Command Palette
Search for a command to run...
ICLR 2026 | 125x Reduction in Trainable Parameters Per Task! New Method Task Tokens Helps Embodied Intelligence Enhance Complex Task Capabilities

In recent years, advances in imitation learning in the field of robot control have spurred the development of Transformer-based Behavior Foundation Models (BFMs), which enable multimodal control of humanoid intelligent agents. These models generate solutions given high-level goals or cues, such as guiding a robot to a specific coordinate given its pelvic position. While BFMs excel at generating robust behaviors with zero-shot examples, they often require sophisticated prompt engineering when performing specific tasks, which can lead to suboptimal results.
In this context,A research team from the Technion – Israel Institute of Technology has proposed a method called Task Tokens, which can effectively adapt BFM to specific tasks while maintaining its flexibility.Compared to standard baseline methods, the new method can reduce the number of trainable parameters per task by up to 125 times and improve convergence speed by up to 6 times.
Meanwhile, researchers also validated the effectiveness of Task Tokens in various tasks (including out-of-distribution scenarios) and demonstrated their compatibility with other prompting methods. Experimental results show that Task Tokens provide a promising solution for adapting BFM to specific control tasks while maintaining generalization capabilities.
The related research findings, titled "Task Tokens: A Flexible Approach to Adapting Behavior Foundation Models," have been accepted for ICLR 2026.
Research highlights:
* Task-specific adaptation: Task Tokens adapt MaskedMimic (GC-BFM) to specific tasks through tokenized control, without requiring fine-tuning of the base model, while retaining its zero-shot capability.
* Hybrid Control Paradigm: Enables seamless integration of user-defined high-level priors (such as text or joint objectives) with reward-based learning optimization.
* Performance and generalization ability: It is comparable to the full fine-tuning method in terms of task performance, while outperforming other methods in terms of robustness to changes in environmental dynamics (such as gravity and friction).

Paper address:
https://hyper.ai/papers/2503.22886
View more cutting-edge AI papers:
Task set: Testing the model's generality in a series of near-real-world scenarios.
The study designed a set of standardized tasks to test the model’s generality and adaptability in a range of near-real-world scenarios, with each task introducing different levels of complexity into the control problem.
Direction (walking in a specific direction)
This task requires the character to move in a specified direction to test the model's capabilities in basic walking control and target orientation alignment. The success criterion is that, within the measurement time, the humanoid model's velocity deviation along the target direction does not exceed 20% of the target velocity.
Steering
This task requires a humanoid model to move along a specified direction while maintaining its pelvis facing a specific direction. This tests more refined motion control capabilities and introduces more complex scenarios. The success criterion is that the character maintains a target direction velocity deviation of no more than 20% while its total orientation deviation does not exceed 45°.
Reach
In this task, the humanoid model needs to reach a designated coordinate point with its right hand. This requires high precision in the movement. The success criterion is that the distance between the right hand position and the target position is less than 20 centimeters.
Strike
The task requires the character to first walk to the vicinity of the target, and then perform an action to knock the target down. This not only tests basic walking ability, but also examines complex task-oriented behaviors, including time control and spatial awareness. The success criterion is that the target object is knocked down and tilts in a certain posture, with its deviation angle not exceeding approximately 78°.
Long Jump
The character needs to run up in a 1-meter-wide tunnel, cross a line after 20 meters and jump, and must not touch the ground again after crossing the take-off line. The standard for success is a jump distance of more than 1.5 meters.
Efficient task adaptation solution based on MaskedMimic architecture
The method proposed in this study is based on a "Goal-Conditioned Behavior Foundation Models (GC-BFMs)" called MaskedMimic. Unlike traditional GCRL methods that rely on reward signals for learning,MaskedMimic combines the Transformer architecture and performs random masking on the future targets used as input tokens.This enables the learning and reproduction of human-like behavior from multiple modalities, such as future joint positions, text instructions, and interactive objects.
This combination of architecture and control mechanisms makes MaskedMimic an ideal foundation for the Task Tokens approach; on top of this, researchers further enhance its capabilities by learning task-specific tokens to optimize downstream task performance.
Task Tokens
As shown in the diagram below, Task Tokens integrates three types of input sources:
* Prior Token: Optional input used to introduce user-defined behavioral priors via text prompts or joint conditions;
* Task Token: Generated by a trained task encoder that processes the current target observation;
* State Token: Represents the current state of the environment.
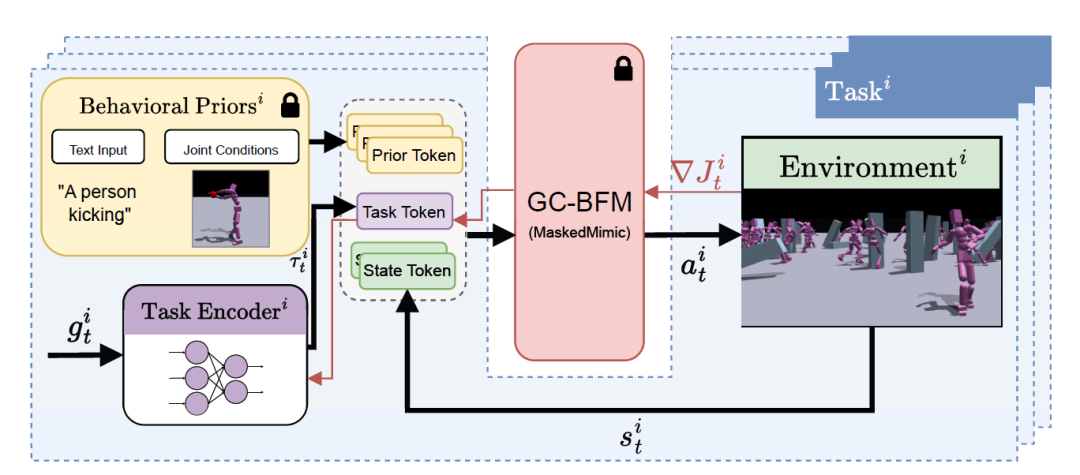
Researchers trained a dedicated task encoder for each new task to generate corresponding unique tokens. These task tokens encapsulate the unique requirements and constraints of the target behavior, providing concise yet informative guiding signals to the base model, enabling it to generate outputs that meet the specific task requirements while maintaining general behavioral priors.
Task Encoder
The task encoder receives observations that define the current task objective. These observations are represented with the agent itself as the frame of reference, and output a Task Token. The form of observations varies depending on the task—for example, in a turning task, the observations include the target's direction of motion, orientation, and desired velocity.
Since MaskedMimic is trained based on future pose targets, the task encoder also receives proprioceptive information to align with the pre-trained representation, thereby generating meaningful target signals.
The researchers implemented the task encoder as a feedforward neural network. Its output (i.e., the Task Token) is concatenated with other encoder tokens in the BFM input space to form a token "sentence." In this structure, the tokens output by the task encoder are equivalent to specialized "words" used to guide the model to complete a specific task while maintaining the naturalness of the actions.
Training
To adapt the task encoder to new downstream tasks, researchers employed Proximal Policy Optimization (PPO). During training, the BFM predicts the action probability distribution based on a combination of input tokens, including the Task Token. The PPO objective function is then computed based on the task-specific reward and the action probabilities output by the BFM, thus obtaining the gradients used to update the task encoder parameters while keeping the BFM itself frozen.
Efficiently and effectively adapt BFM to specific tasks
Researchers evaluated the effectiveness of the Task Tokens method through a series of comprehensive experiments, validating its performance and applicability in four key aspects, and comparing it with several competitive baseline methods, including:
Pure RL: Uses only the PPO training strategy and does not depend on any base model;
* MaskedMimic Fine-Tune: Optimizes the entire MaskedMimic model using the reward signal (without freezing parameters);
* MaskedMimic (Joint Condition Only): The original MaskedMimic, which only uses joint conditions as a cue mechanism;
* PULSE: A hierarchical approach that reuses the latent skill space in motion capture data;
* AMP: Utilizes a discriminator to optimize task performance while ensuring action quality.
Task Adaptation Capability
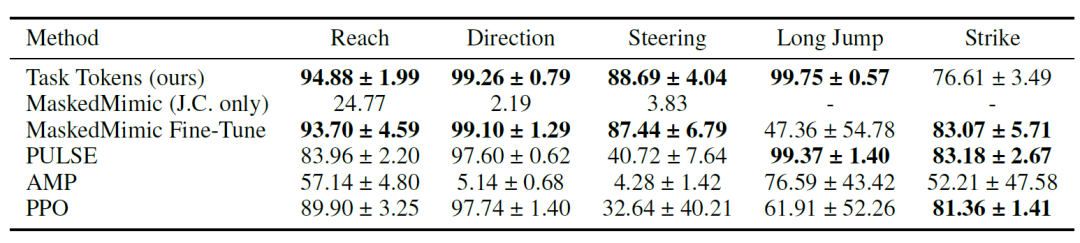
Researchers first demonstrated that Task Tokens can effectively adapt MaskedMimic to downstream tasks; numerical results are shown in the table below. The results indicate that...Task Tokens achieved high scores in most environments, with PULSE, MaskedMimic Fine-Tune, and PureRL scoring higher on the Strike task.
