HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG

MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding




























WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning
VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding
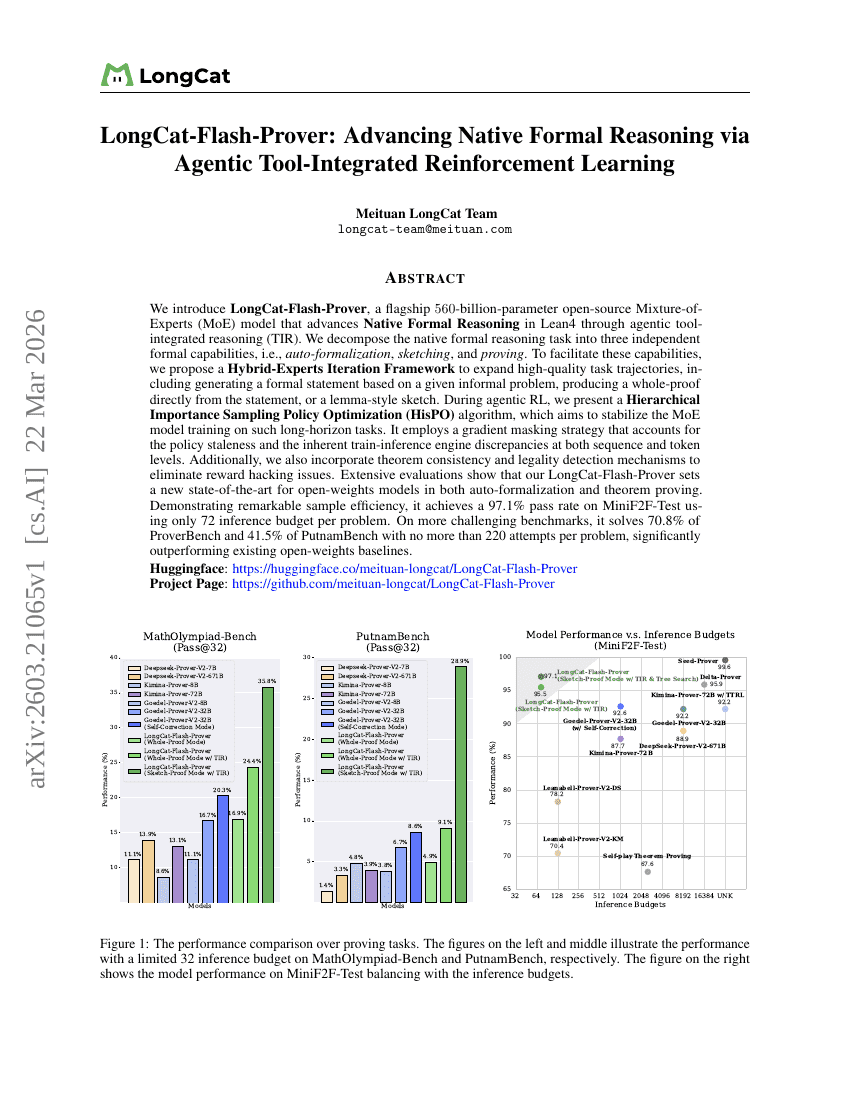
LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
PrismAudio: Decomposed Chain-of-Thoughts and Multi-dimensional Rewards for Video-to-Audio Generation
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
The Y-Combinator for LLMs: Solving Long-Context Rot with λ-Calculus
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
FASTER: Rethinking Real-Time Flow VLAs
3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
Efficient Reasoning with Balanced Thinking
Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
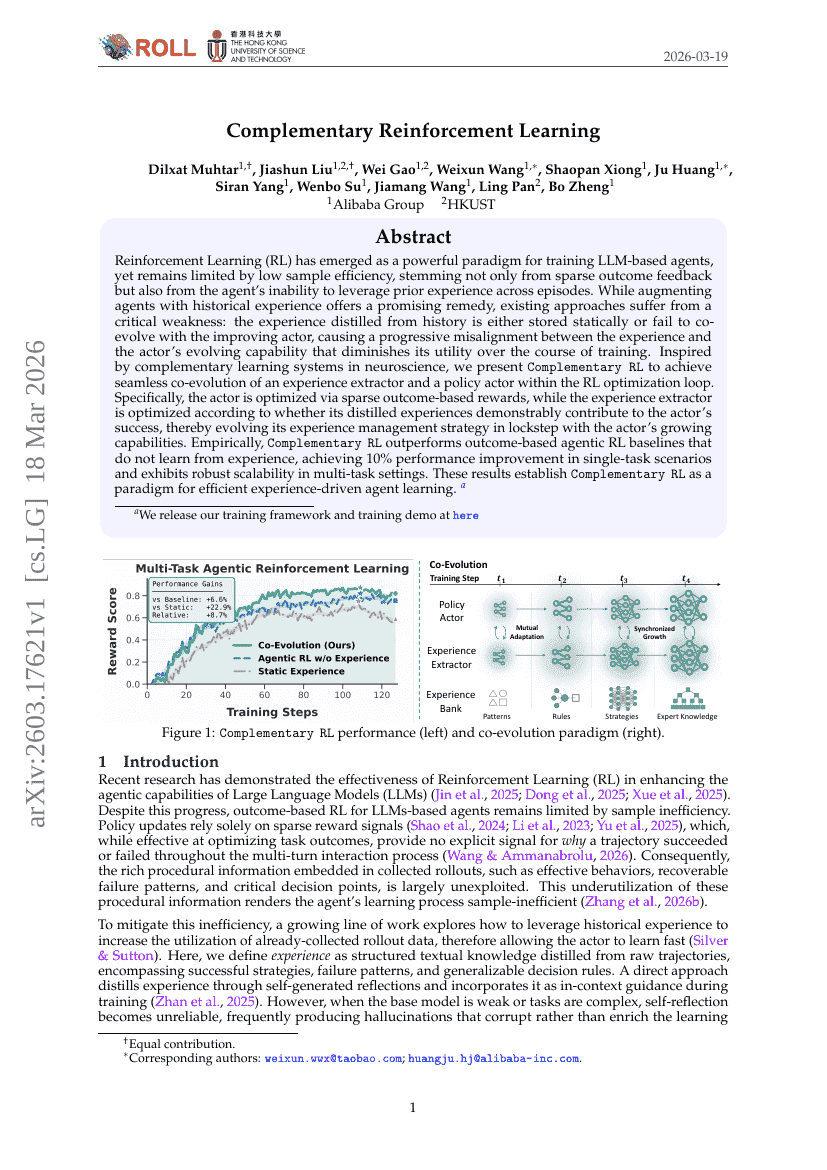
Complementary Reinforcement Learning
Alignment Makes Language Models Normative, Not Descriptive
MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
Video-CoE: Reinforcing Video Event Prediction via Chain of Events
FunCineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
In-Context Watermarks for Large Language Models
PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning
VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding
LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
PrismAudio: Decomposed Chain-of-Thoughts and Multi-dimensional Rewards for Video-to-Audio Generation
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
The Y-Combinator for LLMs: Solving Long-Context Rot with λ-Calculus
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
FASTER: Rethinking Real-Time Flow VLAs
3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
Efficient Reasoning with Balanced Thinking
Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
Complementary Reinforcement Learning
Alignment Makes Language Models Normative, Not Descriptive
MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
Video-CoE: Reinforcing Video Event Prediction via Chain of Events
FunCineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
In-Context Watermarks for Large Language Models