HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks

StyleID: A Perception-Aware Dataset and Metric for Stylization-Agnostic Facial Identity Recognition


























Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
StyleID: A Perception-Aware Dataset and Metric for Stylization-Agnostic Facial Identity Recognition
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
Image Generators are Generalist Vision Learners
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
Bootstrapping Exploration with Group-Level Natural Language Feedback in Reinforcement Learning
SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
Exploring Spatial Intelligence from a Generative Perspective
DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
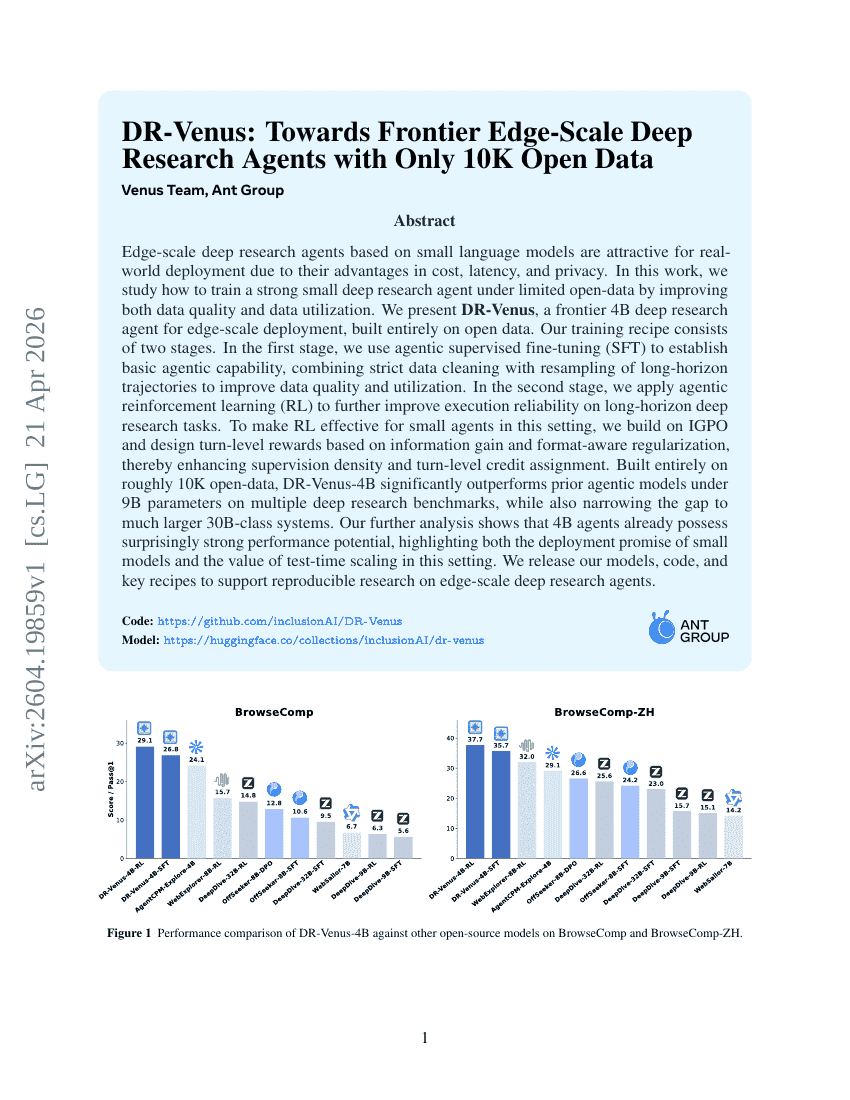
DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
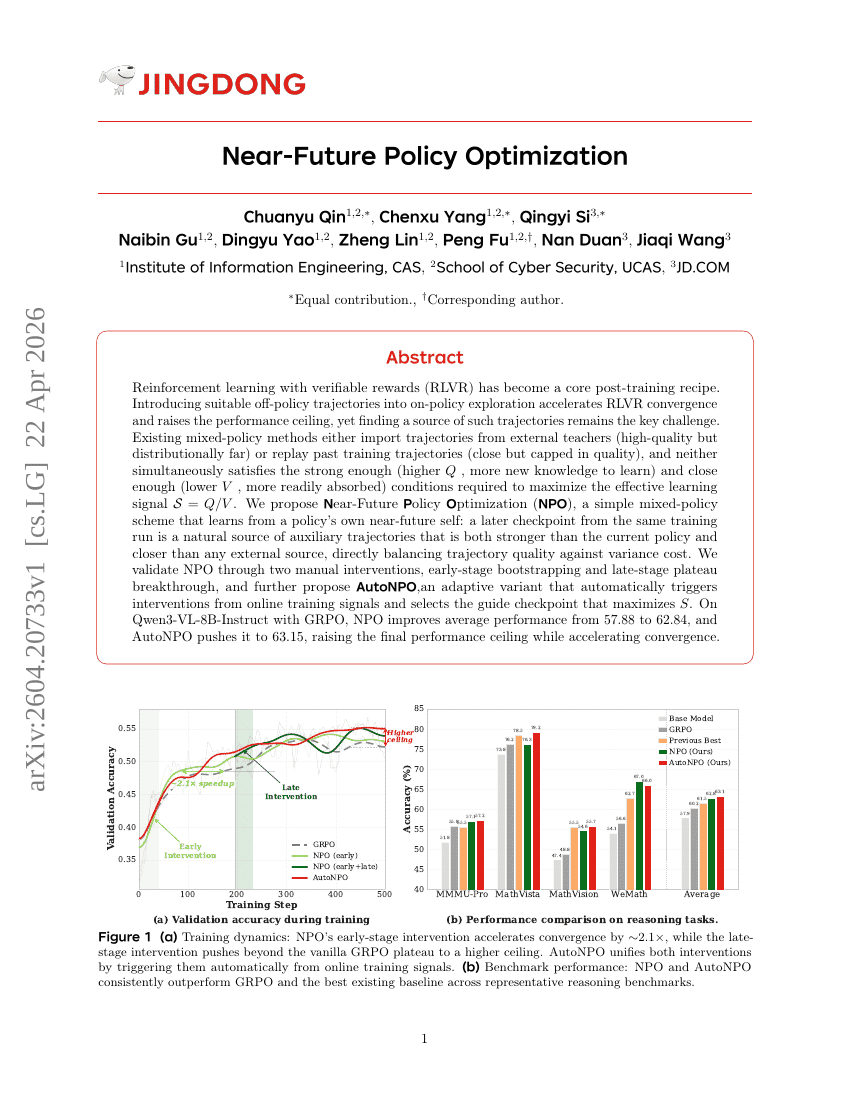
Near-Future Policy Optimization
LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
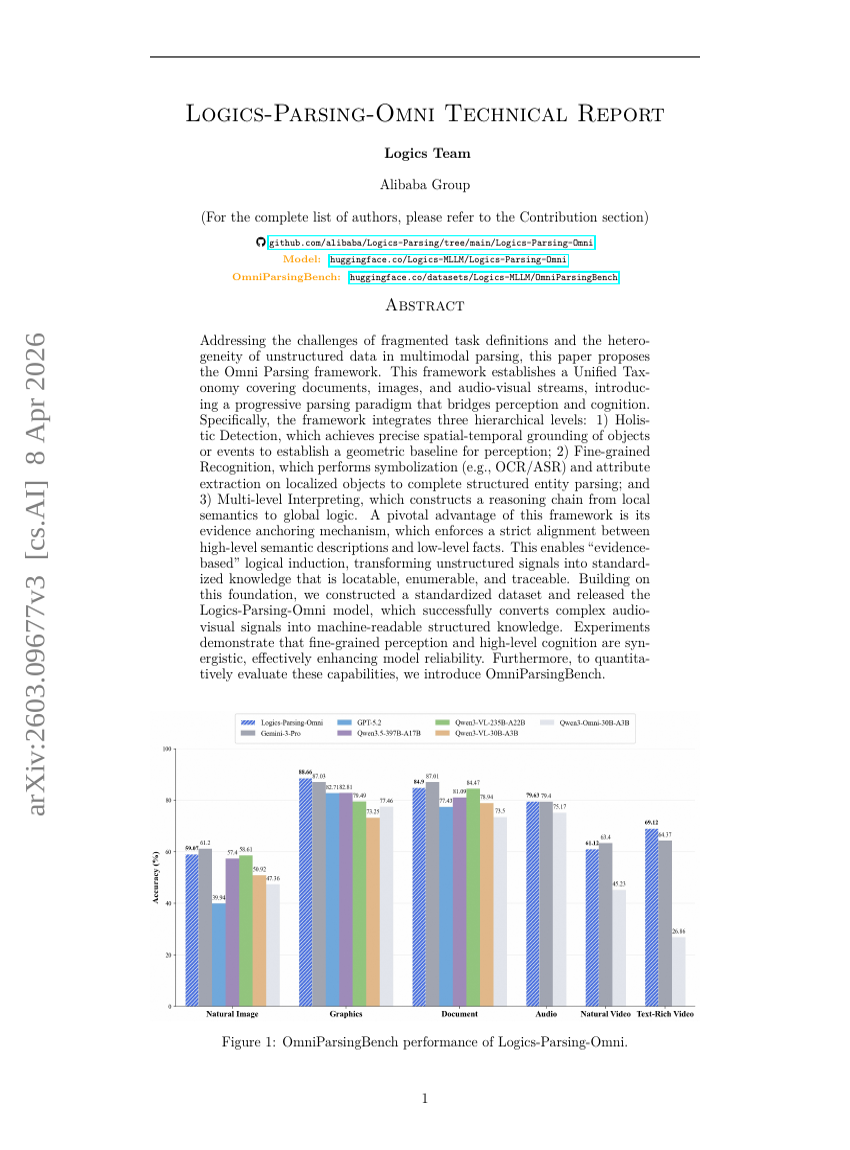
