HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends
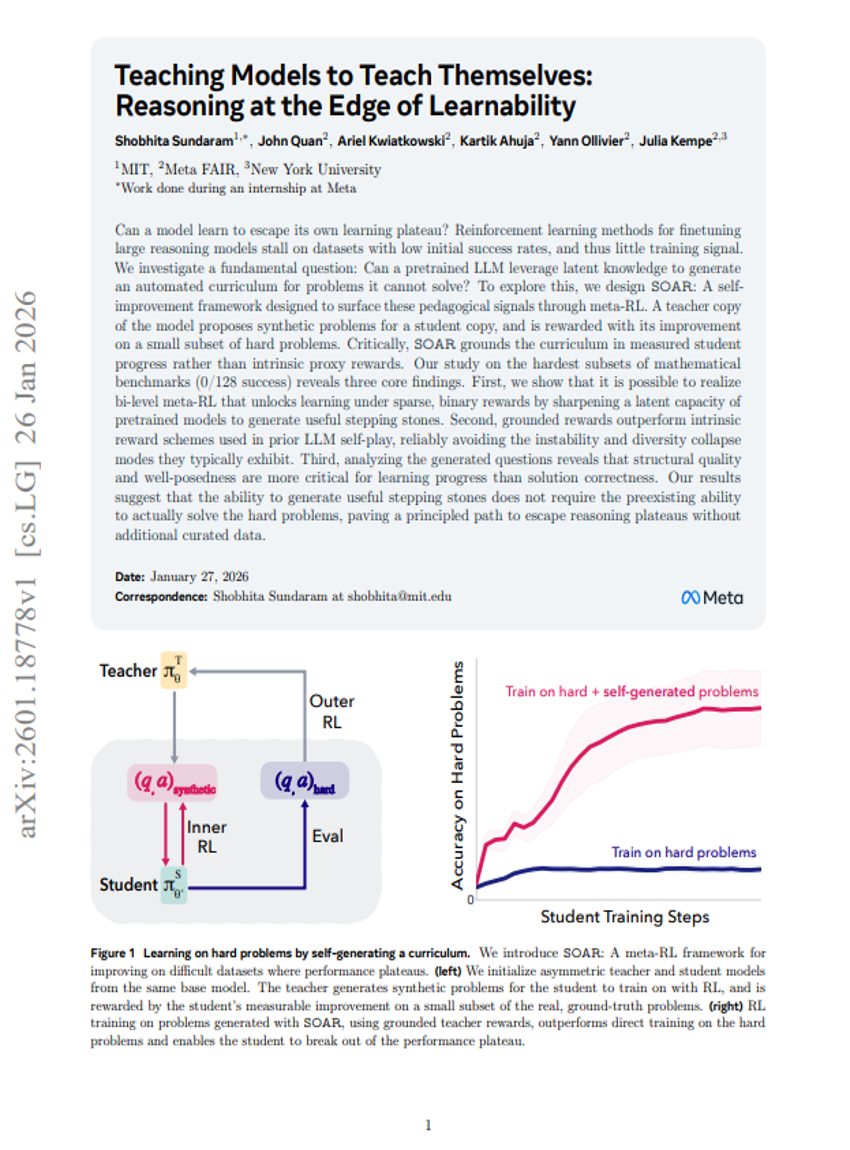
Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability

ATLAS: Adaptive Transfer Scaling Laws for Multilingual Pretraining, Finetuning, and Decoding the Curse of Multilinguality




















Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
ATLAS: Adaptive Transfer Scaling Laws for Multilingual Pretraining, Finetuning, and Decoding the Curse of Multilinguality
iFSQ: Improving FSQ for Image Generation with 1 Line of Code
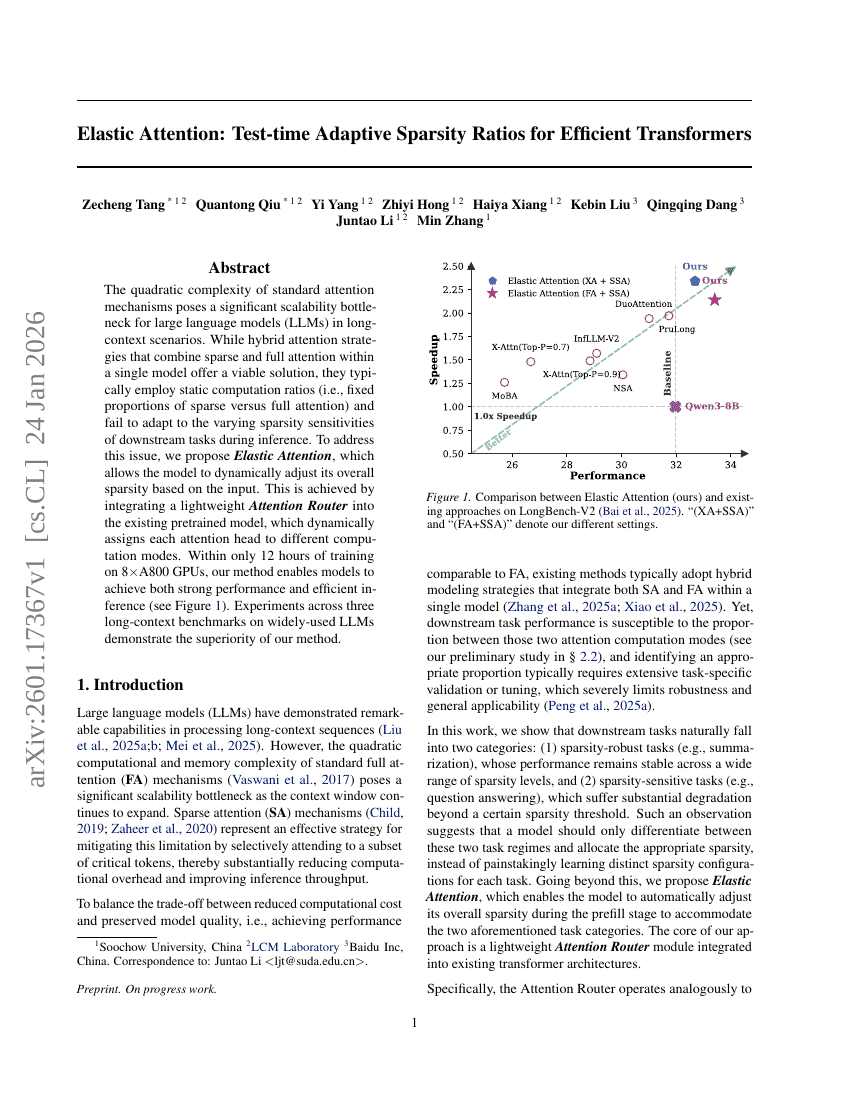
Elastic Attention: Test-time Adaptive Sparsity Ratios for Efficient Transformers
Scientific Image Synthesis: Benchmarking, Methodologies, and Downstream Utility
The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation
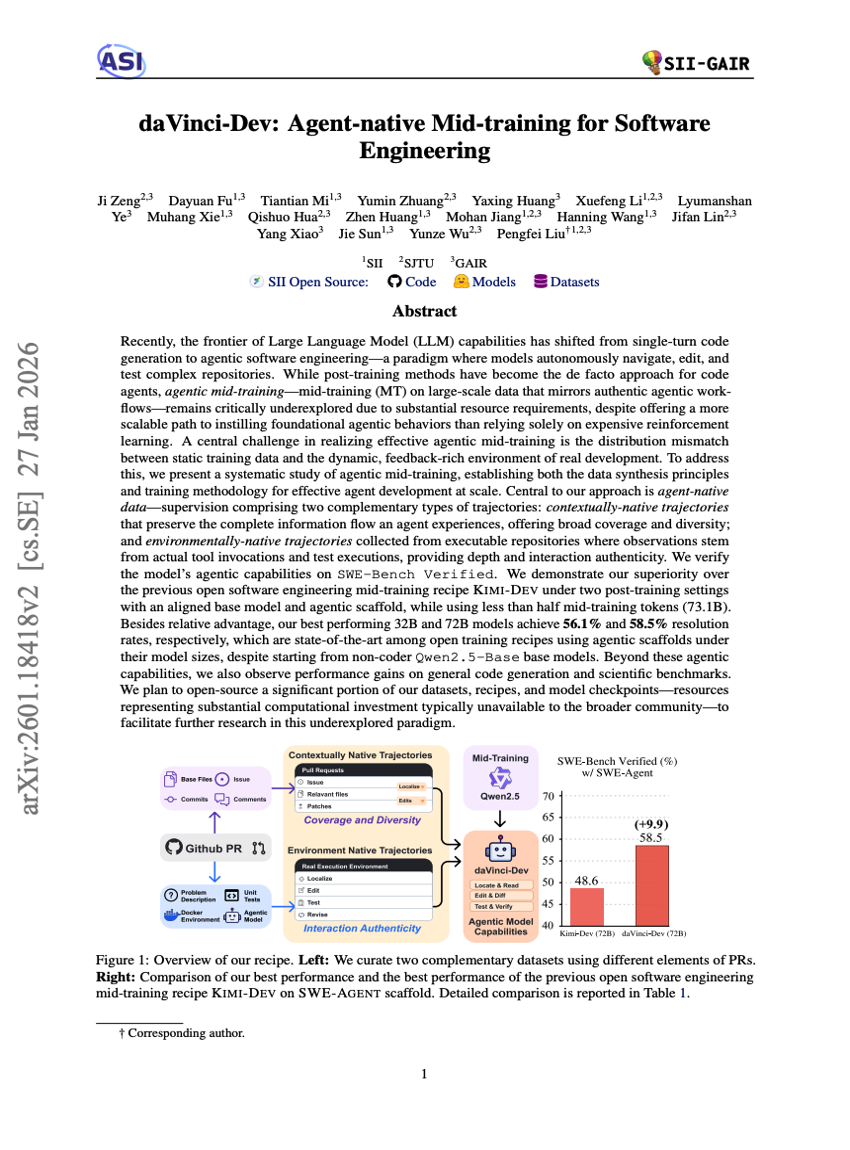
daVinci-Dev: Agent-native Mid-training for Software Engineering
Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs
DeepSeek-OCR 2: Visual Causal Flow
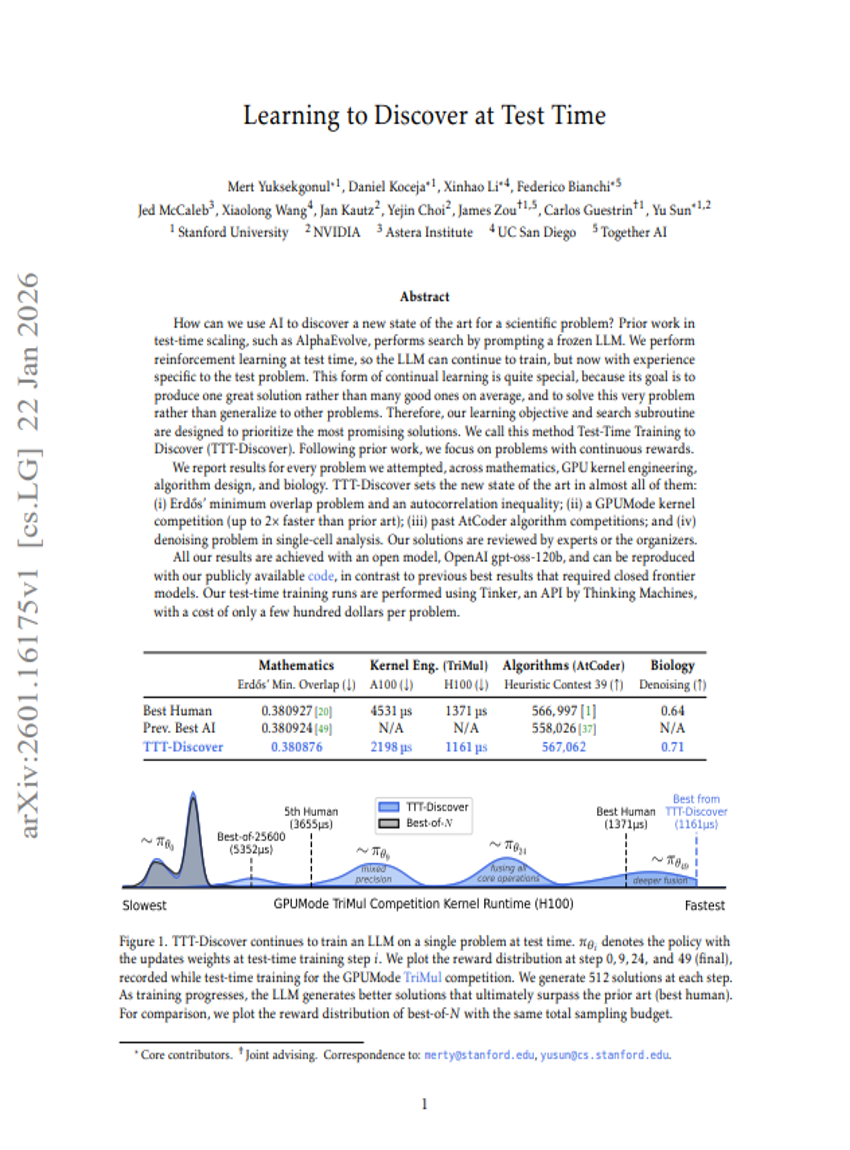
Learning to Discover at Test Time
Eliciting Harmful Capabilities by Fine-Tuning On Safeguarded Outputs
Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
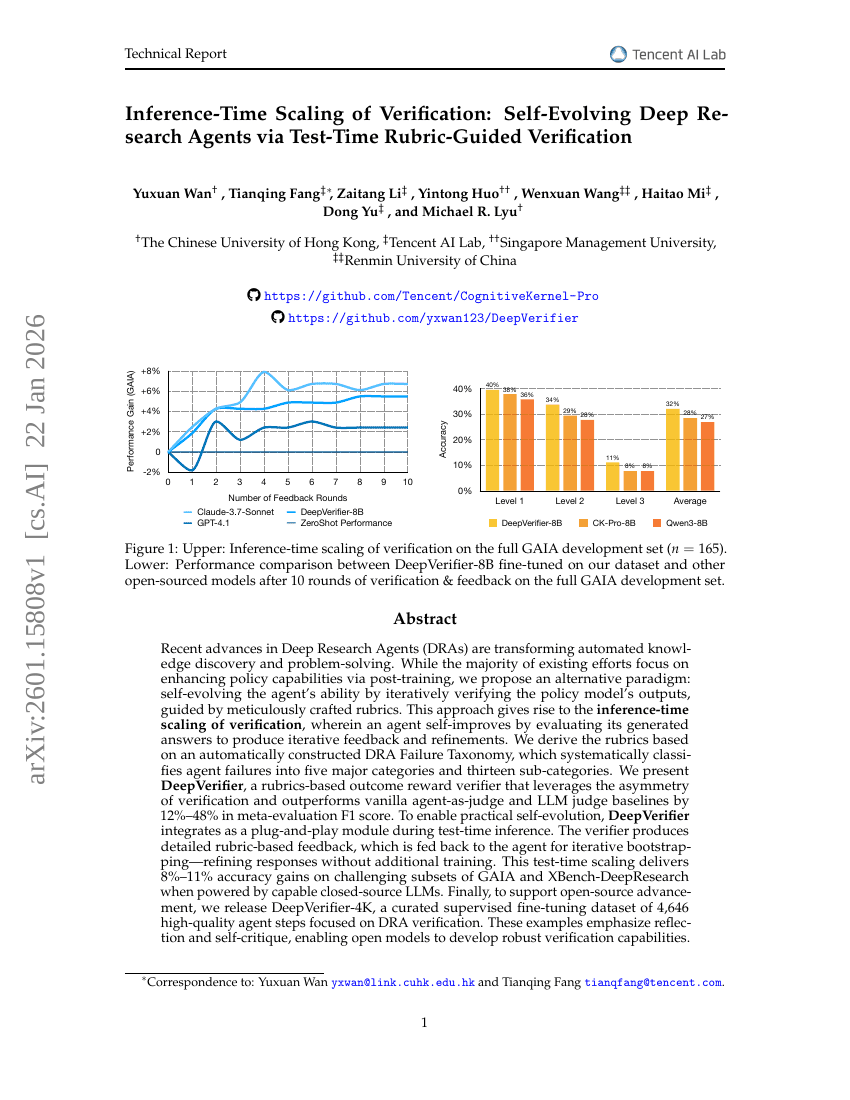
Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
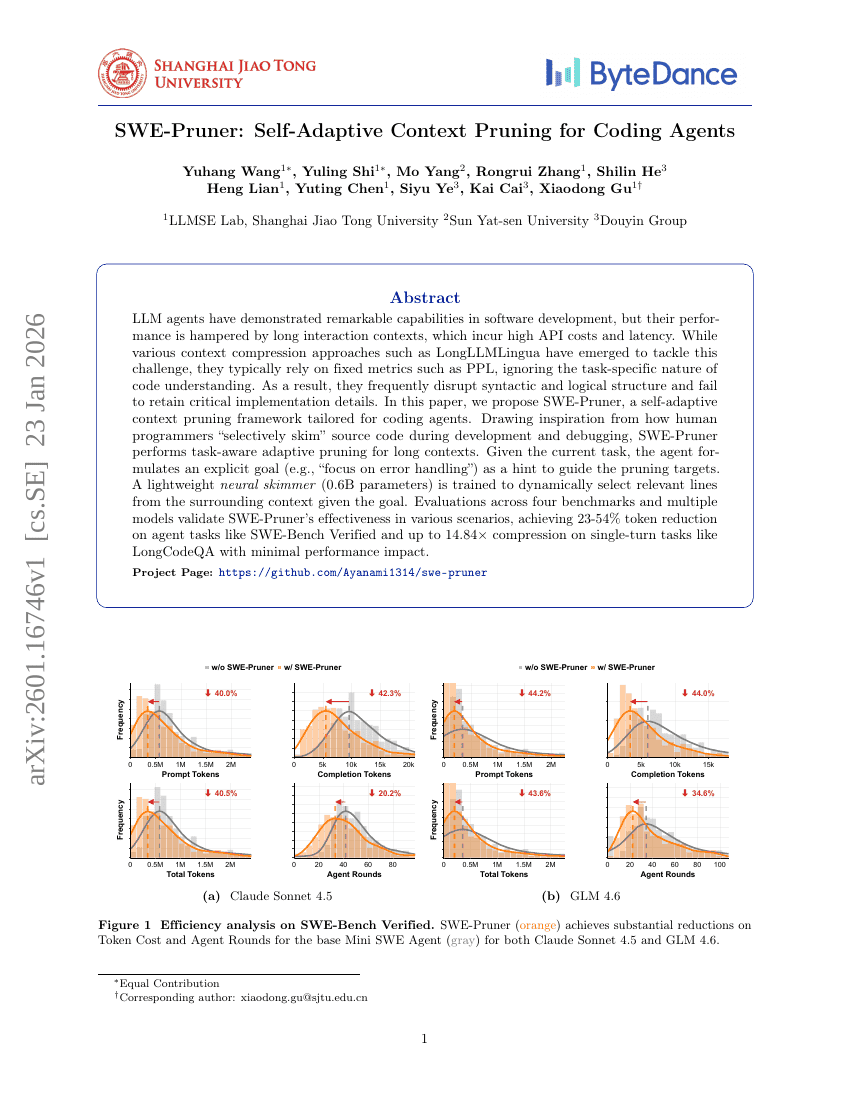
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
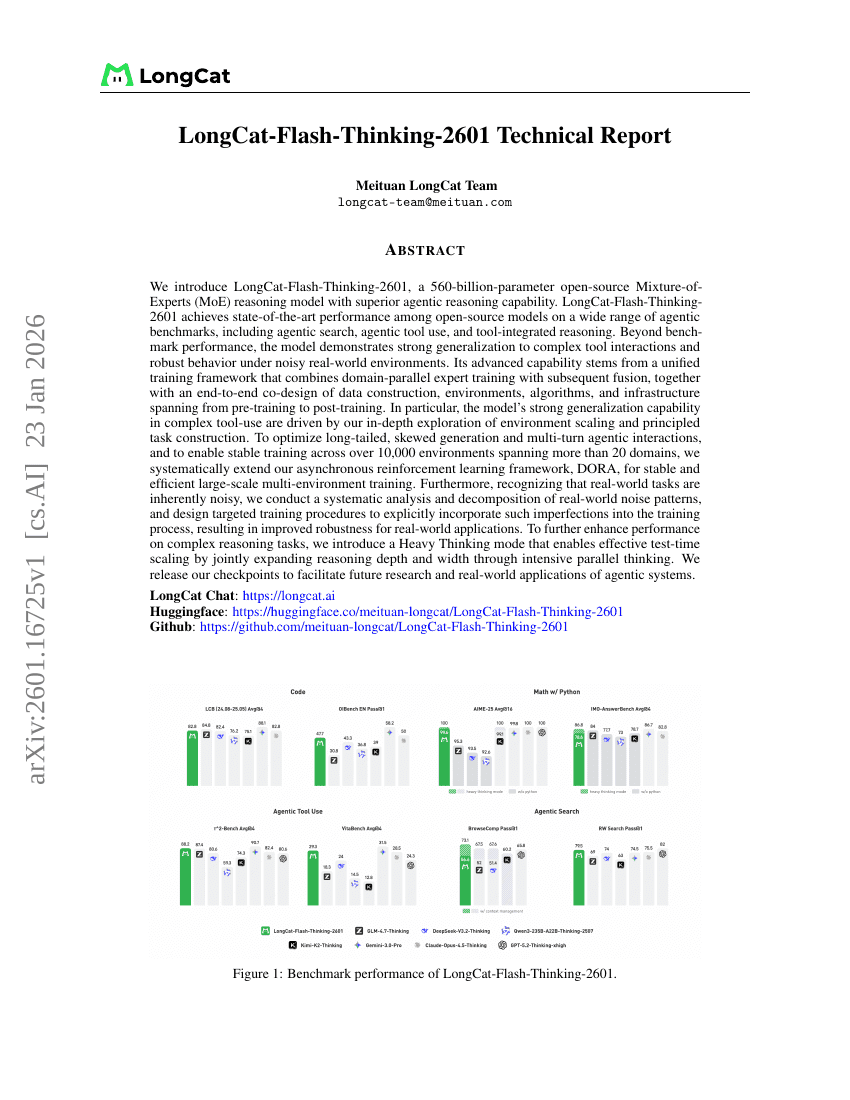
LongCat-Flash-Thinking-2601 Technical Report
Can Language Models Discover Scaling Laws?
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Triton-distributed: Programming Overlapping Kernels on Distributed AI Systems with the Triton Compiler
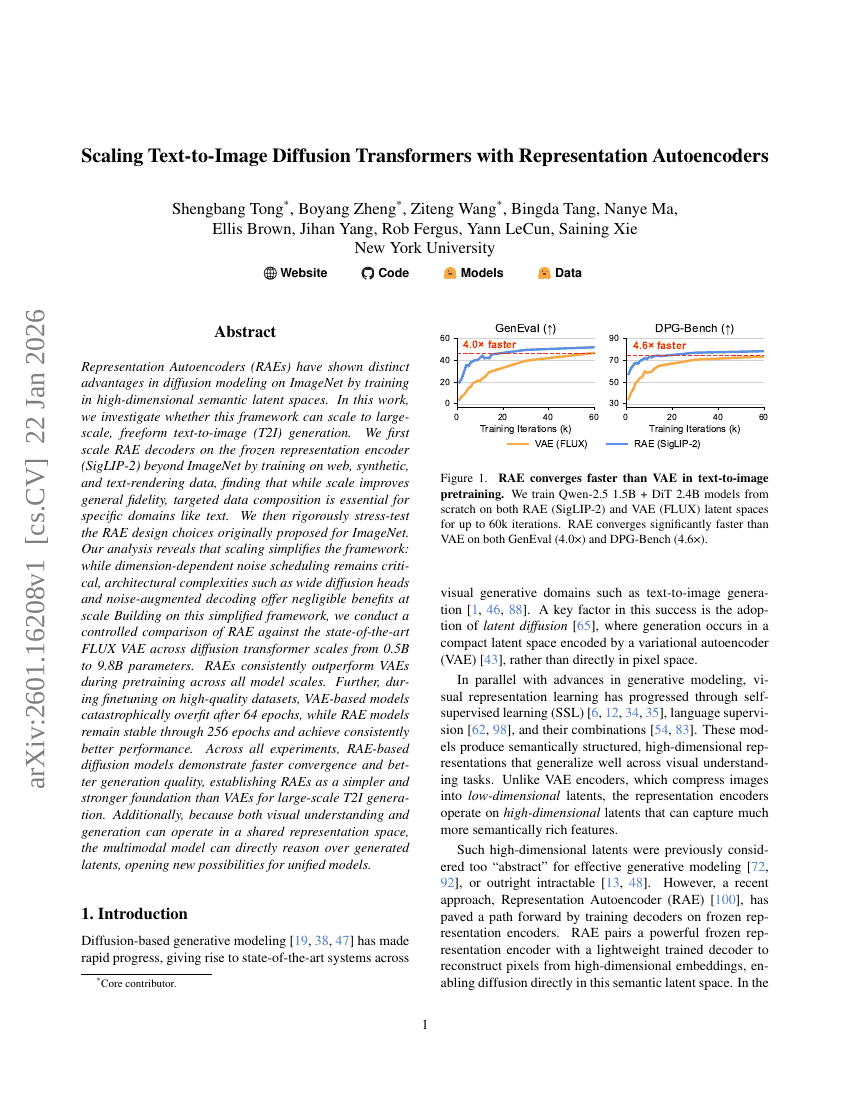
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
BayesianVLA: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
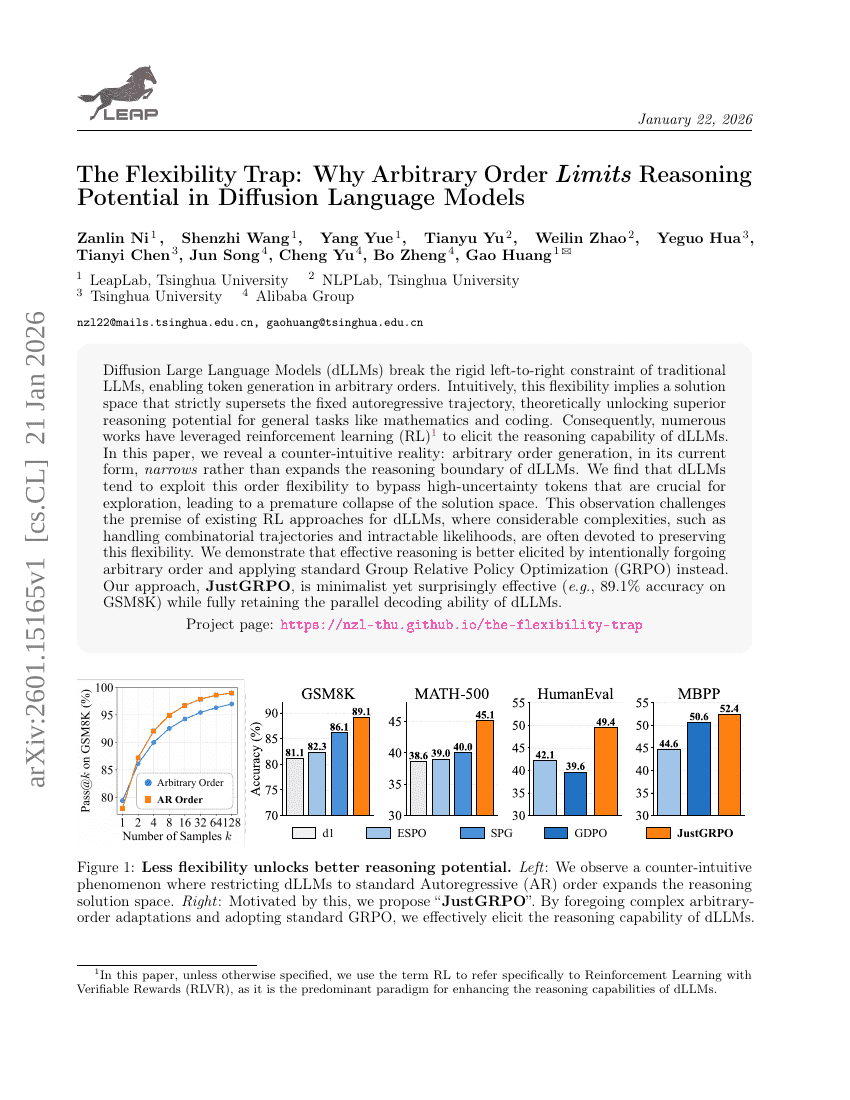
The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models
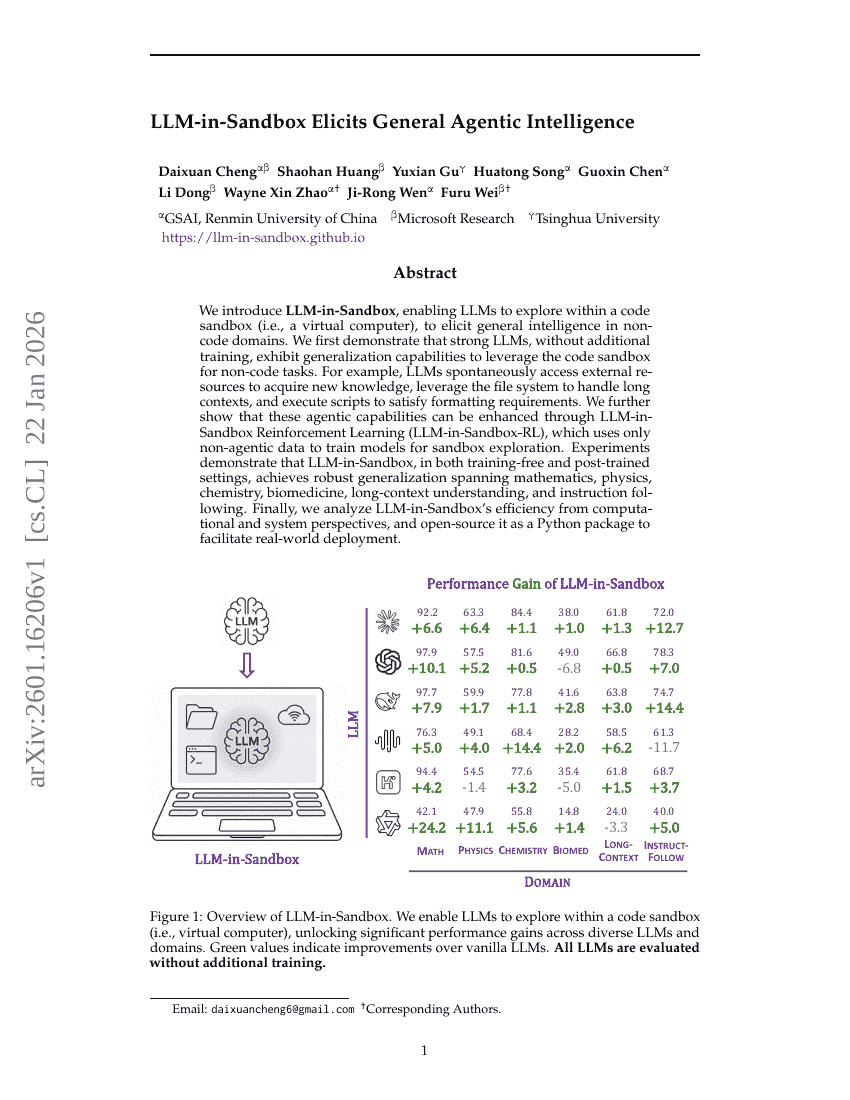
LLM-in-Sandbox Elicits General Agentic Intelligence
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
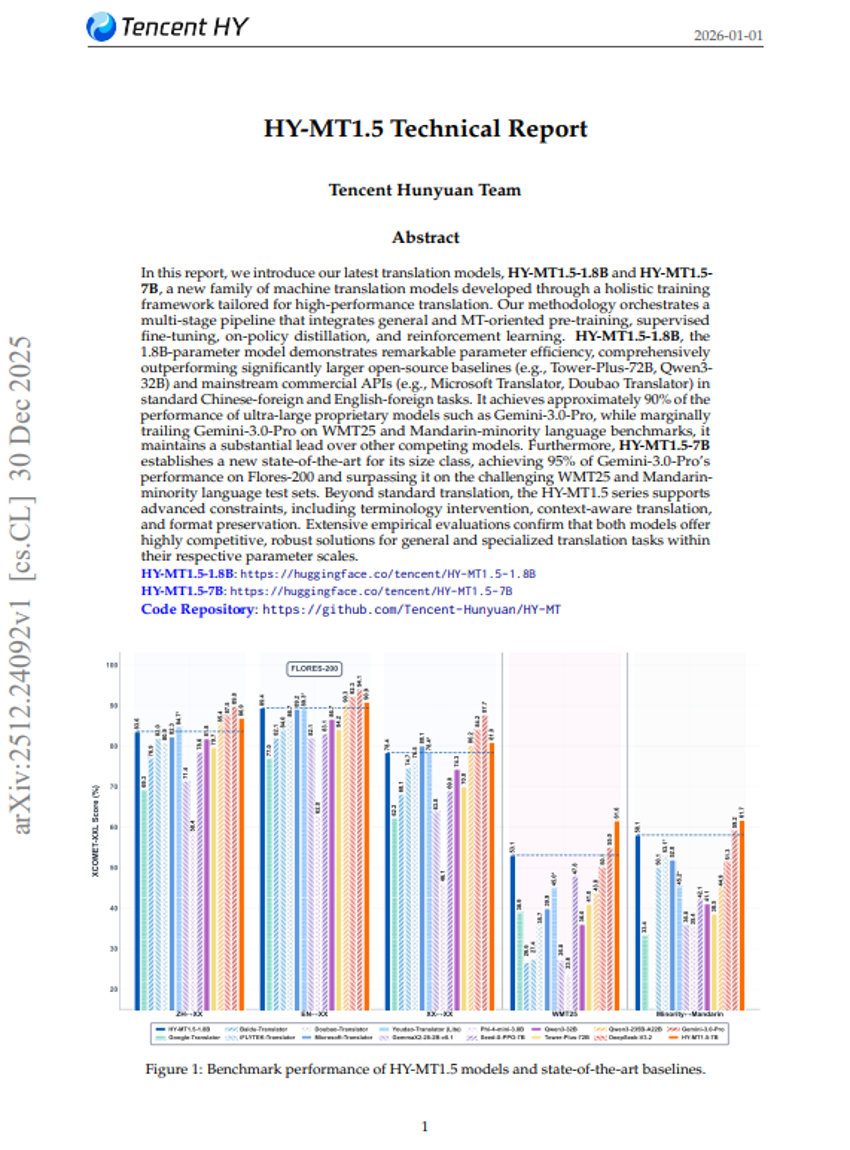
HY-MT1.5 Technical Report
Scaling Laws for Code: Every Programming Language Matters
Qwen3-TTS Technical Report
Small Models, Big Results: Achieving Superior Intent Extraction through Decomposition
FinVault: Benchmarking Financial Agent Safety in Execution-Grounded Environments
MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
iFSQ: Improving FSQ for Image Generation with 1 Line of Code
Elastic Attention: Test-time Adaptive Sparsity Ratios for Efficient Transformers
Scientific Image Synthesis: Benchmarking, Methodologies, and Downstream Utility
The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation
daVinci-Dev: Agent-native Mid-training for Software Engineering
Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs
DeepSeek-OCR 2: Visual Causal Flow
Learning to Discover at Test Time
Eliciting Harmful Capabilities by Fine-Tuning On Safeguarded Outputs
Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
LongCat-Flash-Thinking-2601 Technical Report
Can Language Models Discover Scaling Laws?
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Triton-distributed: Programming Overlapping Kernels on Distributed AI Systems with the Triton Compiler
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
BayesianVLA: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models
LLM-in-Sandbox Elicits General Agentic Intelligence
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
HY-MT1.5 Technical Report
Scaling Laws for Code: Every Programming Language Matters
Qwen3-TTS Technical Report
Small Models, Big Results: Achieving Superior Intent Extraction through Decomposition
FinVault: Benchmarking Financial Agent Safety in Execution-Grounded Environments
MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents