HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights

Evolutionary Caching to Accelerate Your Off-the-Shelf Diffusion Model





























Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
Evolutionary Caching to Accelerate Your Off-the-Shelf Diffusion Model
RE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation
SonicVerse: Multi-Task Learning for Music Feature-Informed Captioning
All is Not Lost: LLM Recovery without Checkpoints
Sundial: A Family of Highly Capable Time Series Foundation Models
ADRD: LLM-Driven Autonomous Driving Based on Rule-based Decision Systems
Improved Iterative Refinement for Chart-to-Code Generation via Structured Instruction
Show-o2: Improved Native Unified Multimodal Models
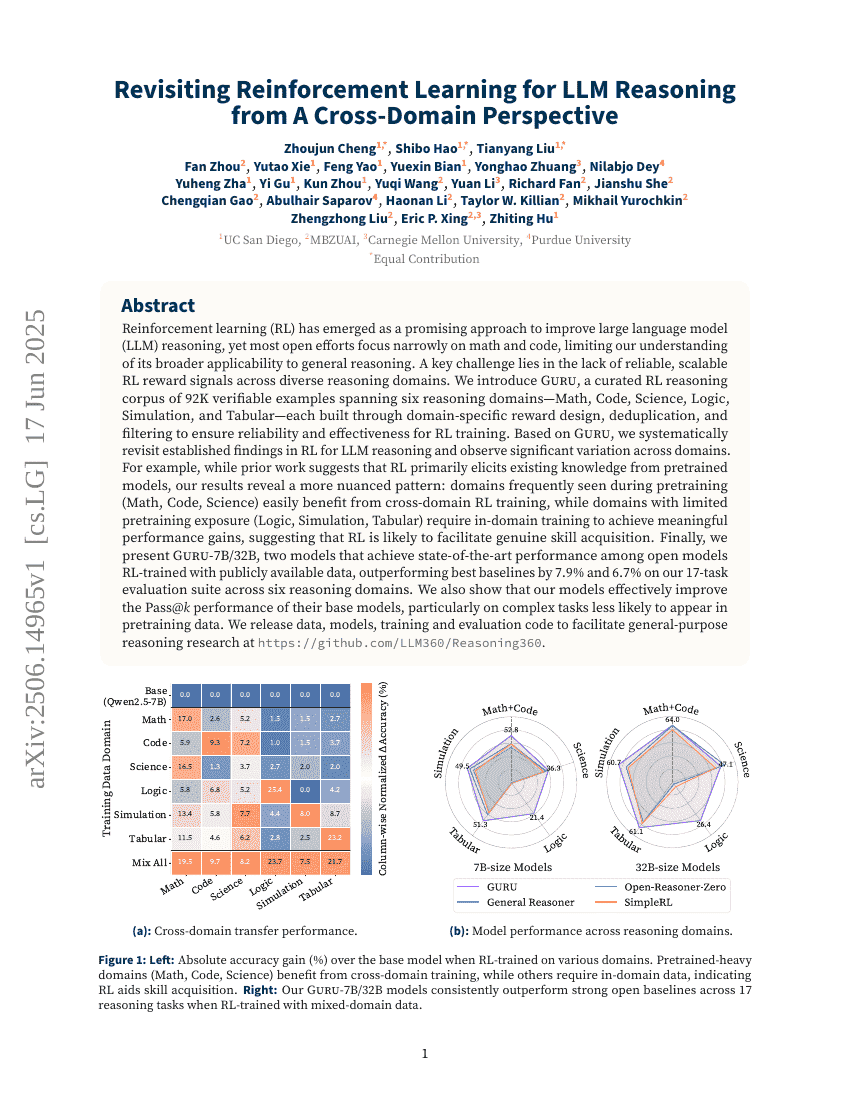
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Raptor: Scalable Train-Free Embeddings for 3D Medical Volumes Leveraging Pretrained 2D Foundation Models
EmoNet-Voice: A Fine-Grained, Expert-Verified Benchmark for Speech Emotion Detection
s1: Simple test-time scaling
Search-o1: Agentic Search-Enhanced Large Reasoning Models
LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
GPT-4o System Card
SAM2Long: Enhancing SAM 2 for Long Video Segmentation with a Training-Free Memory Tree
Aria: An Open Multimodal Native Mixture-of-Experts Model
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
VGGT: Visual Geometry Grounded Transformer
Multi-Turn Code Generation Through Single-Step Rewards
Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability
Embodied Web Agents: Bridging Physical-Digital Realms for Integrated Agent Intelligence
Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
BUT System for the MLC-SLM Challenge
GenRecal: Generation after Recalibration from Large to Small Vision-Language Models
ProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs
Sekai: A Video Dataset towards World Exploration
Data-driven material screening of secondary and natural cementitious precursors
RE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation
SonicVerse: Multi-Task Learning for Music Feature-Informed Captioning
All is Not Lost: LLM Recovery without Checkpoints
Sundial: A Family of Highly Capable Time Series Foundation Models
ADRD: LLM-Driven Autonomous Driving Based on Rule-based Decision Systems
Improved Iterative Refinement for Chart-to-Code Generation via Structured Instruction
Show-o2: Improved Native Unified Multimodal Models
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Raptor: Scalable Train-Free Embeddings for 3D Medical Volumes Leveraging Pretrained 2D Foundation Models
EmoNet-Voice: A Fine-Grained, Expert-Verified Benchmark for Speech Emotion Detection
s1: Simple test-time scaling
Search-o1: Agentic Search-Enhanced Large Reasoning Models
LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
GPT-4o System Card
SAM2Long: Enhancing SAM 2 for Long Video Segmentation with a Training-Free Memory Tree
Aria: An Open Multimodal Native Mixture-of-Experts Model
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
VGGT: Visual Geometry Grounded Transformer
Multi-Turn Code Generation Through Single-Step Rewards
Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability
Embodied Web Agents: Bridging Physical-Digital Realms for Integrated Agent Intelligence
Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
BUT System for the MLC-SLM Challenge
GenRecal: Generation after Recalibration from Large to Small Vision-Language Models
ProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs
Sekai: A Video Dataset towards World Exploration
Data-driven material screening of secondary and natural cementitious precursors