HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Autoreason: Self-Refinement That Knows When to Stop

ActiveGlasses: Learning Manipulation with Active Vision from Ego-centric Human Demonstration

























Autoreason: Self-Refinement That Knows When to Stop
ActiveGlasses: Learning Manipulation with Active Vision from Ego-centric Human Demonstration
MegaStyle: Constructing Diverse and Scalable Style Dataset via Consistent Text-to-Image Style Mapping
When Numbers Speak: Aligning Textual Numerals and Visual Instances in Text-to-Video Diffusion Models
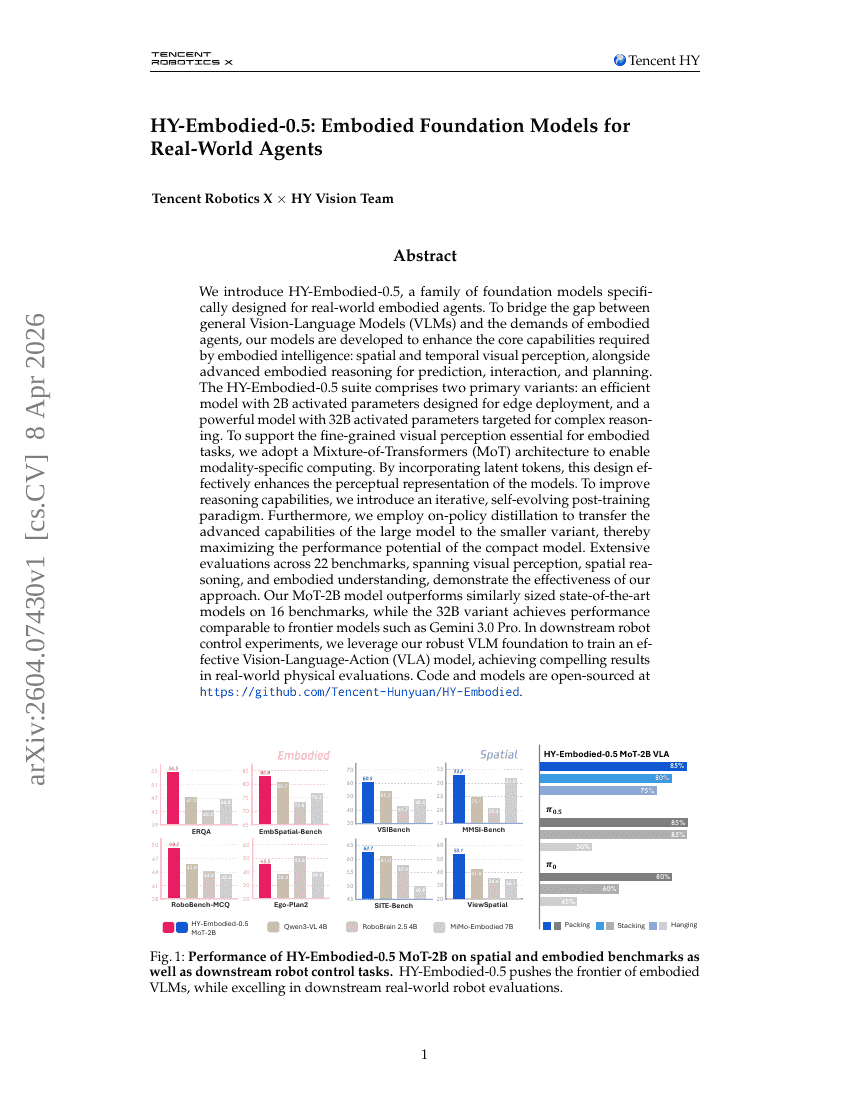
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
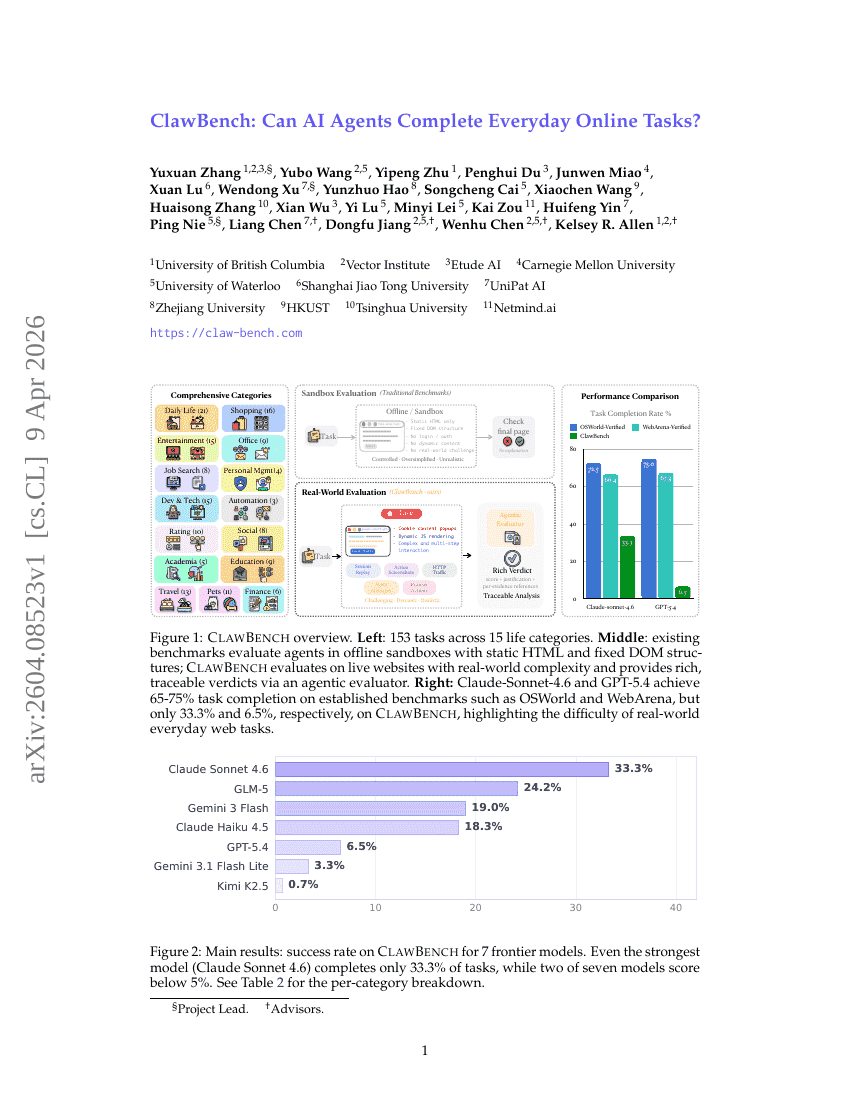
ClawBench: Can AI Agents Complete Everyday Online Tasks?
Rethinking Generalization in Reasoning SFT: A Conditional Analysis on Optimization, Data, and Model Capability
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
MDPBench: A Benchmark for Multilingual Document Parsing in Real-World Scenarios
TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
FlowInOne:Unifying Multimodal Generation as Image-in, Image-out Flow Matching
MARS: Enabling Autoregressive Models Multi-Token Generation
Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning
RAGEN-2: Reasoning Collapse in Agentic RL
Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision
ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
ACES: Who Tests the Tests? Leave-One-Out AUC Consistency for Code Generation
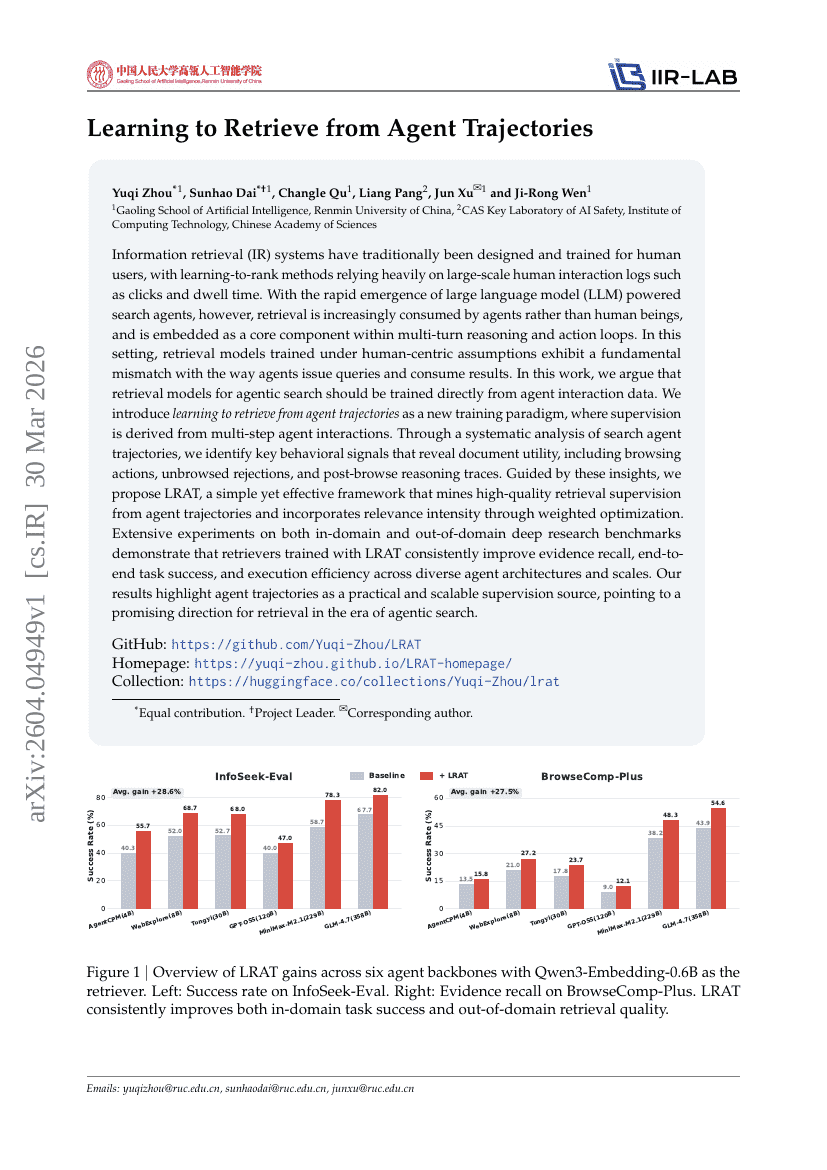
Learning to Retrieve from Agent Trajectories
Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
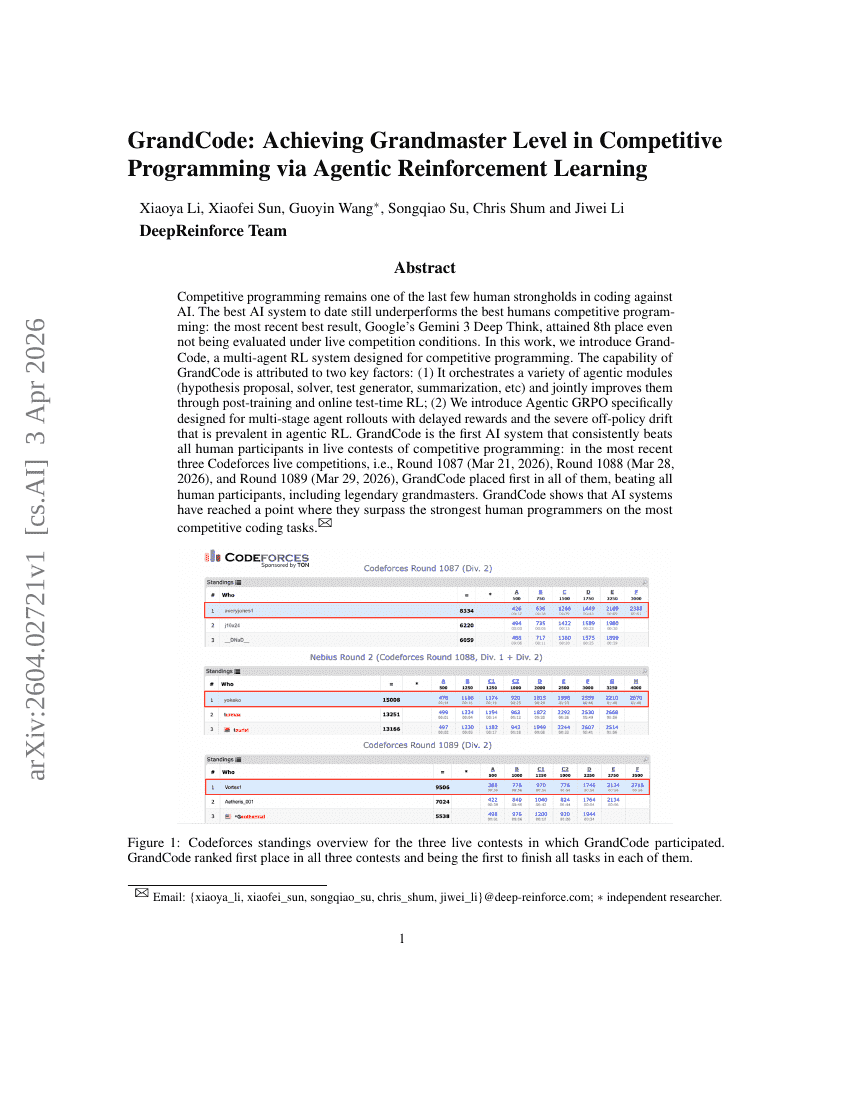
GrandCode: Achieving Grandmaster Level in Competitive Programming via Agentic Reinforcement Learning
LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Adam's Law: Textual Frequency Law on Large Language Models
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
WAXAL: A Large-Scale Multilingual African Language Speech Corpus
DRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
InCoder-32B-Thinking: Industrial Code World Model for Thinking
MegaStyle: Constructing Diverse and Scalable Style Dataset via Consistent Text-to-Image Style Mapping
When Numbers Speak: Aligning Textual Numerals and Visual Instances in Text-to-Video Diffusion Models
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
ClawBench: Can AI Agents Complete Everyday Online Tasks?
Rethinking Generalization in Reasoning SFT: A Conditional Analysis on Optimization, Data, and Model Capability
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
MDPBench: A Benchmark for Multilingual Document Parsing in Real-World Scenarios
TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
FlowInOne:Unifying Multimodal Generation as Image-in, Image-out Flow Matching
MARS: Enabling Autoregressive Models Multi-Token Generation
Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning
RAGEN-2: Reasoning Collapse in Agentic RL
Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision
ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
ACES: Who Tests the Tests? Leave-One-Out AUC Consistency for Code Generation
Learning to Retrieve from Agent Trajectories
Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
GrandCode: Achieving Grandmaster Level in Competitive Programming via Agentic Reinforcement Learning
LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Adam's Law: Textual Frequency Law on Large Language Models
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
WAXAL: A Large-Scale Multilingual African Language Speech Corpus
DRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
InCoder-32B-Thinking: Industrial Code World Model for Thinking