HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

A Survey of Data Agents: Emerging Paradigm or Overstated Hype?

ReCode: Unify Plan and Action for Universal Granularity Control

Concerto: Joint 2D-3D Self-Supervised Learning Emerges Spatial Representations

Magellan: Guided MCTS for Latent Space Exploration and Novelty Generation

DEEDEE: Fast and Scalable Out-of-Distribution Dynamics Detection

Sparser Block-Sparse Attention via Token Permutation

A Definition of AGI

From Denoising to Refining: A Corrective Framework for Vision-Language Diffusion Model

Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation

Video-As-Prompt: Unified Semantic Control for Video Generation
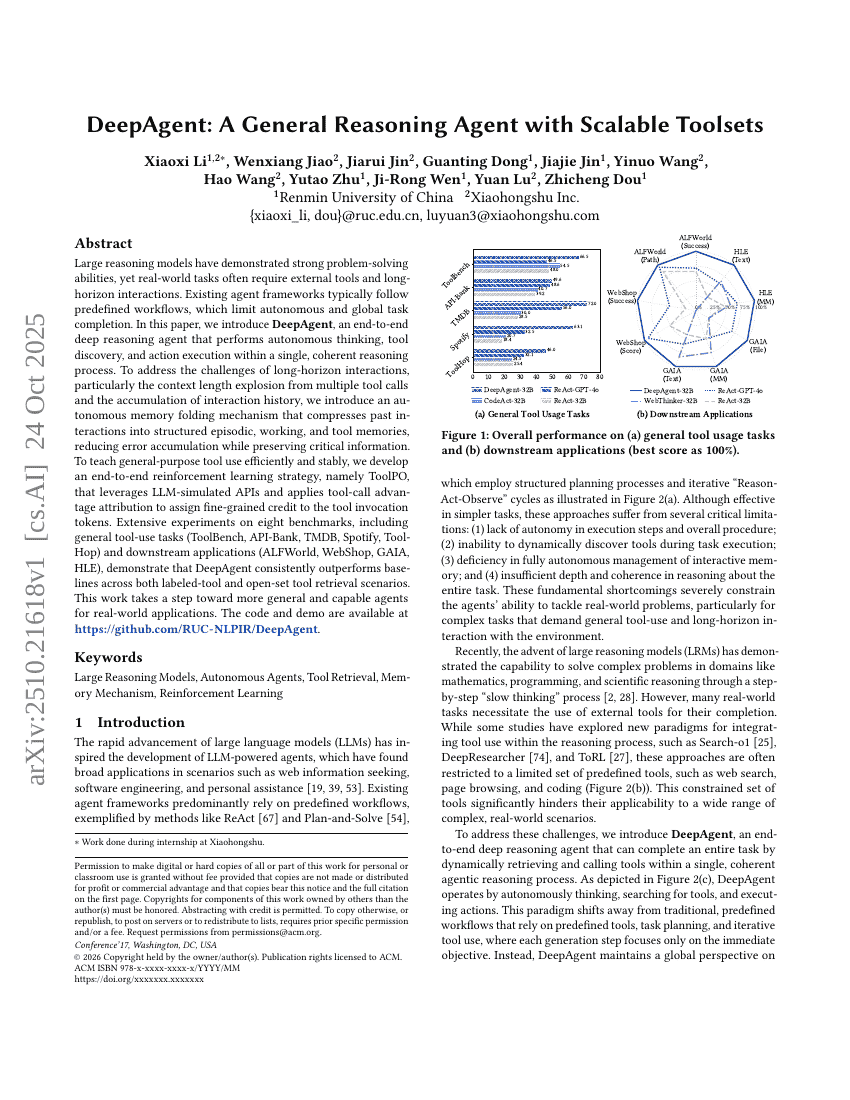
DeepAgent: A General Reasoning Agent with Scalable Toolsets

Uncertainty-Aware Multi-Objective Reinforcement Learning-Guided Diffusion Models for 3D De Novo Molecular Design

Reac-Discovery: an artificial intelligence–driven platform for continuous-flow catalytic reactor discovery and optimization

BoltzGen:Toward Universal Binder Design
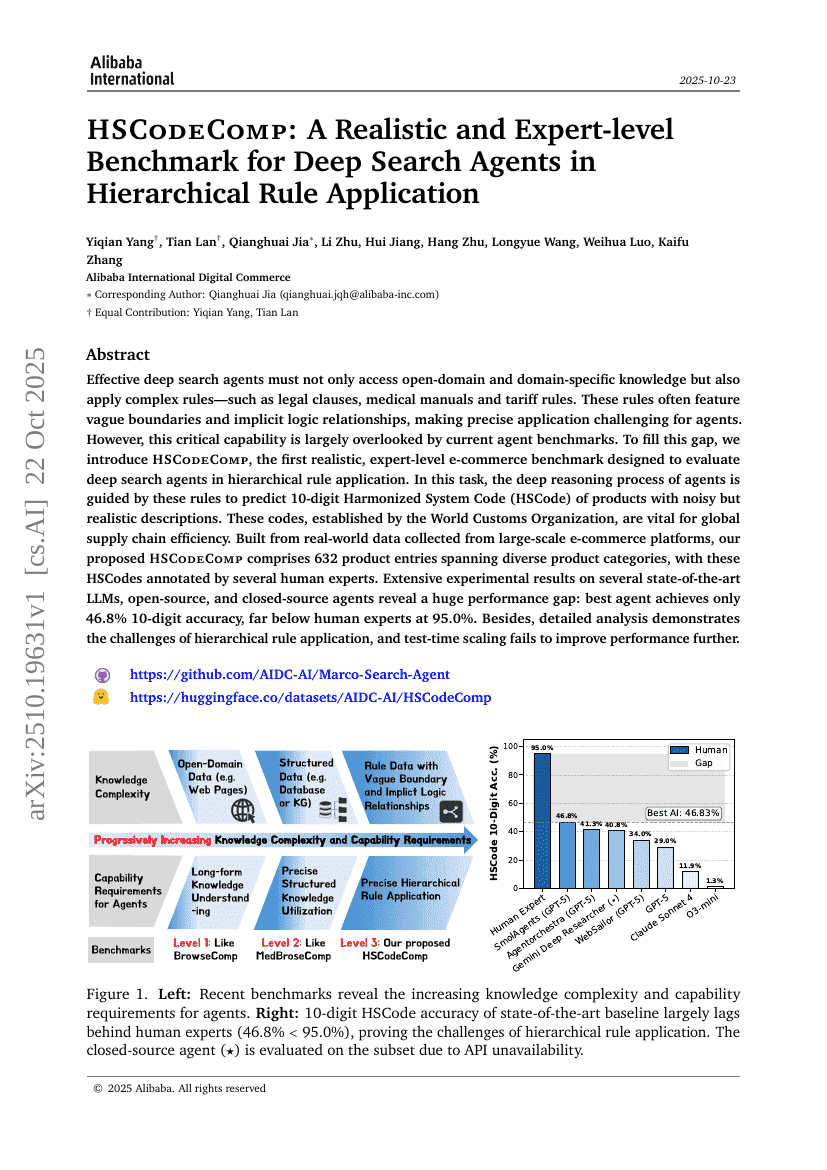
HSCodeComp: A Realistic and Expert-level Benchmark for Deep Search Agents in Hierarchical Rule Application

DyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion

HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives

Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence

AdaSPEC: Selective Knowledge Distillation for Efficient Speculative Decoders

Human-Agent Collaborative Paper-to-Page Crafting for Under $0.1
See the Text: From Tokenization to Visual Reading
Directional Reasoning Injection for Fine-Tuning MLLMs

Language Models are Injective and Hence Invertible

The Free Transformer

Quantum Processing Unit (QPU) processing time Prediction with Machine Learning

Observation of constructive interference at the edge of quantum ergodicity

VideoAgentTrek: Computer Use Pretraining from Unlabeled Videos

GigaBrain-0: A World Model-Powered Vision-Language-Action Model

LoongRL:Reinforcement Learning for Advanced Reasoning over Long Contexts
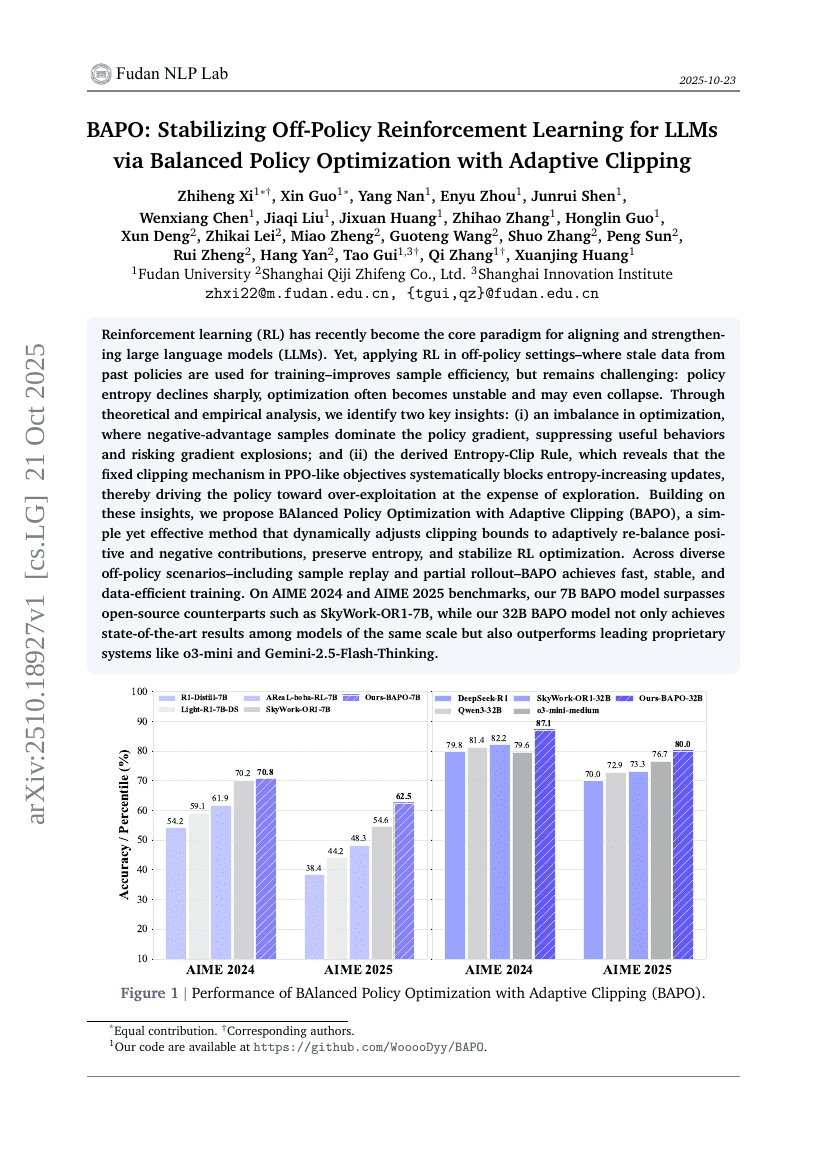
BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping

Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning

Color Me Correctly: Bridging Perceptual Color Spaces and Text Embeddings for Improved Diffusion Generation
A Survey of Data Agents: Emerging Paradigm or Overstated Hype?
ReCode: Unify Plan and Action for Universal Granularity Control
Concerto: Joint 2D-3D Self-Supervised Learning Emerges Spatial Representations
Magellan: Guided MCTS for Latent Space Exploration and Novelty Generation
DEEDEE: Fast and Scalable Out-of-Distribution Dynamics Detection
Sparser Block-Sparse Attention via Token Permutation
A Definition of AGI
From Denoising to Refining: A Corrective Framework for Vision-Language Diffusion Model
Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
Video-As-Prompt: Unified Semantic Control for Video Generation
DeepAgent: A General Reasoning Agent with Scalable Toolsets
Uncertainty-Aware Multi-Objective Reinforcement Learning-Guided Diffusion Models for 3D De Novo Molecular Design
Reac-Discovery: an artificial intelligence–driven platform for continuous-flow catalytic reactor discovery and optimization
BoltzGen:Toward Universal Binder Design
HSCodeComp: A Realistic and Expert-level Benchmark for Deep Search Agents in Hierarchical Rule Application
DyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion
HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence
AdaSPEC: Selective Knowledge Distillation for Efficient Speculative Decoders
Human-Agent Collaborative Paper-to-Page Crafting for Under $0.1
See the Text: From Tokenization to Visual Reading
Directional Reasoning Injection for Fine-Tuning MLLMs
Language Models are Injective and Hence Invertible
The Free Transformer
Quantum Processing Unit (QPU) processing time Prediction with Machine Learning
Observation of constructive interference at the edge of quantum ergodicity
VideoAgentTrek: Computer Use Pretraining from Unlabeled Videos
GigaBrain-0: A World Model-Powered Vision-Language-Action Model
LoongRL:Reinforcement Learning for Advanced Reasoning over Long Contexts
BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping
Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning
Color Me Correctly: Bridging Perceptual Color Spaces and Text Embeddings for Improved Diffusion Generation