Command Palette
Search for a command to run...
EvoEmbedding: Evolvable Representations for Long-Context Retrieval and Agentic Memory
EvoEmbedding: Evolvable Representations for Long-Context Retrieval and Agentic Memory
Chang Nie Chaoyou Fu Junlan Feng Caifeng Shan
Abstract
Existing embedding models are inherently static: they encode text segments in isolation, ignoring their surrounding context and temporal order. This paper introduces EvoEmbedding, a novel embedding model that generates evolvable representations for retrieval. It is tailored for long-context scenarios, where information is dynamic, sequential, and requires continuous state tracking. Our design is simple: EvoEmbedding maintains a continuously updated latent memory as it sequentially processes inputs, and uses it alongside the raw content to jointly generate evolvable embeddings. Consequently, for the same query, our model adapts its representation to retrieve distinct targets based on the evolving context, going beyond static semantic search. To equip the model with this capability, we construct EvoTrain-180K, a diverse dataset for the joint optimization of latent memory and retrieval. Furthermore, we introduce a memory queue to prevent representation collapse during recurrent encoding, alongside segment-batching techniques that tackle significant length variance and accelerate training by 3.8times. Extensive experiments show that our model not only outperforms larger-scale specialists (e.g., Qwen3-Embedding-8B and KaLM-Embedding-Gemma3-12B) across a range of long-context retrieval benchmarks, but also generalizes well to downstream tasks (e.g., personalization) with contexts 10times longer than its training window. Notably, EvoEmbedding seamlessly integrates into agentic workflows to boost performance. For instance, a naive RAG pipeline equipped with our model surpasses dedicated agentic memory systems. Project Page: https://clare-nie.github.io/EvoEmbedding.
One-sentence Summary
EvoEmbedding, an evolvable embedding model for long-context retrieval, maintains a continuously updated latent memory and jointly encodes raw content with that memory to produce context-adaptive representations; trained on EvoTrain-180K using a memory queue and segment-batching that accelerates training by 3.8×, it outperforms larger-scale specialists such as Qwen3-Embedding-8B and KaLM-Embedding-Gemma3-12B across long-context retrieval benchmarks, generalizes to contexts 10× longer than its training window on downstream tasks like personalization, and enables a naive RAG pipeline to surpass dedicated agentic memory systems.
Key Contributions
- EvoEmbedding generates evolvable embeddings by maintaining a continuously updated latent memory that adapts representations to evolving context. It outperforms larger specialist embedding models (Qwen3-Embedding-8B and KaLM-Embedding-Gemma3-12B) on long-context retrieval benchmarks, generalizes to downstream tasks with contexts 10× longer than its training window, and improves agentic workflows—for instance, a naive RAG pipeline with EvoEmbedding surpasses dedicated agentic memory systems.
- A diverse dataset, EvoTrain-180K, is constructed for the joint optimization of latent memory and retrieval, supplying the long-context sequences needed to learn evolvable embeddings.
- A memory queue prevents representation collapse during recurrent encoding, and dynamic segment-batching handles extreme length variance while accelerating training by 3.8×.
Introduction
Text embedding models have become essential for retrieval and reranking tasks, but they typically encode text segments in isolation, producing static representations that ignore surrounding context and temporal order. In long-context scenarios—such as ongoing dialogues or personalization over time—this chunk-and-encode strategy breaks continuity and leads to imprecise or redundant retrieval. Attempts to fix this through agentic retrieval pipelines add auxiliary structures or multi-step querying, yet they remain constrained by the loss of global context and introduce high latency. Meanwhile, latent memory models that bypass explicit retrieval are tightly coupled to autoregressive generation, require full access to model internals, and risk hallucination. The authors introduce EvoEmbedding, a model that maintains a continuously updated latent memory while encoding sequential inputs, jointly using this memory and the raw content to generate evolvable embeddings. This design adapts the representation of the same query to the evolving context, moving beyond static semantic search. To train the model stably, they propose a memory queue to prevent representation collapse, dynamic segment batching for efficiency, and a dedicated dataset (EvoTrain‑180K). The resulting embeddings not only set new state-of-the-art results on long-context retrieval benchmarks but also integrate seamlessly into naïve RAG pipelines to outperform dedicated agentic memory systems.
Dataset
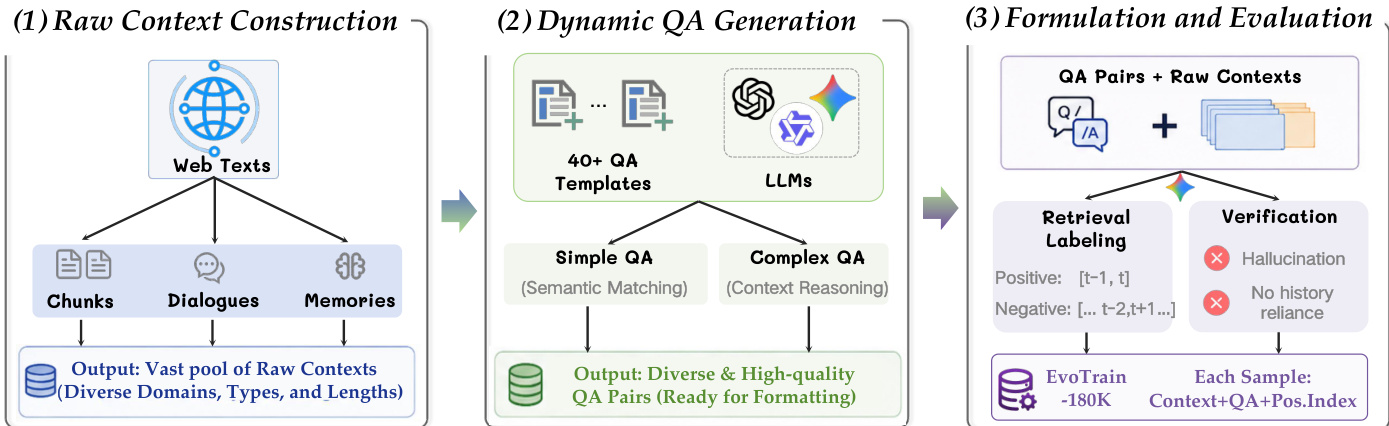
The authors construct EvoTrain-180K to train the EvoEmbedding model for long-context retrieval. The dataset contains 184,137 high-quality samples produced through an automated three-stage pipeline, with each sample capped at 12K tokens and 256 segments.
-
Sources and subsets
- Diverse web texts: Randomly sampled from the FineWeb dataset and converted into sequential segments using a sliding window approach.
- Synthesized dialogues: Multi-turn, persona-driven dialogues generated by large language models from predefined topics.
- Extracted memories: Various memory types extracted from the raw texts or dialogues to serve as context.
-
Pipeline and filtering
- Stage 1 – Raw context construction: Builds the three context types above, creating a broad pool of raw contexts.
- Stage 2 – Dynamic QA generation: Generates question-answer pairs guided by over 40 template types (e.g., coreference resolution, temporal understanding) and uses LLMs of different types and sizes for diversity.
- Stage 3 – Retrieval formulation and evaluation: Applies Gemini-3.1-Pro-Preview to label query-relevant segment indices as positive targets and to verify QA pairs, filtering out hallucinations and ensuring answers rely on the provided context rather than general knowledge.
-
Training usage
- The entire EvoTrain-180K dataset is used to jointly train EvoEmbedding’s memory and retrieval capabilities.
- Training is performed with a strict context length of up to 12K tokens and 256 segments, which is less than one-tenth of the context length used in testing scenarios.
- The dataset size is less than 1% of the data volume employed by contemporary embedding models.
Method
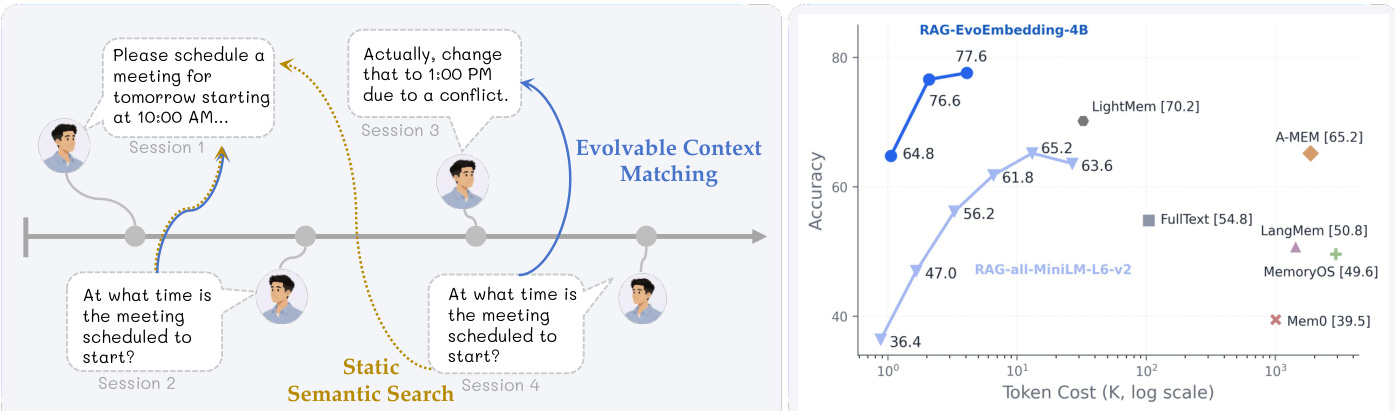
The authors propose EvoEmbedding to address the limitations of static semantic search, which often fails on adversarial cases like shallow keyword traps or paraphrased evidence requiring historical grounding. As illustrated in the comparison below, EvoEmbedding utilizes evolvable context matching to maintain a rolling contextual state, significantly improving accuracy over static methods while managing token costs.
EvoEmbedding Architecture Refer to the framework diagram, EvoEmbedding sequentially processes segments split from a long input sequence. Given the current input segment xt and the latent memory Mt−1, the model performs memory evolution and representation generation tasks in parallel. This process is formulated as:
M~t=πθm(xt,Mt−1),vt=πθr(xt,Mt−1),where θm and θr denote the task-relevant parameters, M~t∈RK×D represents the newly generated K latent tokens, and vt∈RDemb is the corresponding vector. During the query phase, only the representation generation task is executed. This formulation allows the model to dynamically maintain a latent memory as the global semantic context.
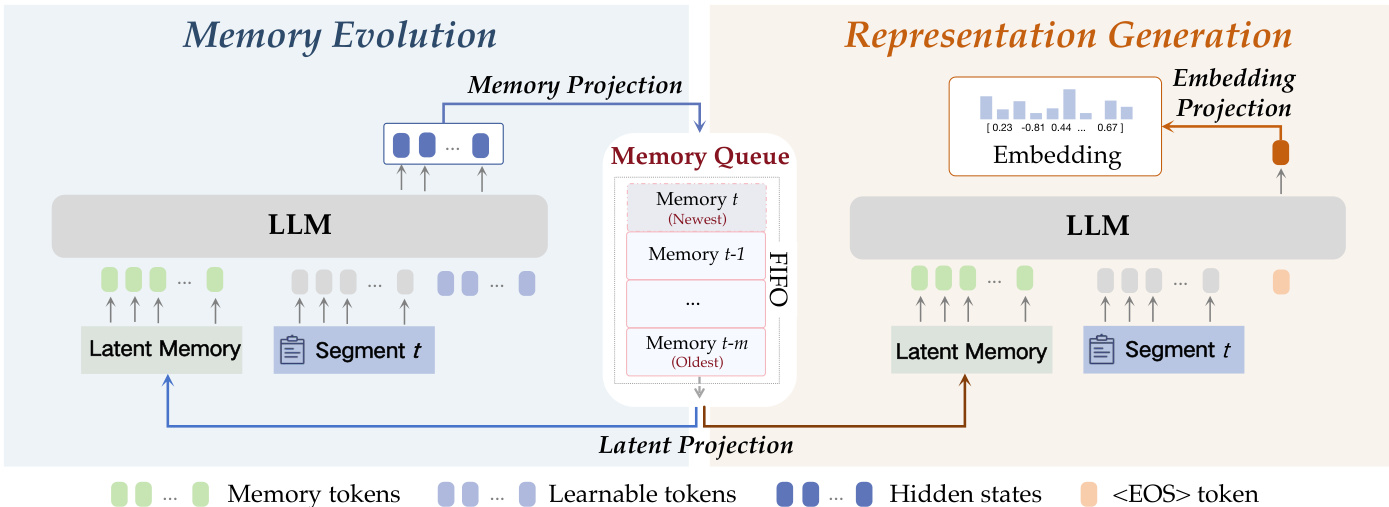
To manage the latent memory, the authors design a queue mechanism. The updated memory Mt is constructed as:
Mt=Queue(Mt−1,fm(Mt)),where Mt∈RC×D is a First-In-First-Out (FIFO) queue matrix with capacity C=L×K. This queue-based design guarantees that historical memory is loop-encoded at most L times, avoiding collapse from recurrent encoding, and strictly limits memory size to bound computational complexity. To overcome efficiency challenges, a Dynamic Segment-Batching technique is introduced. Instead of executing forward passes segment-by-segment, the model processes k consecutive segments in parallel, ensuring the total length does not exceed a predefined threshold.
Training and Optimization EvoEmbedding is initialized from general language models and employs a multi-LoRA design to decouple memory evolution and representation generation capabilities. This allows flexible switching during inference and isolates training dynamics to avoid catastrophic forgetting. Given an input sample of t segments and a query q, the model constructs latent memory Mt and obtains embeddings. The model is jointly optimized using a combined objective:
L=Lmem+Lcon,where Lmem is the memory generation loss and Lcon is the contrastive representation loss. The memory generation loss is measured using standard cross-entropy to predict the target answer y using the generated latent memory and query as context:
Lmem=−i=1∑∣y∣logP(yj∣y<j,q,Mt).During this step, backbone parameters are frozen and LoRA adapters are deactivated, forcing loss backpropagation directly into the latent memory to ensure compatibility with the base semantic space.
The contrastive loss aligns the query representation with relevant contexts. The candidate pool is partitioned from the current sample segments into positive sets containing supporting evidence and negative sets. A length-weighted multi-positive contrastive loss is formulated:
Lcon=Plog(N+1)i=1∑P(−logexp(vq⊤vi+/τ)+∑j=1Nexp(vq⊤vj−/τ)exp(vq⊤vi+/τ)),where vq is the normalized query embedding and τ=0.1. The factor log(N+1) adaptively calibrates the loss scale based on the number of negative distractors.
To support this training, the authors construct a specialized dataset. As shown in the figure below, the pipeline comprises raw context construction across diverse domains, dynamic QA generation utilizing large language models and templates, and a formulation stage for retrieval labeling and verification to filter noisy samples.
Experiment
Extensive evaluations across ten benchmarks covering long-context retrieval, conversational memory, and personalization tasks show that EvoEmbedding consistently outperforms static embedding models and specialized agentic memory systems. The model generates contextually evolvable representations that capture temporal dynamics, enabling it to generalize to up to 128K contexts despite training on significantly shorter samples. A naive RAG pipeline using EvoEmbedding achieves state-of-the-art generation accuracy with zero token overhead for memory construction, surpassing complex memory-augmented architectures. Analyses further confirm the model's inherent temporal reasoning capabilities and the efficiency of its latent memory design, which dramatically reduces GPU memory usage while maintaining top performance.
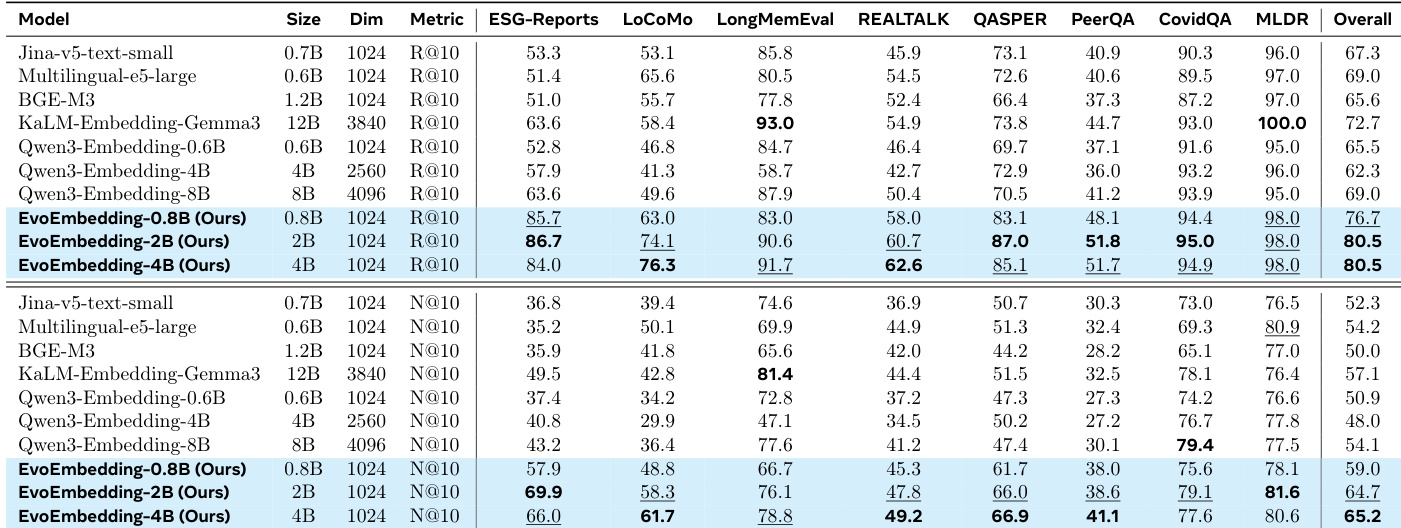
The authors evaluate the retrieval performance of the EvoEmbedding family against various state-of-the-art embedding models across multiple long-context and conversational benchmarks. Results show that EvoEmbedding models consistently achieve superior overall performance in both Recall and NDCG metrics compared to larger baselines. The proposed models demonstrate strong scalability, with even the smallest variant outperforming much larger generalist embedding models. EvoEmbedding variants achieve the highest overall retrieval performance across all evaluated benchmarks, surpassing larger models like KaLM-Embedding-Gemma3 and Qwen3-Embedding. The smallest EvoEmbedding model outperforms significantly larger baselines in overall Recall, demonstrating high parameter efficiency. EvoEmbedding models exhibit robust performance across diverse domains, securing top results in specialized benchmarks such as ESG-Reports and PeerQA.
The authors conduct an ablation study to evaluate the key design components of EvoEmbedding. The results demonstrate that the latent memory mechanisms are fundamental to the model's performance, as their removal leads to catastrophic degradation. Additionally, the proposed batching and weighting strategies are critical for training efficiency and overall accuracy. The latent memory queue and memory loss are essential components, as removing either leads to catastrophic performance degradation on conversational benchmarks. Segment-batching drastically accelerates the training process while simultaneously improving overall model performance. Length-weighting effectively balances sample difficulty and context length, preventing bias toward shorter sequences and enhancing accuracy.

The authors evaluate EvoEmbedding-4B on a conversational benchmark using a naive RAG pipeline, comparing it against full context baselines, agentic memory systems, and other embedding models. Results indicate that EvoEmbedding achieves the highest overall performance among retrieval-based methods, closely approaching the full context upper bound. However, while it excels in single-hop and multi-hop tasks, it falls behind specialized agentic memory systems on temporal and open-domain subtasks. EvoEmbedding-4B achieves the highest overall accuracy among all tested embedding and agentic memory baselines. The model shows superior performance in single-hop and multi-hop tasks compared to both static embeddings and agentic systems. Specialized agentic memory systems like LightMem outperform EvoEmbedding on temporal and open-domain subtasks.
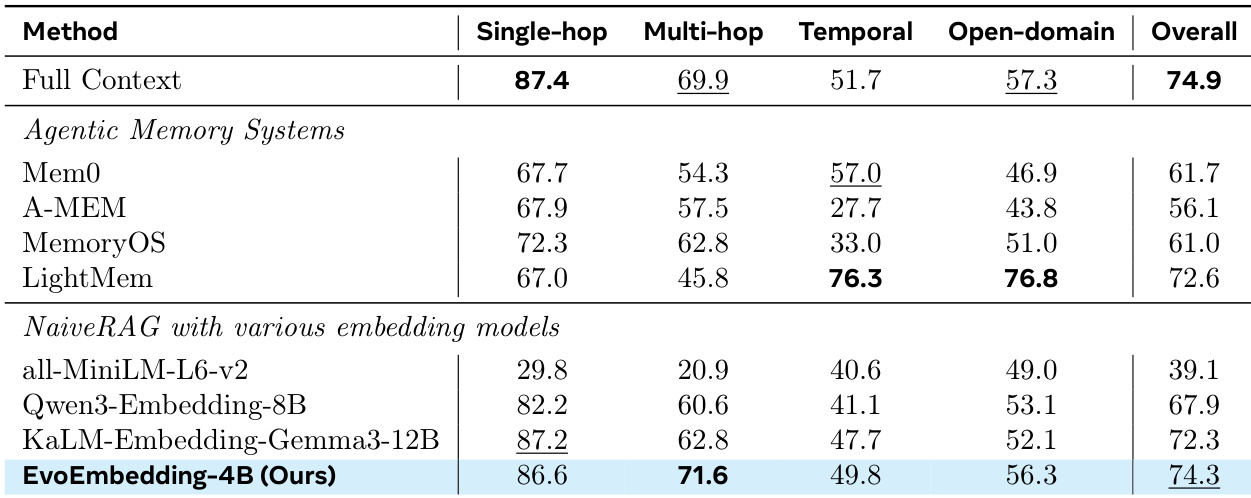
The authors evaluate EvoEmbedding across multiple long-context and conversational benchmarks using a naive RAG pipeline with varying retrieval budgets. Results show that EvoEmbedding consistently achieves the highest overall performance compared to established static embedding baselines and lexical retrieval methods. The model also demonstrates strong scalability, with larger variants yielding superior accuracy across different top-k retrieval settings. EvoEmbedding-4B achieves the best overall generation accuracy across all tested top-k values, outperforming larger static embedding models. The EvoEmbedding family exhibits strong scalability, with smaller variants also surpassing many larger baseline models. Performance remains robust across diverse long-context tasks, demonstrating the model's effectiveness in handling varying retrieval budgets.
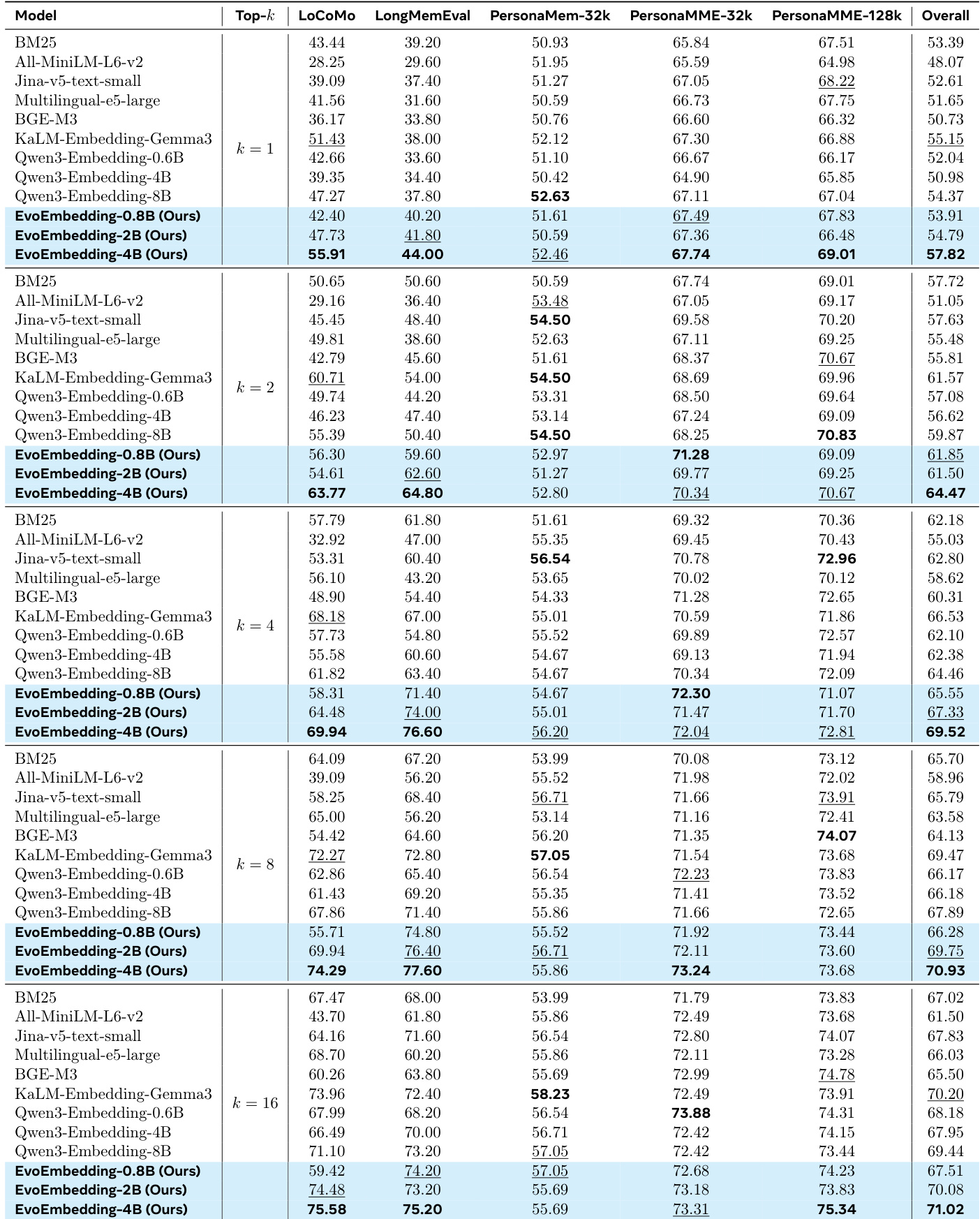
The authors evaluate their proposed EvoEmbedding model on a conversational benchmark, comparing it against full-context baselines, agentic memory systems, and other embedding models. Results show that a naive retrieval pipeline equipped with EvoEmbedding achieves the highest overall accuracy, significantly outperforming specialized agentic memory architectures and even surpassing the full-context baseline. The model demonstrates exceptional performance in single-user and single-assistant subtasks, indicating its strong capability in filtering noisy histories and capturing relevant context. EvoEmbedding achieves the best overall performance across most evaluation categories, including temporal reasoning and multi-session dialogue. The model reaches near-perfect accuracy on single-user and single-assistant tasks, substantially outperforming existing agentic memory systems. A standard retrieval pipeline using EvoEmbedding surpasses the full-context baseline, proving its effectiveness in handling long-context retrieval without explicit memory construction.
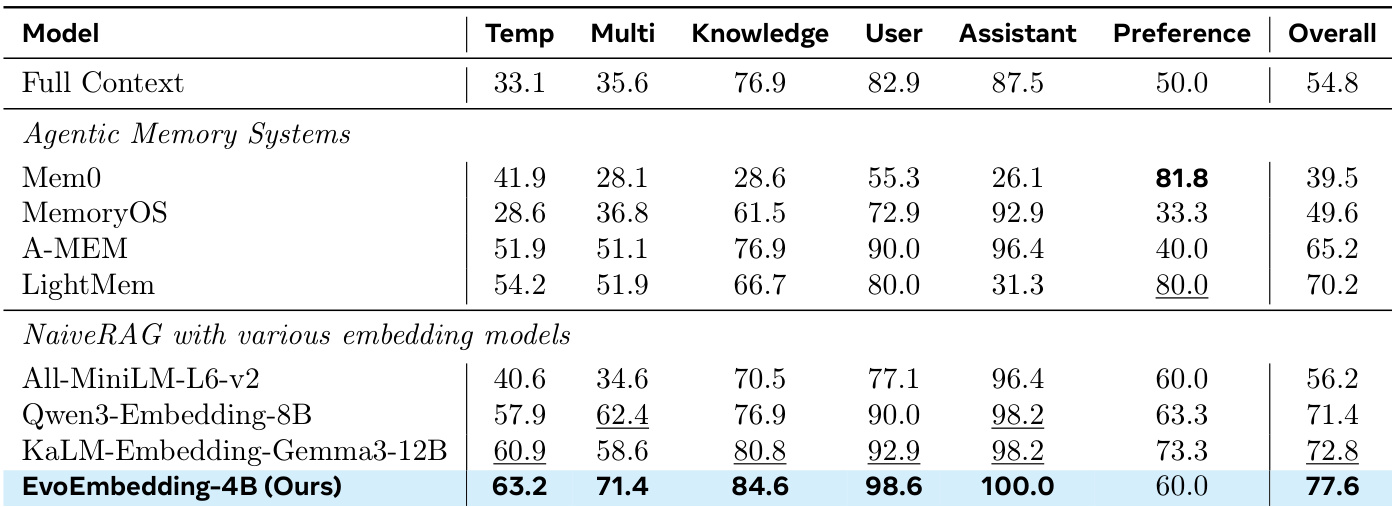
The evaluation assesses the EvoEmbedding family on long-context and conversational retrieval benchmarks, comparing them to larger static embedding models, agentic memory systems, and full-context baselines. Results show that EvoEmbedding models consistently achieve the highest retrieval and generation accuracy, with even the smallest variant outperforming much larger counterparts, demonstrating strong scalability and parameter efficiency. Ablation highlights the critical role of latent memory mechanisms, segment-batching, and length-weighting, while retrieval pipelines using EvoEmbedding surpass specialized agentic systems and approach the full-context upper bound, particularly excelling in single-hop and multi-hop tasks.