HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation

Demystifing Video Reasoning


























WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Demystifing Video Reasoning
Kinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
InCoder-32B: Code Foundation Model for Industrial Scenarios
MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
HSImul3R: Physics-in-the-Loop Reconstruction of Simulation-Ready Human-Scene Interactions
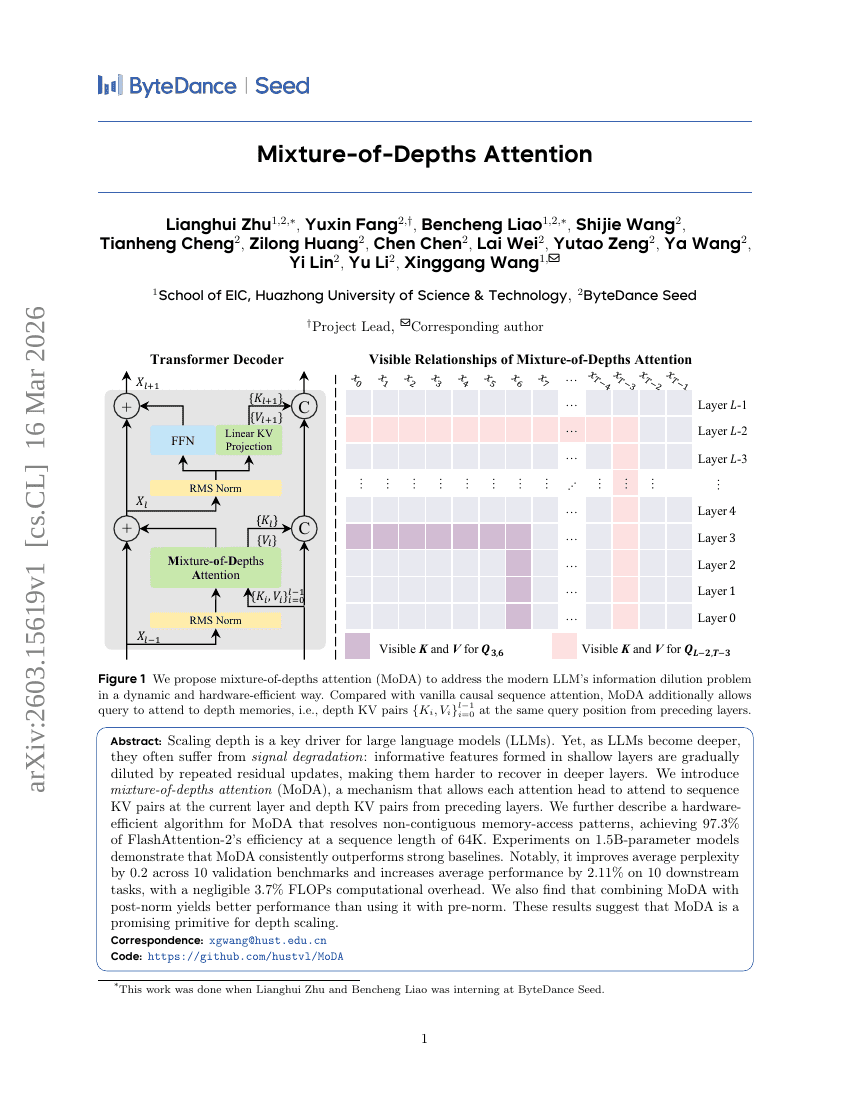
Mixture-of-Depths Attention
Attention Residuals
Grounding World Simulation Models in a Real-World Metropolis
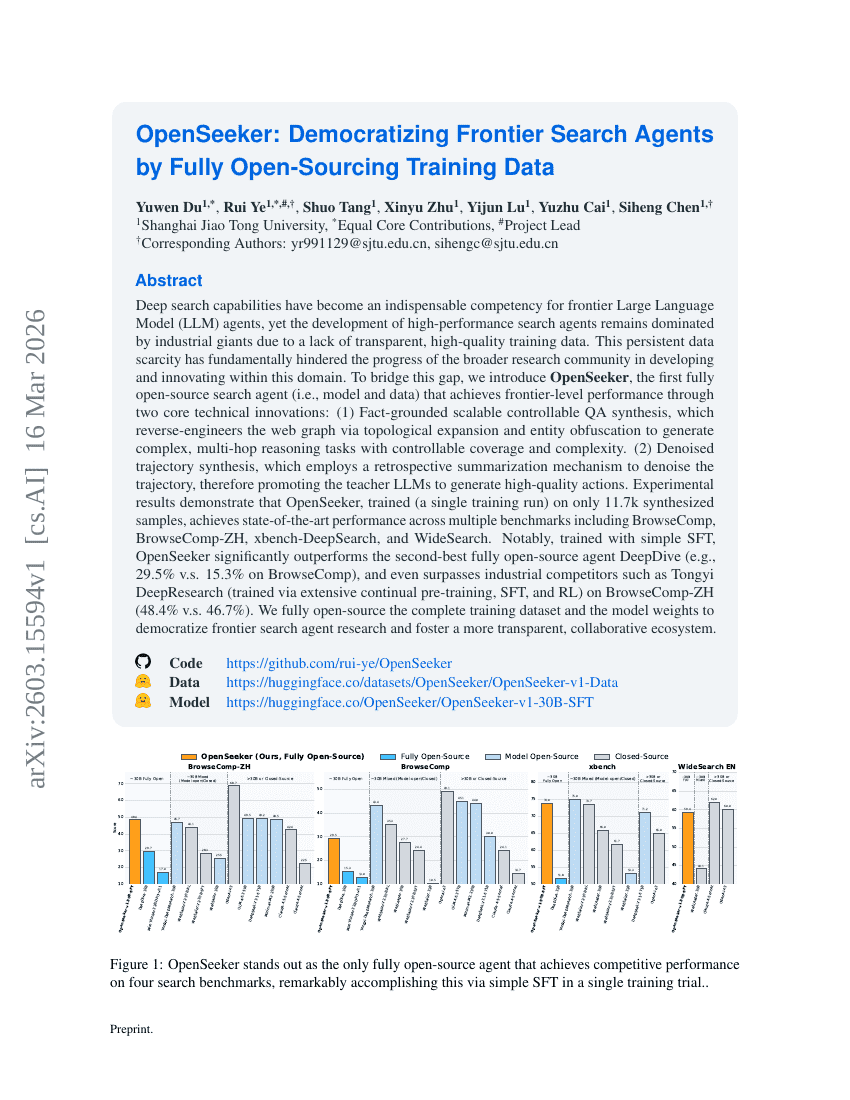
OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data
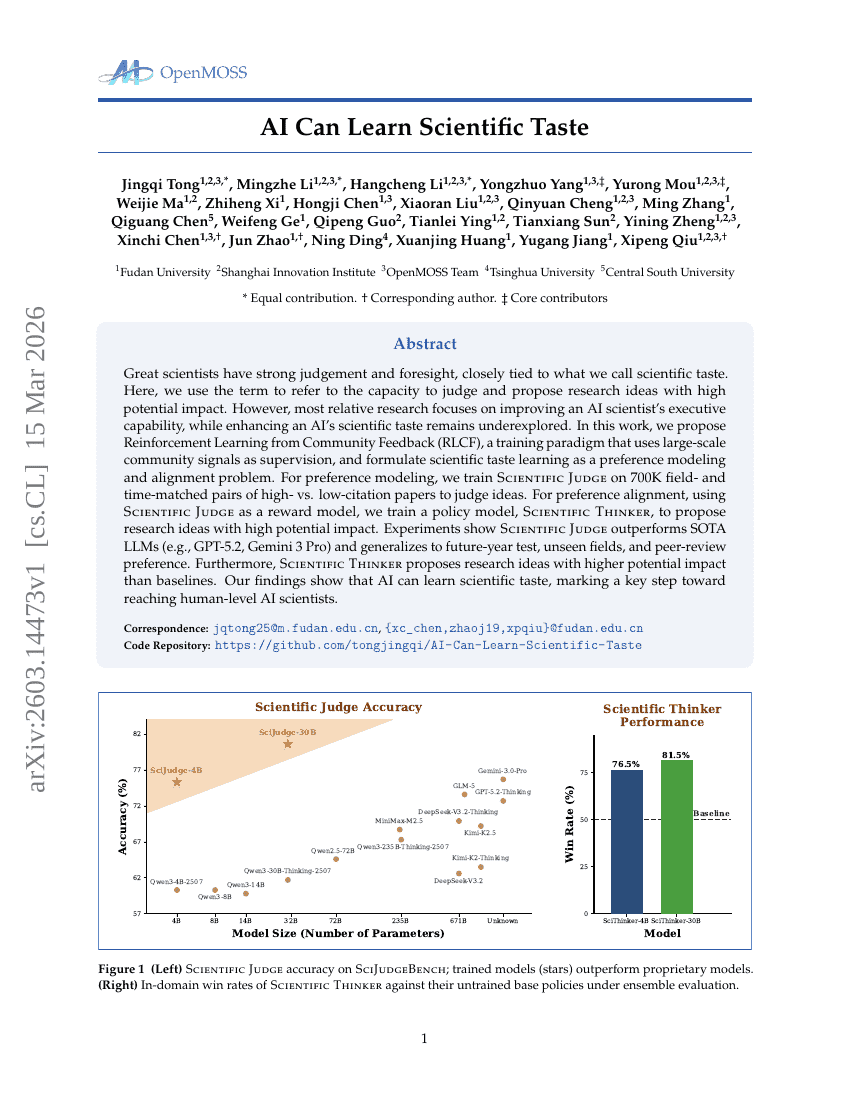
AI Can Learn Scientific Taste
MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
Can Vision-Language Models Solve the Shell Game?
OmniForcing: Unleashing Real-time Joint Audio-Visual Generation
daVinci-Env: Open SWE Environment Synthesis at Scale
Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
LMEB: Long-horizon Memory Embedding Benchmark
DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
Video-Based Reward Modeling for Computer-Use Agents
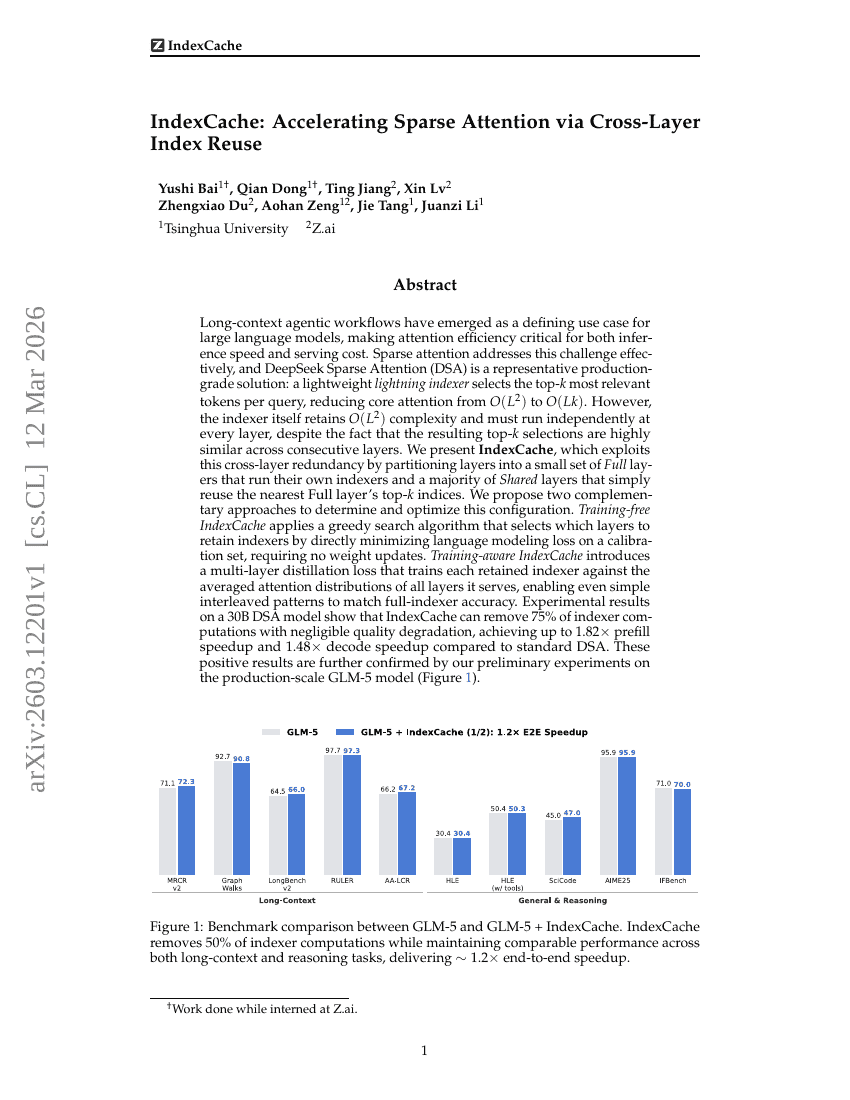
IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
Can Large Language Models Keep Up? Benchmarking Online Adaptation to Continual Knowledge Streams
ReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
In-Context Reinforcement Learning for Tool Use in Large Language Models
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Flash-KMeans: Fast and Memory-Efficient Exact K-Means
OpenClaw-RL: Train Any Agent Simply by Talking
Stepping VLMs onto the Court: Benchmarking Spatial Intelligence in Sports
InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
Kinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
InCoder-32B: Code Foundation Model for Industrial Scenarios
MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
HSImul3R: Physics-in-the-Loop Reconstruction of Simulation-Ready Human-Scene Interactions
Mixture-of-Depths Attention
Attention Residuals
Grounding World Simulation Models in a Real-World Metropolis
OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data
AI Can Learn Scientific Taste
MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
Can Vision-Language Models Solve the Shell Game?
OmniForcing: Unleashing Real-time Joint Audio-Visual Generation
daVinci-Env: Open SWE Environment Synthesis at Scale
Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
LMEB: Long-horizon Memory Embedding Benchmark
DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
Video-Based Reward Modeling for Computer-Use Agents
IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
Can Large Language Models Keep Up? Benchmarking Online Adaptation to Continual Knowledge Streams
ReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
In-Context Reinforcement Learning for Tool Use in Large Language Models
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Flash-KMeans: Fast and Memory-Efficient Exact K-Means
OpenClaw-RL: Train Any Agent Simply by Talking
Stepping VLMs onto the Court: Benchmarking Spatial Intelligence in Sports
InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing