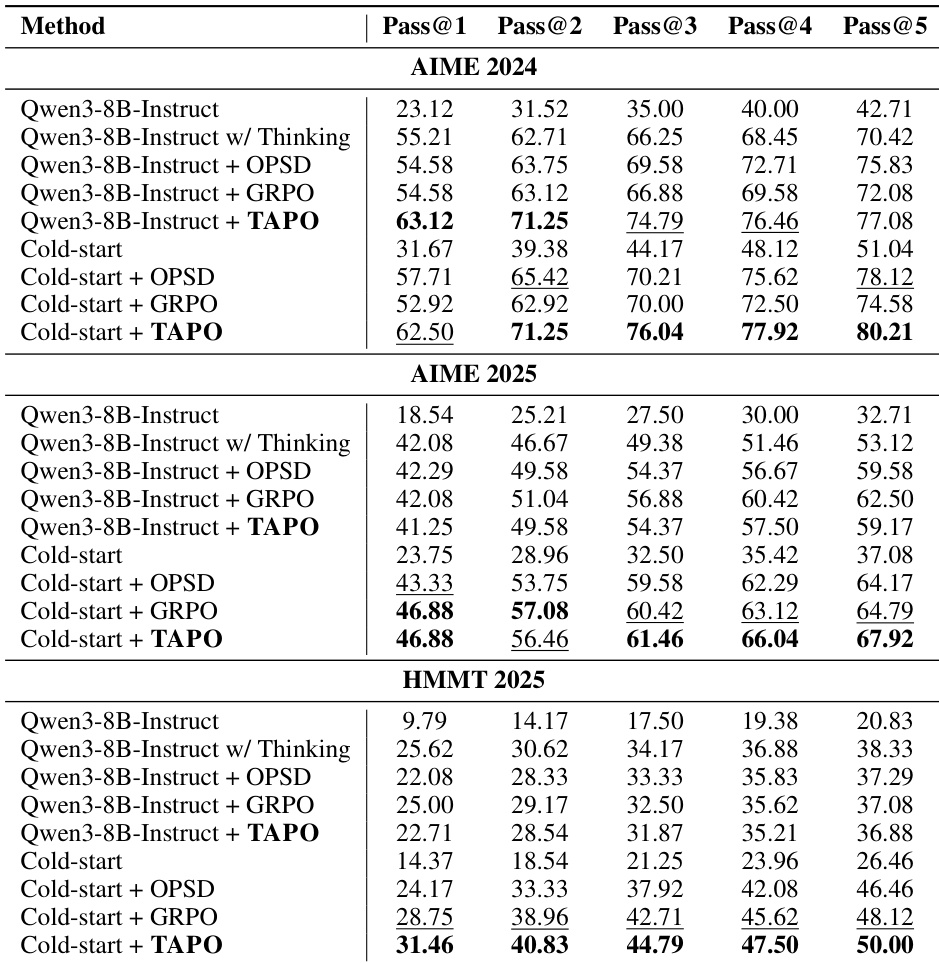
The evaluation pits TAPO against GRPO and OPSD on AIME and HMMT math benchmarks using Qwen3-8B-Instruct, with and without cold-start initialization. Cold-start TAPO yields consistent improvements by internalizing error-correction capability, as evidenced by gains in both direct solution rate and effective reflection rate. Ablation studies confirm that preserving correct prefixes, decoupled advantages, negative samples, and out-of-distribution token suppression are essential; training dynamics show cold-start pre-alignment prevents policy drift and enables robust optimization.
The authors evaluate whether the proposed method internalizes genuine error-correction capabilities by measuring direct solution rates and effective reflection rates. Results show that the method significantly outperforms the baseline across all benchmarks in both metrics, indicating that training on corrective trajectories strengthens both first-pass reasoning and the ability to successfully recover from errors. The method achieves substantial improvements in direct solution rates across all evaluated benchmarks, demonstrating stronger first-pass reasoning without relying on explicit reflection. Effective reflection rates are consistently higher for the proposed method, showing that when the model engages in self-correction, it is more likely to accurately diagnose and fix errors. The gains in first-pass reasoning are most pronounced on the hardest benchmark, suggesting that corrective training is particularly beneficial for complex tasks.

The authors evaluate TAPO on challenging mathematical reasoning benchmarks, comparing it against GRPO and OPSD baselines under both direct training and cold-start initialization settings. Results show that TAPO with cold-start initialization consistently achieves the highest pass rates across all benchmarks and sampling counts, demonstrating genuine capability enhancement. However, without cold-start initialization, TAPO underperforms on harder benchmarks, highlighting the importance of the initial supervised fine-tuning phase for trajectory construction. Cold-start TAPO achieves the best first-pass accuracy on all three mathematical benchmarks, outperforming both GRPO and OPSD baselines. The performance gains from TAPO are sustained across multiple sampling attempts, indicating robust capability enhancement rather than single-path variance reduction. Direct training without cold-start initialization leads to mixed results, where TAPO underperforms GRPO on the more difficult benchmarks.