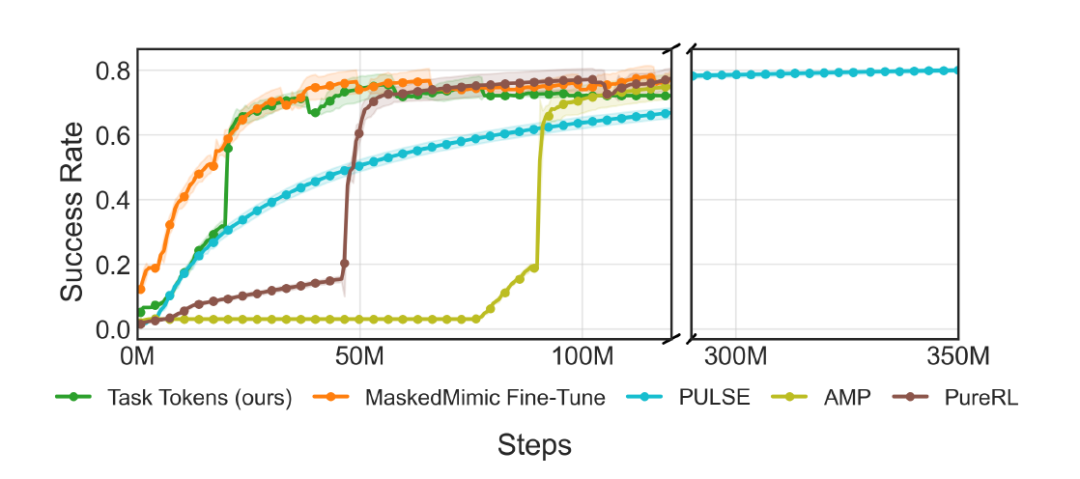
Furthermore, the figure below shows the success rate curve during training. It can be observed that Task Tokens converges in approximately 50 million (50M) steps, while PULSE requires approximately 300 million (300M) steps to achieve the same performance.
In achieving the above results,Task Tokens only require training a single encoder with approximately 200,000 (~200K) parameters.PULSE and MaskedMimic Fine-Tune require 9.3 million (9.3M) and 25 million (25M) parameters respectively, which is about 46.5 times and 125 times higher. This efficiency is particularly critical in real-world applications because training large-scale models is extremely costly.
These results demonstrate that Task Tokens can efficiently and effectively adapt behavioral foundational models such as MaskedMimic to new and unseen tasks.
Out-of-distribution (OOD) generalization ability
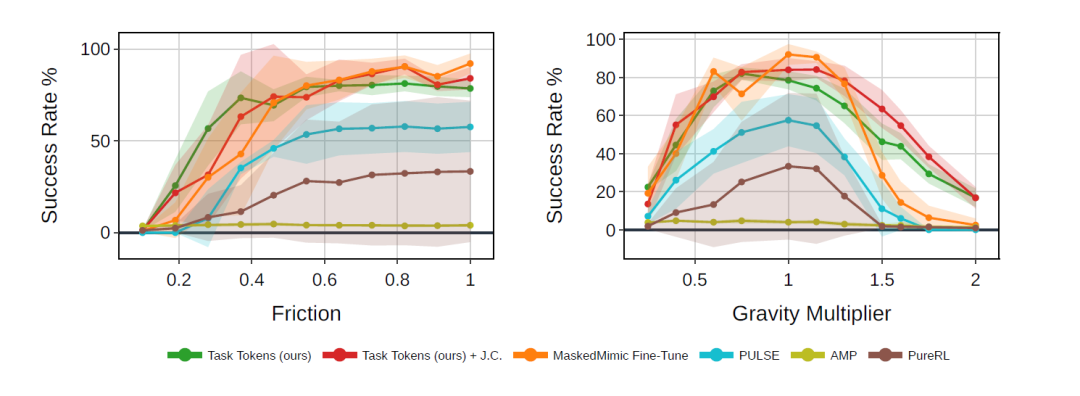
Researchers conducted comparative experiments under out-of-distribution (OOD) perturbation conditions, which did not occur during the training of the original BFM and Task Tokens, and mainly considered two types of changes: gravity and ground friction.
