Command Palette
Search for a command to run...
Agent Harness Engineering: A Survey
Agent Harness Engineering: A Survey
Abstract
The rapid deployment of large language model (LLM) agents in production has revealed a recurring pattern: task execution reliability depends less on the underlying model than on the infrastructure layer that wraps it, the agent execution harness. This survey provides a practice-grounded, systematic treatment of agent harness engineering, organized around three claims. First, the agent harness is an independent system layer whose engineering quality drives a large share of real-world reliability, a position we develop through a three-phase engineering evolution from prompt to context to harness engineering, a cross-layer synthesis covering the cost-quality-speed trilemma, the capability-control tradeoff, and the harness coupling problem, and an open-problem agenda grounded in both research gaps and production pain points. Second, we propose ETCLOVG, a seven-layer taxonomy (Execution environment, Tool interface, Context management, Lifecycle/Orchestration, Observability, Verification, Governance) that extends prior six-component frameworks by treating observability and governance as independent architectural concerns.
One-sentence Summary
This survey provides a practice-grounded, systematic treatment of agent harness engineering, arguing that the infrastructure layer drives LLM agent reliability more than the underlying model, and introduces ETCLOVG, a seven-layer taxonomy extending prior six-component frameworks by treating observability and governance as independent architectural concerns to address production pain points and the cost-quality-speed trilemma.
Key Contributions
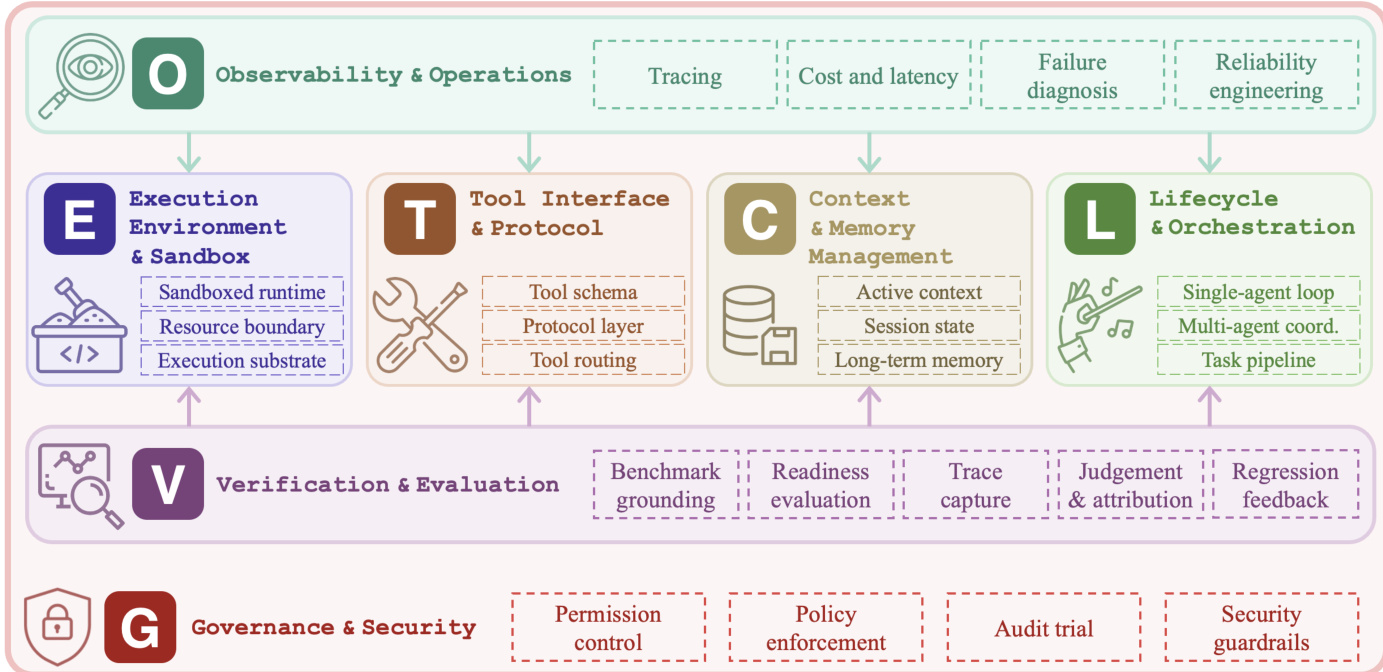
- The paper introduces ETCLOVG, a seven-layer taxonomy encompassing Execution environment, Tool interface, Context management, Lifecycle/Orchestration, Observability, Verification, and Governance. This framework extends prior six-component models by treating Observability and Governance as independent architectural concerns.
- A mapping of over 148 open-source projects onto the taxonomy provides the most extensive ecosystem snapshot to date. This analysis surfaces adoption patterns, coverage gaps, and emerging design principles within the agent infrastructure landscape.
- The work establishes the agent harness as an independent system layer driving real-world reliability through a three-phase engineering evolution from prompt to context to harness engineering. This synthesis covers the cost-quality-speed trilemma, capability-control tradeoff, and harness coupling problem to situate harness engineering within a broader trajectory.
Introduction
The rapid deployment of large language model agents in production reveals that task reliability depends less on the underlying model than on the infrastructure layer wrapping it. Prior research has focused heavily on model capabilities while practitioners lack the formal vocabulary to systematically improve the integrating system. The authors address this gap by advancing the binding-constraint thesis, which positions the agent harness as the primary driver of real-world reliability. They introduce ETCLOVG, a seven-layer taxonomy that treats observability and governance as independent architectural concerns rather than side effects. Additionally, the team maps over 140 open-source projects to this framework to identify ecosystem patterns and distill engineering principles from production deployments.
Dataset
- Dataset Composition and Sources: The authors constructed a systematic corpus mapping publicly documented agent-harness artifacts from four streams: prior surveys, GitHub searches, curated lists, and company engineering blogs.
- Key Subsets and Examples: The collection includes general-purpose sandboxes like Daytona and E2B, computer-use infrastructure such as Anthropic Computer Use, and browser environments like WebArena. Software engineering benchmarks including SWE-bench and Terminal-Bench are also mapped.
- Usage and Analysis: The dataset serves as a map of the visible agent-harness ecosystem rather than a training split. The authors use it to assign artifacts to seven ETCLOVG layers based on public evidence.
- Processing and Metadata: Projects were filtered to exclude simple chatbots and static datasets. Metadata such as project names and release years were recorded in a snapshot frozen on May 08, 2026. Coding followed a single-primary-coder protocol with author audit.
Method
The authors propose a seven-layer taxonomy for agent harness engineering, referred to by the acronym ETCLOVG, which stands for Execution, Tooling, Context, Lifecycle, Observability, Verification, and Governance. This framework distinguishes between the structural core of a harness and the control plane surrounding it. The first four layers describe the structural core. Execution (E) determines where agent code runs and what sandbox constraints bound it. Tooling (T) specifies how external capabilities are described, discovered, and invoked. Context (C) controls what the model can see over short-term, session-level, and persistent horizons. Lifecycle (L) organizes the control flow that reads and writes that state, ranging from single-agent loops to multi-agent workflows.
The remaining three layers describe the control plane. Observability (O) captures traces, costs, failures, and reliability signals. Verification (V) turns tasks and traces into evaluation, failure attribution, and regression feedback. Governance (G) constrains behavior through permission, identity, policy, hardening, audit, and human oversight mechanisms. Two design choices distinguish this taxonomy. First, Observability is promoted to an independent layer rather than treated as a side effect of lifecycle hooks. Second, Governance is introduced as a first-class layer that captures the full spectrum of security and compliance concerns.
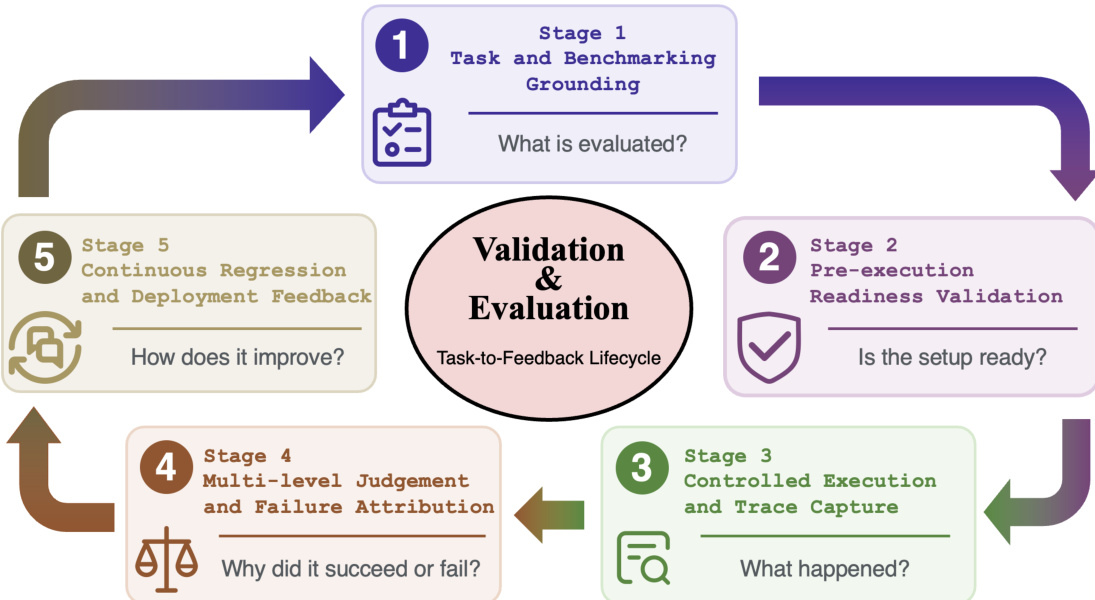
Verification and evaluation is organized as a task-to-feedback lifecycle. This process begins with task and benchmark grounding, followed by pre-execution readiness validation. Controlled execution and trace capture run the agent under reproducible conditions. Multi-level judgement and failure attribution evaluate the run at outcome, trajectory, and evaluator levels. Finally, continuous regression and deployment feedback convert results into engineering evidence for harness improvement. This lifecycle reframes evaluation from a leaderboard mechanism into a quality-control loop for agent harnesses.
Governance is integrated through lifecycle hooks that define when policy checks fire. Many harnesses expose hook points at each stage of the agent loop. Pre-execution hooks validate input before it reaches the LLM. Pre-invocation hooks inspect the proposed action before tool execution. Post-execution hooks mediate information flow from tool output back into context. Human-in-the-loop hooks gate consequential actions on user approval. These hooks allow governance logic to be injected without modifying the agent's core reasoning.

Experiment
An aggregate analysis of over 170 projects indicates that execution and tooling infrastructure are mature, whereas governance and observability remain fragmented across open-source ecosystems. Memory system experiments validate various architectural strategies, including hybrid storage and collective learning, demonstrating a shift from research prototypes to production-ready infrastructure. Evaluation frameworks prioritize pre-execution readiness and trajectory-level analysis to ensure reproducibility and generate specific engineering feedback, while governance gaps highlight the need for standardized policies and unified adversarial benchmarks to support safe deployment.