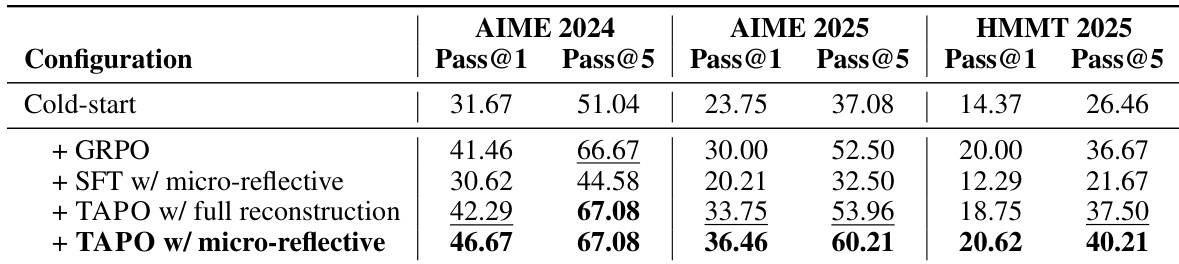
The authors conduct an ablation study to verify the necessity of each integration component in the TAPO pipeline, progressively adding Decoupled Advantage Estimation, negative samples, and OOD Token Suppression to a cold-start baseline. Results show that the full TAPO configuration consistently achieves the highest performance across all evaluated mathematical reasoning benchmarks. The study highlights that while the interaction between decoupled advantage estimation and negative samples is benchmark-dependent, OOD Token Suppression provides consistent gains by preventing the model from learning from distributionally distant tokens. The full TAPO pipeline outperforms all ablated variants across all benchmarks, demonstrating the cumulative benefit of its integration components. OOD Token Suppression consistently improves performance, confirming that reconstructed trajectories contain out-of-distribution tokens that harm learning under uniform weighting. The interaction between decoupled advantage estimation and negative samples varies by benchmark, with negative samples acting as necessary counterweights to prevent bias toward corrective trajectories on certain tasks.

The authors conduct an ablation study to evaluate the contributions of RL optimization and micro-reflective trajectory design. Results show that TAPO with micro-reflective construction outperforms all variants, demonstrating that advantage-based RL provides a meaningful advantage over supervised imitation and that preserving the learner's partial reasoning path is critical for effective learning. RL optimization significantly outperforms supervised fine-tuning on the same trajectory data, enabling the model to distinguish effective from ineffective corrections. Full reconstruction underperforms micro-reflective construction across all benchmarks, validating that preserving the valid reasoning prefix is essential for learnability. The complete TAPO configuration achieves the highest performance on all benchmarks, confirming the necessity of both RL optimization and prefix preservation.
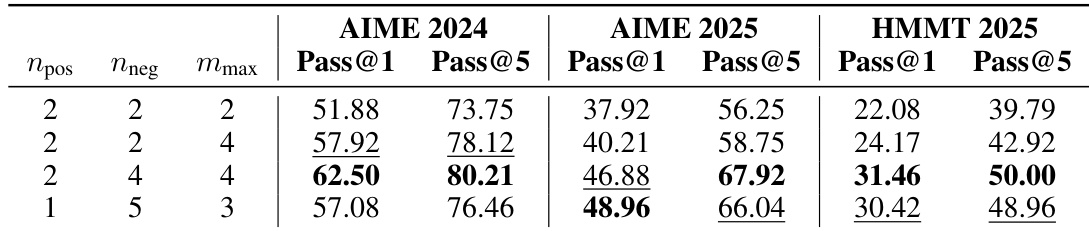
The authors investigate the sensitivity of their method to variations in the candidate selection mechanism parameters, specifically the ZPD threshold and maximum construction count. Results indicate that the method is reasonably robust to moderate parameter changes, with the default configuration performing consistently well across benchmarks. Adjusting the construction volume and threshold tightness reveals that construction quantity is a critical factor for maintaining performance. The default parameter configuration achieves the highest first-pass accuracy on two of the three benchmarks and the best overall accuracy across all benchmarks. Reducing the maximum number of constructions per query leads to a noticeable performance drop, which is largely recovered when the construction volume is increased. Tightening the selection threshold to focus on a narrower set of high-confidence queries yields the best first-pass accuracy on the most recent competition benchmark.
The evaluation setup uses challenging mathematical reasoning benchmarks, measuring direct solution rates, effective reflection, and pass rates under multiple sampling against RL baselines. Training on corrective trajectories strengthens both first-pass reasoning and self-correction, with the largest gains on the hardest tasks, and cold-start initialization is critical for difficult benchmarks. Ablation studies confirm that the full TAPO pipeline combining RL optimization, micro-reflective trajectory preservation, and OOD token suppression consistently outperforms ablated variants, while parameter sensitivity tests show robustness and highlight the importance of construction quantity.