The results in the figure below show that, with the help of BFM,Task Tokens demonstrate significantly enhanced robustness in new, unseen scenarios.First, under baseline conditions (no perturbation), Task Tokens performs almost identically to a fully fine-tuned MaskedMimic and outperforms all other baseline methods. Subsequently, its performance significantly surpasses baseline methods as perturbation strength increases. Notably, Task Tokens maintains a significantly higher success rate even under extremely low friction (e.g., ×0.4) and high gravity (e.g., ×1.5) conditions.
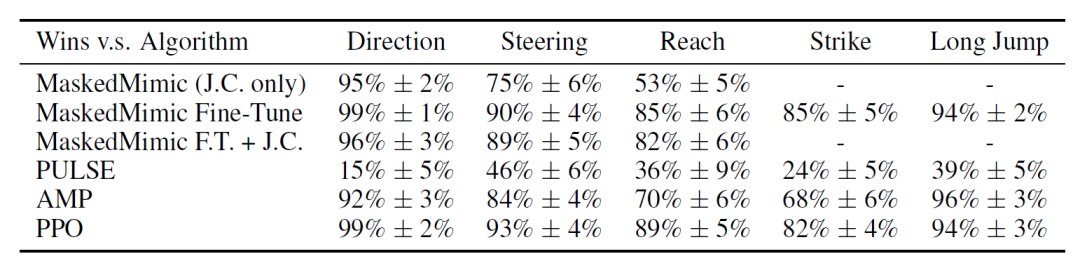
Human Study
The table below shows the percentage of Task Tokens selected as the more "human" action compared to each comparison method. The results indicate that...Task Tokens are significantly superior to MaskedMimic (JC only) and MaskedMimic Fine-Tune.This indicates that the conditions designed by the user have certain out-of-distribution characteristics for the basic MaskedMimic model, and that Task Tokens are a more effective way to adapt to action quality compared to fine-tuning.
Furthermore, it can be observed that although Task Tokens are superior in terms of convergence speed, parameter size, and task performance, PULSE scores higher in terms of "action human similarity".
Based on the above results, it can be concluded that Task Tokens achieve a good balance between efficiency, action quality, and robustness.
Multi-Modal Prompting Effect
Finally, the researchers explored the synergistic effects of Task Tokens with other prompting methods, demonstrating their good compatibility and flexibility.
In the Direction task, the reward function only encourages the agent to move in the correct direction, without considering the human-like body orientation. Therefore, the policy may converge to "walking backwards." While this behavior yields higher rewards and a higher success rate, it is clearly not what is expected.
The image below illustrates the introduction of artificially designed priors (such as constraints on the height and orientation of the head target).The training process can converge to a "walking upright" movement pattern.

In the Strike task, the agent needs to hit the target—a common emergent behavior is for the agent to back up to the target and then perform a "whirlwind" motion, hitting the target by spinning in place. The figure below illustrates the combination of the two prior modalities.
First, by using orientation conditions similar to those in a Direction task, the agent is made to always face the target during movement. Then, when it gets close to the target, the text target "a person performs a kicking action" is introduced to guide the agent to use its foot to complete the kicking action.

Notably, researchers observed that fine-tuning the entire model leads to the well-known catastrophic forgetting problem, thereby weakening the model's ability to retain and fuse multimodal cues. In contrast, Task Tokens, by freezing the base model, retains its pre-trained cueing capabilities, allowing learned behaviors to fuse more consistently with human-specified behaviors.
Conclusion
Current experiments are primarily based on the MaskedMimic architecture; future work requires validating the method's generalizability within a broader GC-BFM architecture. While task-related reward and observation design still rely on expert experience, future research could explore (semi-)automated design to lower the barrier to entry. A key direction is migrating Task Tokens-adapted strategies to real-world robotic systems, addressing the simulation-to-reality problem, and extending to complex real-world tasks requiring high-level decision-making, beyond just animation simulations.
Finally, exploring more complex task encoder architectures (beyond the current feedforward network architecture) could also lead to further performance improvements. Solving these problems will further refine the Task Tokens framework and drive the development of more diverse, adaptable, and capable humanoid intelligent agents.
References:
https://openreview.net/forum?id=6T3wJQhvc3
https://arxiv.org/pdf/2503.22886








