Command Palette
Search for a command to run...
OpenThoughts-Agent: Data Recipes for Agentic Models
OpenThoughts-Agent: Data Recipes for Agentic Models
Abstract
Agentic language models dramatically expand the applications of AI yet little is publicly known about how to curate training data for broadly capable agents. Existing open efforts such as SWE-Smith, SERA, and Nemotron-Terminal typically target a single benchmark, leaving open the question of how to train models that generalize across diverse agentic tasks. The OpenThoughts-Agent (OT-Agent) project addresses this gap with a fully open data curation pipeline for training agentic models. We conduct more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline, yielding insights on the importance of task sources and diversity. We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks and a 3.9 percentage point improvement over the strongest existing open data agentic model (Nemotron-Terminal-32B, 40.9%). Moreover, our training data exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons. We publicly release our training sets, data pipeline, experimental data, and models at openthoughts.ai to support future open research on agentic model training.
One-sentence Summary
The authors introduce the OpenThoughts-Agent project, a fully open data curation pipeline refined through over one hundred ablation experiments, demonstrating that fine-tuning Qwen3-32B on the resulting 100K-example dataset achieves a 44.8% average accuracy across seven agentic benchmarks, a 3.9 percentage point improvement over Nemotron-Terminal-32B, while exhibiting strong scaling properties and publicly releasing all datasets, pipeline code, and models to support future agentic model research.
Key Contributions
- The OpenThoughts-Agent project provides a fully open data curation pipeline that systematically handles data sourcing, labeling, and filtration for training agentic language models. The complete training datasets, data pipeline, experimental logs, and fine-tuned models are publicly released to enable reproducible research.
- Over 100 controlled ablation experiments systematically isolate the impact of each pipeline stage and yield actionable insights on task source diversity and the interaction between supervised fine-tuning and reinforcement learning data.
- Fine-tuning Qwen3-32B on the curated 100K-example dataset achieves a 44.8 percent average accuracy across seven agentic benchmarks, representing a 3.9 percentage point improvement over the strongest existing open-data baseline. Compute-controlled evaluations further demonstrate that the dataset exhibits strong scaling properties, consistently outperforming alternative open corpora at every training size.
Introduction
Agentic language models have transformed AI by enabling systems to execute complex, multi-step computer tasks, making high-quality training data essential for advancing open research and real-world deployment. However, existing open data curation efforts typically target single benchmarks or isolate supervised fine-tuning from reinforcement learning, leaving a critical gap in understanding how to build broadly capable, generalizable agents. To address this, the authors leverage a fully transparent data curation pipeline systematically refined through over one hundred ablation experiments. They assemble a diverse 100K example dataset, fine-tune Qwen3-32B, and demonstrate strong cross-benchmark generalization and superior scaling behavior while publicly releasing all artifacts to accelerate future agentic AI research.
Dataset

-
Dataset Composition and Sources: The authors construct the OpenThoughts-Agent dataset as a collection of (task, trajectory) pairs optimized for supervised fine-tuning coding and terminal agents. The final dataset draws from four primary sources: SWE-Smith (synthetic GitHub issue-resolution tasks), IssueTasks (synthetic issue descriptions), StackExchange SuperUser (human-written Linux and infrastructure questions), and StackExchange Tezos (human-written cryptocurrency questions). These sources collectively span software engineering, system administration, security, biology, and machine learning domains.
-
Subset Details and Scaling: Initial pipeline ablations generate 10,000 trajectories per strategy to balance computational cost with statistical reliability. The final OpenThoughts-Agent-v2 dataset scales to 100,000 agentic traces. Because the Tezos source contains only 997 unique task descriptions, the authors synthetically augment it using instruction-rewriting techniques to expand its surface forms to over 21,000 variations without introducing new underlying problems. The remaining three sources retain their original task pools.
-
Training Usage and Mixture Ratios: The data is used for full-parameter supervised fine-tuning of Qwen3-8B during ablation studies and a 32B model for final scaling. Trajectories are generated by GLM-4.7-AWQ acting as a teacher within isolated Daytona sandboxes using the terminus-2 agent harness. For the 100K dataset, the authors maintain the top-four source mix and apply a proportional upsampling strategy based on a GPT-5-nano response-length signal. Every unique task receives at least one rollout, with remaining capacity allocated proportionally to its quality score to ensure full task coverage across all dataset scales.
-
Processing and Filtering Rules: The pipeline applies strict heuristic filters to agentic rollouts. The authors discard traces that timeout during generation, remove subagent traces, and filter out any trajectory containing fewer than five turns. This five-turn minimum is enforced uniformly across all sources to prioritize higher-quality multi-turn supervision. The authors verify that performance gains from longer traces persist even when matched against a fixed token budget, confirming the benefit stems from richer supervisory signals rather than additional compute.
Method
The authors introduce a structured six-stage supervised fine-tuning (SFT) data curation pipeline designed to generate high-quality training data for agentic models. This framework systematically transforms raw inputs into a finalized dataset through a sequence of mixing, filtering, and generation steps.
Refer to the framework diagram:

The process begins with Source Tasks, which serve as the raw input pool. These tasks are then subjected to a Mix Tasks phase, where diverse task types are combined to ensure broad coverage and robustness. Following the mixing, the Filter Tasks stage applies criteria to remove low-quality or irrelevant tasks from the pool before generation.
Once the task set is refined, the pipeline moves to the Generate Rollouts phase. Here, trajectories are produced for the selected tasks, simulating agent behavior. These generated rollouts are then evaluated in the Filter Rollouts stage, where only high-quality, successful trajectories are retained.
The final stages involve model selection and dataset assembly. In the Select Teacher phase, a specific model is chosen to act as the teacher for generating the final data or for further refinement. This culminates in the creation of the Final Recipe, which represents the curated dataset ready for supervised fine-tuning. The authors note that this pipeline was subjected to controlled ablations to understand the contribution of each stage.
Experiment
The evaluation setup combines supervised fine-tuning and reinforcement learning across multiple coding and agentic benchmarks to systematically validate task generation, data mixing, filtering, teacher selection, and reinforcement learning data sourcing. Qualitative findings indicate that blending top-ranked generation strategies and filtering for complex problems produces the most balanced training data, while the strongest benchmark model does not necessarily serve as the most effective teacher. Reinforcement learning ablations further demonstrate that moderately strong supervised checkpoints benefit most from policy optimization, with data sources critically dictating behavioral trajectories: competitive programming-style tasks foster productive exploration and rigorous tool use, whereas alternative datasets encourage policy compaction. Overall, the experiments confirm that carefully curated, multi-turn agentic trajectories consistently enhance downstream reasoning and scale reliably across model sizes.
The authors evaluate different strategies for filtering task descriptions to improve downstream agent performance. They find that filtering based on the response length generated by GPT-5 is the most effective method, specifically by selecting tasks that require longer responses. This approach consistently outperforms other filtering techniques and the random baseline across all tested benchmarks. Filtering tasks by GPT-5 response length, particularly for longer responses, achieves the best overall performance. This strategy yields a significant improvement of approximately 3 percentage points over the random baseline. Tasks identified as requiring more tokens to solve demonstrate consistent gains across diverse benchmarks.

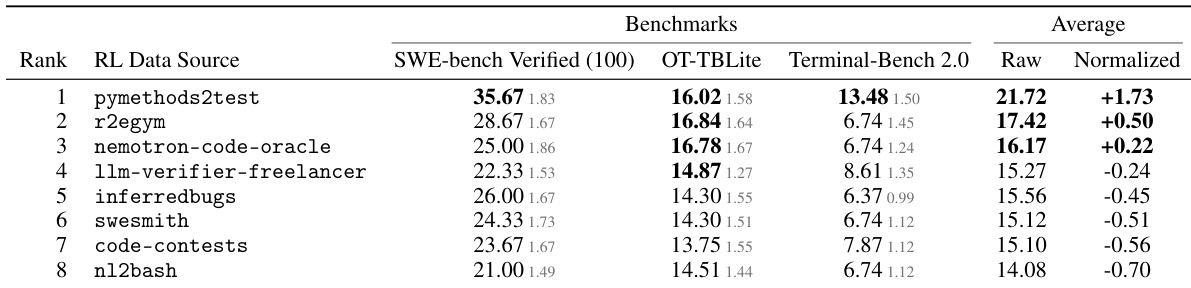
The authors evaluate various reinforcement learning data sources to train an 8B model, ranking them based on performance across multiple software engineering and terminal benchmarks. The results indicate that the choice of training data significantly impacts downstream performance, with competitive programming-style tasks yielding the highest overall accuracy. While specialized synthetic sources excel on in-distribution benchmarks, broader tool-use datasets show stronger generalization to out-of-distribution tasks, though neither matches the balanced performance of the top-ranked source. The top-ranked data source, derived from competitive programming problems, achieves the highest average performance across all evaluated benchmarks. Synthetic and competitive programming sources demonstrate stronger performance on in-distribution tasks compared to more heterogeneous tool-use datasets. Broader tool-use sources provide better out-of-distribution generalization, though they lag behind the leading source on in-distribution evaluations.
The authors evaluate a representative baseline model on both Terminal-Bench 2.0 and its updated version, Terminal-Bench 2.1, to assess the impact of benchmark revisions. The results indicate only a marginal improvement in accuracy on the newer benchmark compared to the original. Performance remains relatively stable across the two benchmark versions. The accuracy gap between the original and revised benchmarks is minimal for the tested model. This stability supports the decision to primarily report results on the initial benchmark version.

The authors analyze the impact of dataset scaling on 32B model fine-tuning by adjusting training hyperparameters across different data volumes. Smaller datasets are trained for more epochs with looser gradient clipping, whereas larger datasets use fewer epochs with stricter gradient constraints. This results in a proportional increase in wall-clock time as the dataset size grows. Adaptive Training Strategy: The experimental setup varies hyperparameters based on data scale, employing more epochs and looser gradient clipping for smaller datasets while reducing epochs and tightening clipping for larger ones. Scalability of Training Time: Wall-clock duration increases significantly with data volume, extending from a short duration for the smallest dataset to a much longer period for the largest dataset. Recipe Classification: The experiments categorize training runs into two distinct recipe labels, with the larger data scales consistently utilizing the same specific configuration.

The authors investigate the impact of mixing different task generation strategies on model performance. Results indicate that combining the top-ranked strategies, specifically mixing the top 4 to 8, yields the strongest balanced performance across all evaluated benchmarks. This approach outperforms using a single strategy by avoiding over-specialization and maintaining high accuracy on diverse tasks. Mixing the top 4 to 8 task generation strategies achieves the highest performance across all benchmarks. This mixed approach avoids over-specialization compared to using a single top-ranked strategy. Performance decreases when mixing too many strategies, such as the top 16.

Through a series of controlled evaluations on data filtering, training sources, benchmark revisions, scaling protocols, and strategy combinations, the study validates key factors in optimizing model performance. Filtering tasks by predicted response length effectively isolates challenging problems that consistently enhance agent capabilities, while competitive programming datasets emerge as the most robust training foundation compared to specialized or broad tool-use sources. Benchmark updates show minimal accuracy shifts, confirming evaluation stability, and training scales predictably with dataset volume using adaptive hyperparameter adjustments. Additionally, strategically blending a moderate number of task generation methods prevents over-specialization and maximizes balanced performance across diverse evaluations.