Logics-Parsing-Omni Technical Report
Task Tokens: A Flexible Approach to Adapting Behavior Foundation Models
面向盲人与低视力用户的可解释人工智能:Agent 时代的信任、模态与可解释性探索
PlayCoder: Making LLM-Generated GUI Code Playable
TEMPO: Scaling Test-time Training for Large Reasoning Models
AnyRecon: Arbitrary-View 3D Reconstruction with Video Diffusion Model
AgentSPEX: An Agent SPecification and EXecution Language
CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
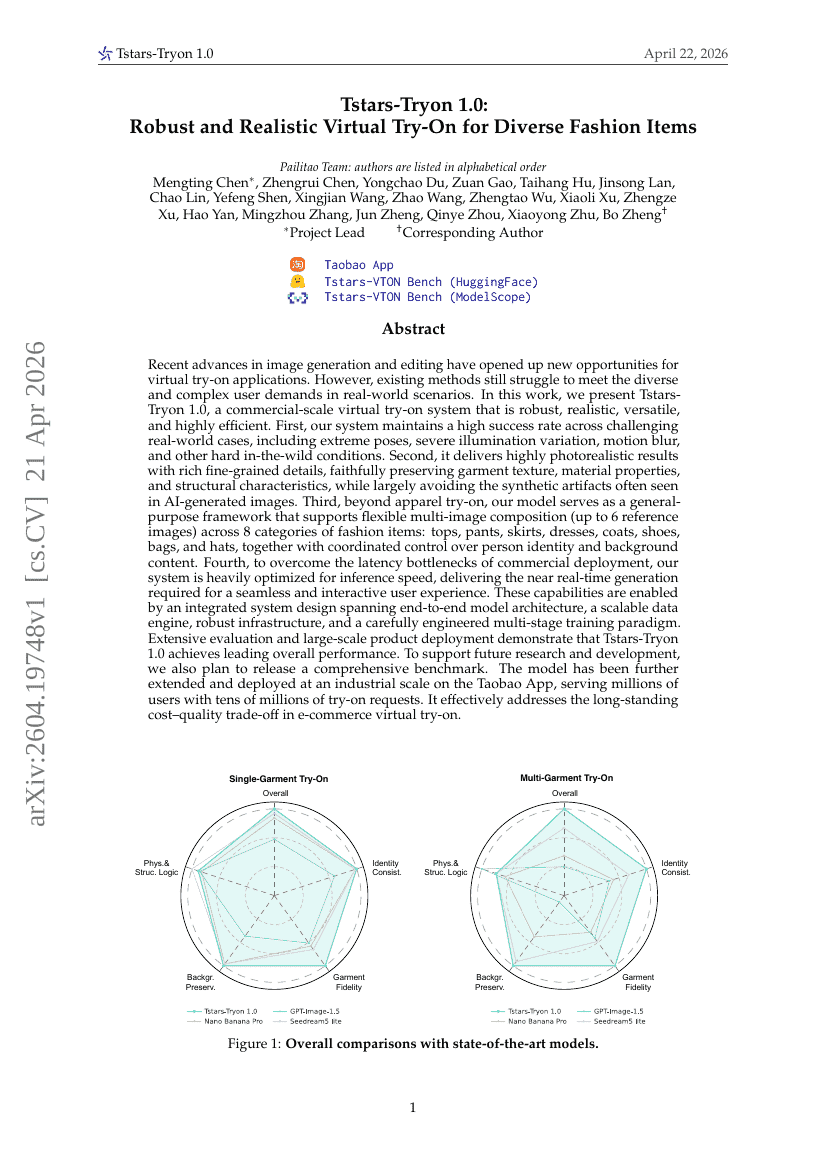
Tstars-Tryon 1.0: Robust and Realistic Virtual Try-On for Diverse Fashion Items
Fast NF4 Dequantization Kernels for Large Language Model Inference
EasyVideoR1: Easier RL for Video Understanding
MultiWorld: Scalable Multi-Agent Multi-View Video World Models
OpenGame: Open Agentic Coding for Games
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
Image Generators are Generalist Vision Learners
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
Bootstrapping Exploration with Group-Level Natural Language Feedback in Reinforcement Learning
SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
Exploring Spatial Intelligence from a Generative Perspective
DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
Near-Future Policy Optimization
LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Logics-Parsing-Omni Technical Report
Task Tokens: A Flexible Approach to Adapting Behavior Foundation Models
面向盲人与低视力用户的可解释人工智能:Agent 时代的信任、模态与可解释性探索
PlayCoder: Making LLM-Generated GUI Code Playable
TEMPO: Scaling Test-time Training for Large Reasoning Models
AnyRecon: Arbitrary-View 3D Reconstruction with Video Diffusion Model
AgentSPEX: An Agent SPecification and EXecution Language
CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
Tstars-Tryon 1.0: Robust and Realistic Virtual Try-On for Diverse Fashion Items
Fast NF4 Dequantization Kernels for Large Language Model Inference
EasyVideoR1: Easier RL for Video Understanding
MultiWorld: Scalable Multi-Agent Multi-View Video World Models
OpenGame: Open Agentic Coding for Games
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence