HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

HaluMem: Evaluating Hallucinations in Memory Systems of Agents

GVPO: Group Variance Policy Optimization for Large Language Model Post-Training




























HaluMem: Evaluating Hallucinations in Memory Systems of Agents
GVPO: Group Variance Policy Optimization for Large Language Model Post-Training
ReCA: Integrated Acceleration for Real-Time and Efficient Cooperative Embodied Autonomous Agents
DexFlyWheel: A Scalable and Self-improving Data Generation Framework for Dexterous Manipulation
NovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
TreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
GTA: Supervised-Guided Reinforcement Learning for Text Classification with Large Language Models
Modeling protein-small molecule conformational ensembles with PLACER
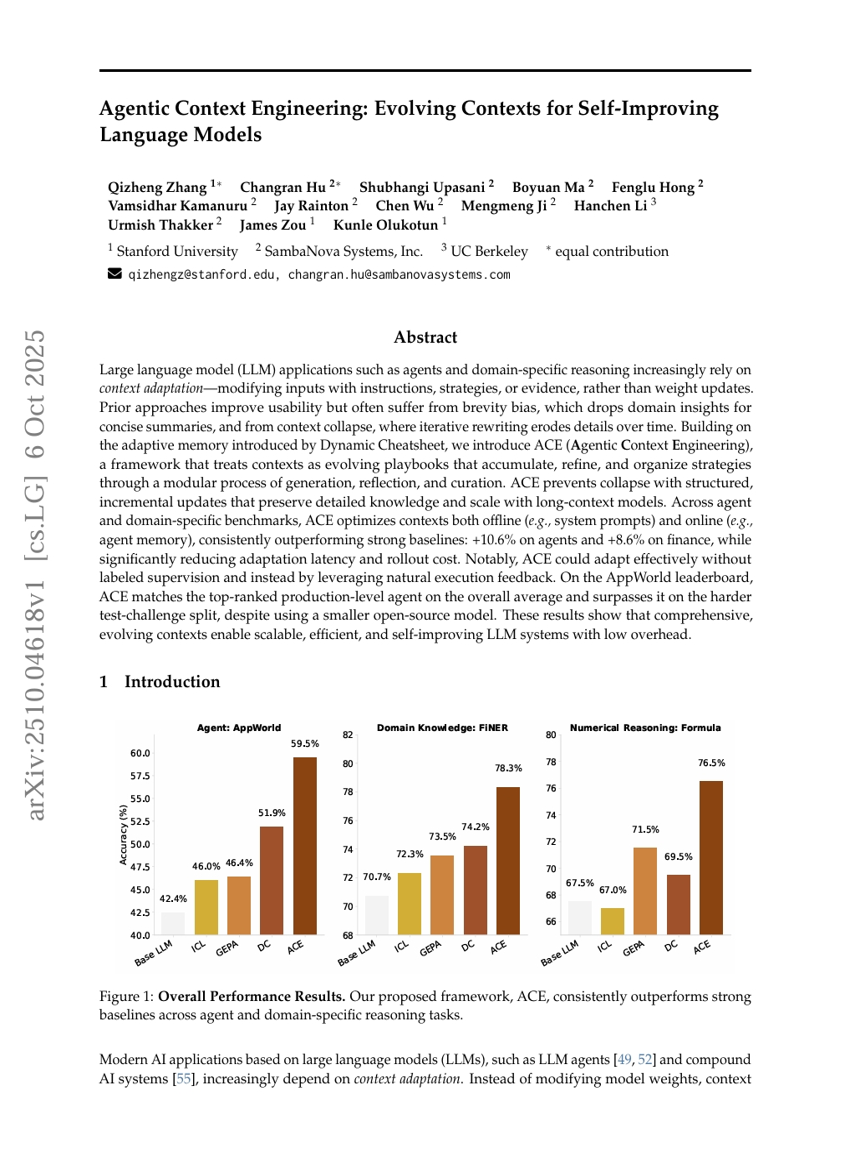
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
DiaMoE-TTS: A Unified IPA-Based Dialect TTS Framework with Mixture-of-Experts and Parameter-Efficient Zero-Shot Adaptation
AI Assisted AR Assembly: Object Recognition and Computer Vision for Augmented Reality Assisted Assembly
Jailbreaking in the Haystack
CritiCal: Can Critique Help LLM Uncertainty or Confidence Calibration?
Towards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings
Visual Spatial Tuning
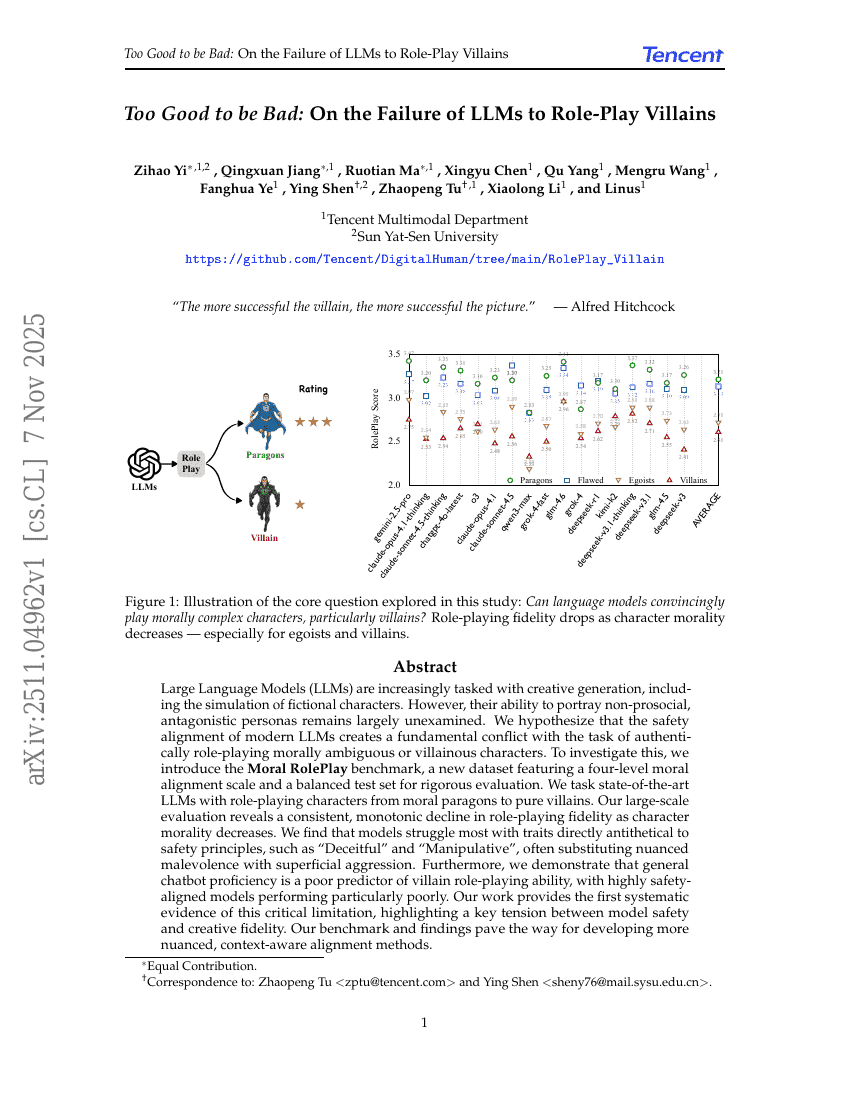
Too Good to be Bad: On the Failure of LLMs to Role-Play Villains
DeepEyesV2: Toward Agentic Multimodal Model
Use of Continuous Glucose Monitoring with Machine Learning to Identify Metabolic Subphenotypes and Inform Precision Lifestyle Changes
Reusing Pre-Training Data at Test Time is a Compute Multiplier
NVIDIA Nemotron Nano V2 VL
CostBench: Evaluating Multi-Turn Cost-Optimal Planning and Adaptation in Dynamic Environments for LLM Tool-Use Agents
Cambrian-S: Towards Spatial Supersensing in Video
Scaling Agent Learning via Experience Synthesis
V-Thinker: Interactive Thinking with Images
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Recent Developments in Amber Biomolecular Simulations
UltraHR-100K: Enhancing UHR Image Synthesis with A Large-Scale High-Quality Dataset
From Five Dimensions to Many: Large Language Models as Precise and Interpretable Psychological Profilers
Node-Based Editing for Multimodal Generation of Text, Audio, Image, and Video
DR. WELL: Dynamic Reasoning and Learning with Symbolic World Model for Embodied LLM-Based Multi-Agent Collaboration
Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning
TabTune: A Unified Library for Inference and Fine-Tuning Tabular Foundation Models
ReCA: Integrated Acceleration for Real-Time and Efficient Cooperative Embodied Autonomous Agents
DexFlyWheel: A Scalable and Self-improving Data Generation Framework for Dexterous Manipulation
NovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
TreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
GTA: Supervised-Guided Reinforcement Learning for Text Classification with Large Language Models
Modeling protein-small molecule conformational ensembles with PLACER
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
DiaMoE-TTS: A Unified IPA-Based Dialect TTS Framework with Mixture-of-Experts and Parameter-Efficient Zero-Shot Adaptation
AI Assisted AR Assembly: Object Recognition and Computer Vision for Augmented Reality Assisted Assembly
Jailbreaking in the Haystack
CritiCal: Can Critique Help LLM Uncertainty or Confidence Calibration?
Towards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings
Visual Spatial Tuning
Too Good to be Bad: On the Failure of LLMs to Role-Play Villains
DeepEyesV2: Toward Agentic Multimodal Model
Use of Continuous Glucose Monitoring with Machine Learning to Identify Metabolic Subphenotypes and Inform Precision Lifestyle Changes
Reusing Pre-Training Data at Test Time is a Compute Multiplier
NVIDIA Nemotron Nano V2 VL
CostBench: Evaluating Multi-Turn Cost-Optimal Planning and Adaptation in Dynamic Environments for LLM Tool-Use Agents
Cambrian-S: Towards Spatial Supersensing in Video
Scaling Agent Learning via Experience Synthesis
V-Thinker: Interactive Thinking with Images
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Recent Developments in Amber Biomolecular Simulations
UltraHR-100K: Enhancing UHR Image Synthesis with A Large-Scale High-Quality Dataset
From Five Dimensions to Many: Large Language Models as Precise and Interpretable Psychological Profilers
Node-Based Editing for Multimodal Generation of Text, Audio, Image, and Video
DR. WELL: Dynamic Reasoning and Learning with Symbolic World Model for Embodied LLM-Based Multi-Agent Collaboration
Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning
TabTune: A Unified Library for Inference and Fine-Tuning Tabular Foundation Models