HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction

EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation























Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
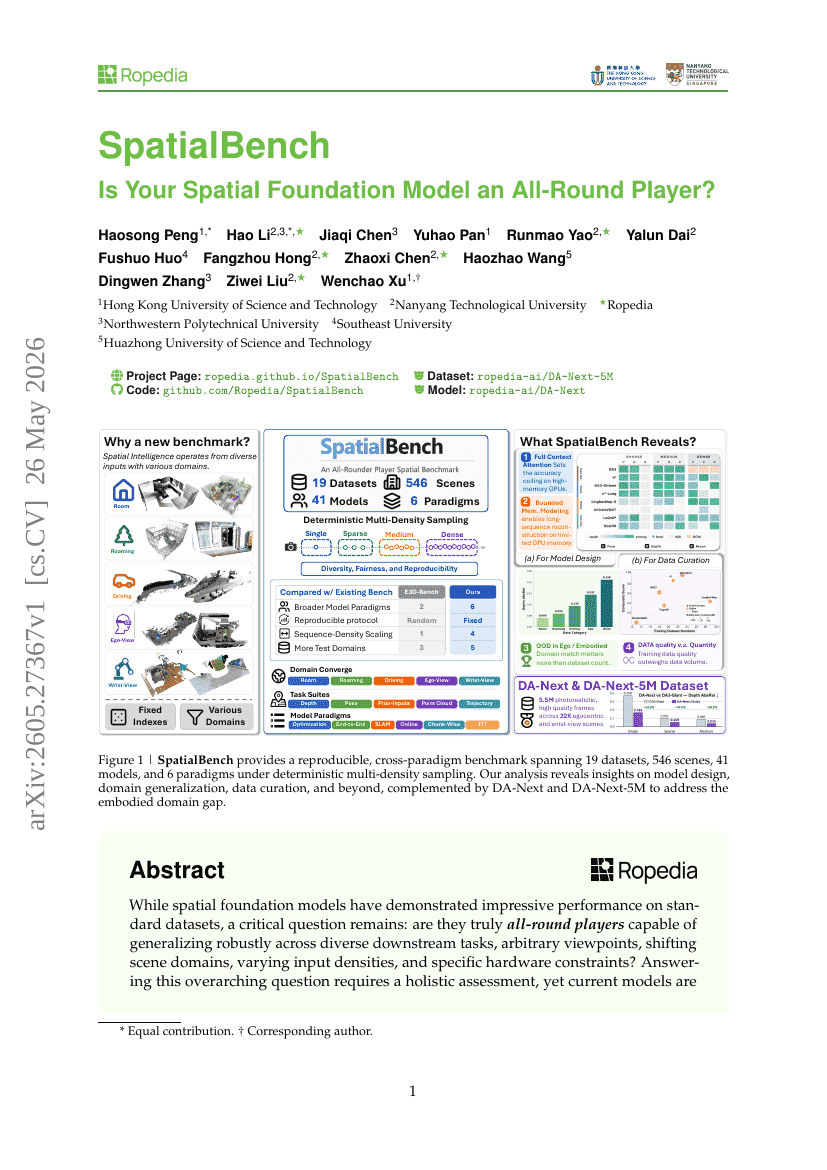
SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini
Language Models Need Sleep
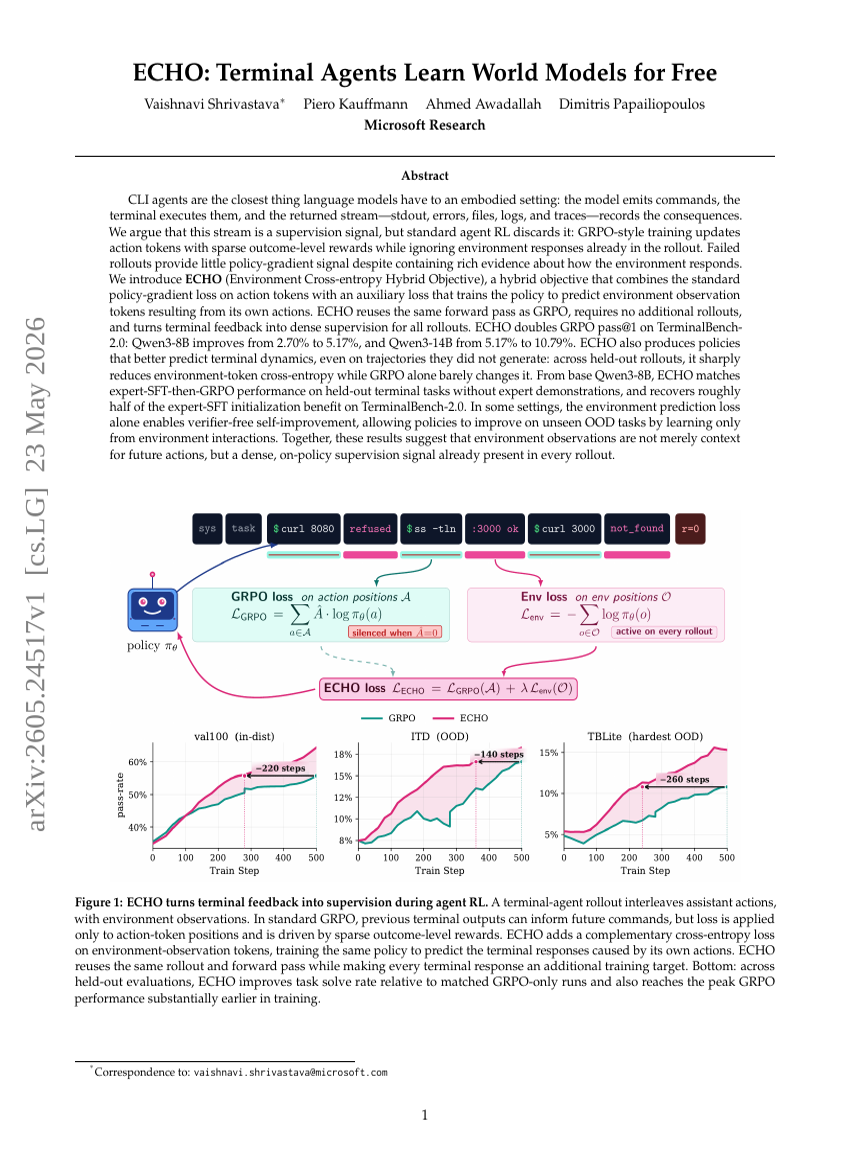
ECHO: Terminal Agents Learn World Models for Free
ParaVT: Taming the Tool Prior Paradox for Parallel Tool Use in Agentic Video Reinforcement Learning
TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
Foundation Protocol: A Coordination Layer for Agentic Society
WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
Macaron-A2UI: A Model for Generative UI in Personal Agents
DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning
ViMU: Benchmarking Video Metaphorical Understanding
SMOL: Professionally translated parallel data for 115 under-represented languages
Chi-Bench: Can AI Agents Automate End-to-End, Long-Horizon, Policy-Rich Healthcare Workflows?
Combining On-Policy Optimization and Distillation for Long-Context Reasoning in Large Language Models
Through the Lens of Contrast: Self-Improving Visual Reasoning in VLMs
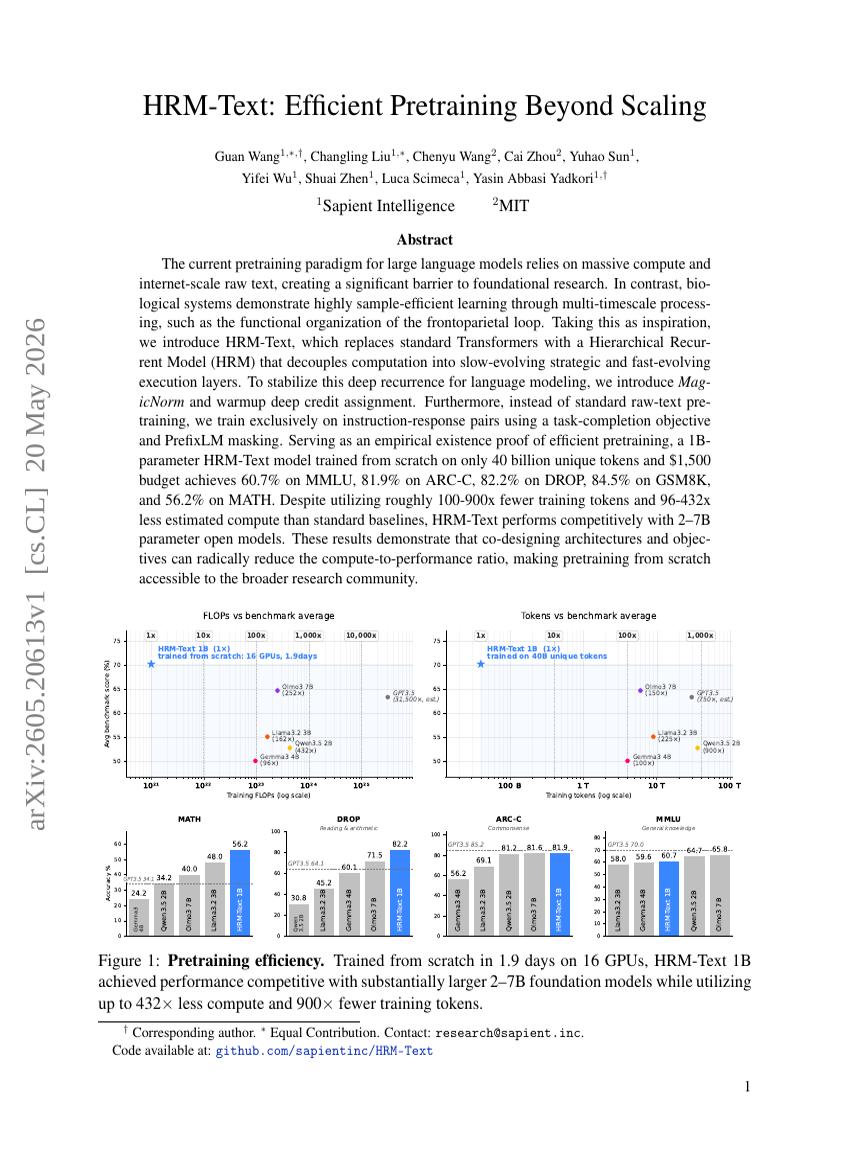
HRM-Text: Efficient Pretraining Beyond Scaling
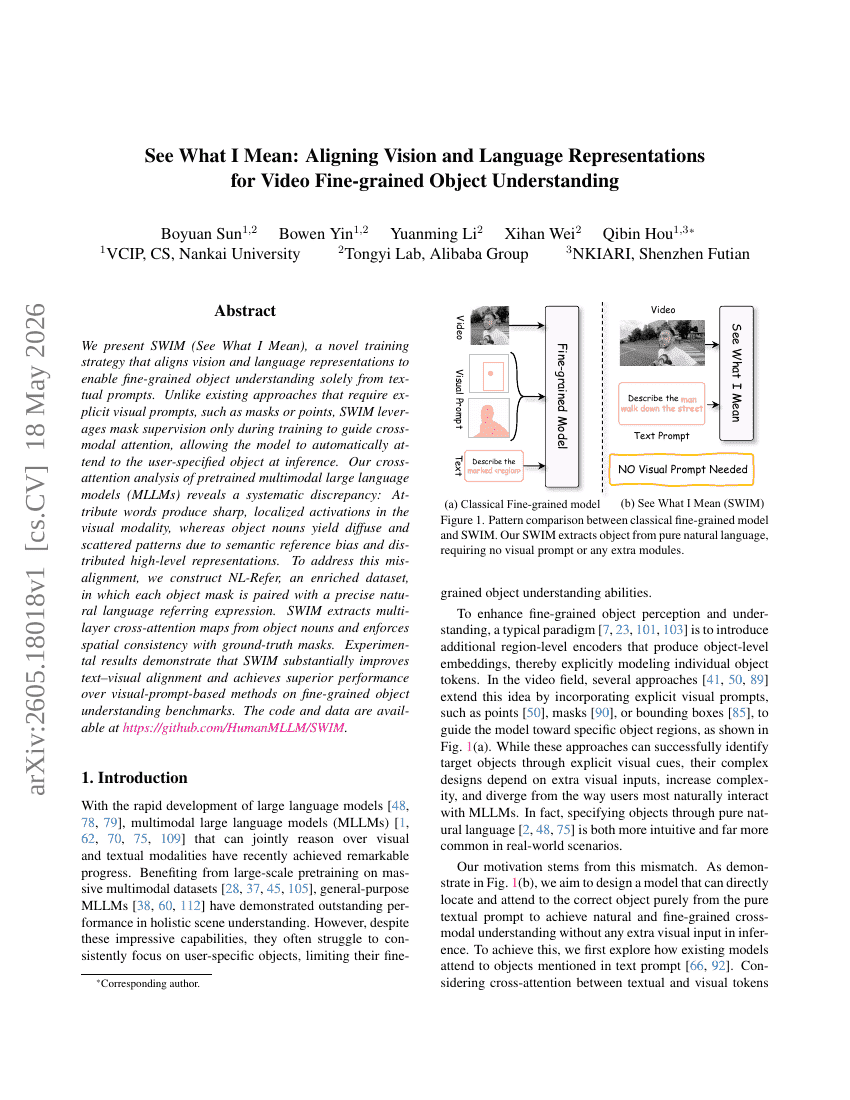
See What I Mean: Aligning Vision and Language Representations for Video Fine-grained Object Understanding
StepAudio 2.5 Technical Report
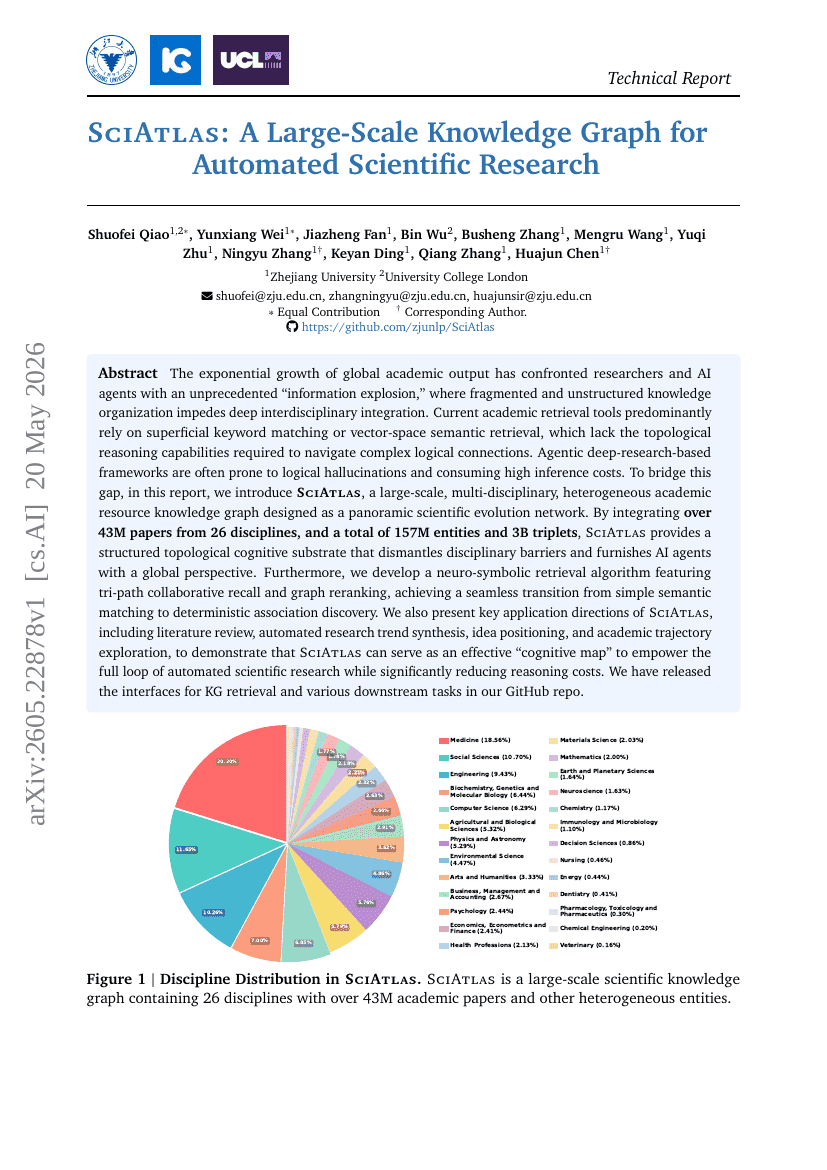
SciAtlas: A Large-Scale Knowledge Graph for Automated Scientific Research
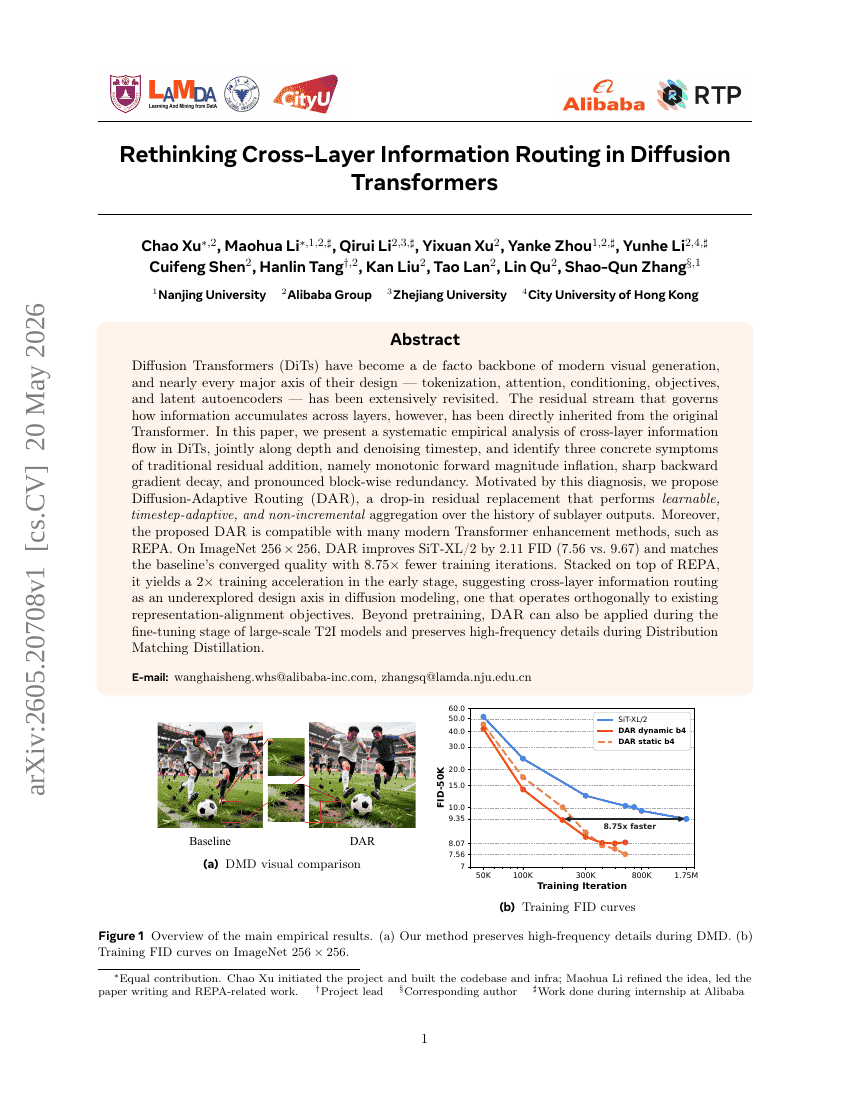
Rethinking Cross-Layer Information Routing in Diffusion Transformers
Lens: Rethinking Training Efficiency for Foundational Text-to-Image Models
SkillOpt: Executive Strategy for Self-Evolving Agent Skills
CVEvolve: Autonomous Algorithm Discovery for Unstructured Scientific Data Processing
Poly-EPO: Training Exploratory Reasoning Models
MEMO: Memory as a Model
ACC: Compiling Agent Trajectories for Long-Context Training
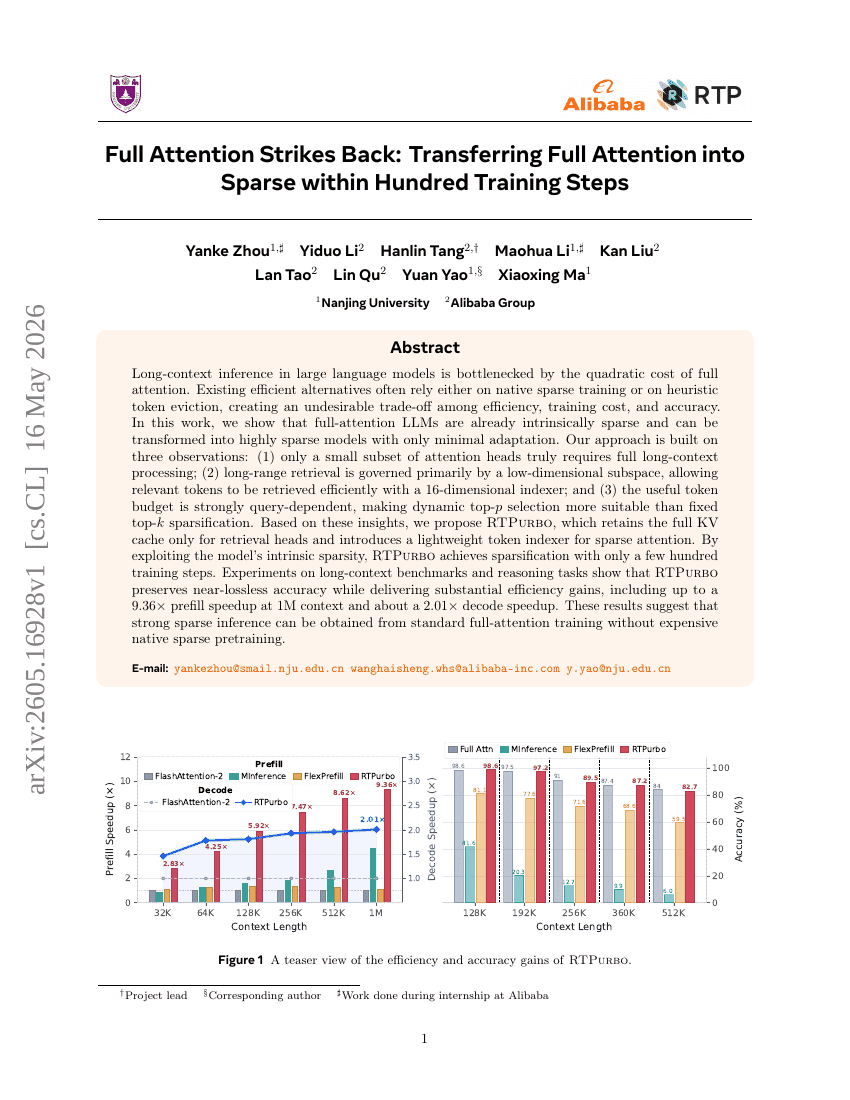
Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini
Language Models Need Sleep
ECHO: Terminal Agents Learn World Models for Free
ParaVT: Taming the Tool Prior Paradox for Parallel Tool Use in Agentic Video Reinforcement Learning
TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
Foundation Protocol: A Coordination Layer for Agentic Society
WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
Macaron-A2UI: A Model for Generative UI in Personal Agents
DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning
ViMU: Benchmarking Video Metaphorical Understanding
SMOL: Professionally translated parallel data for 115 under-represented languages
Chi-Bench: Can AI Agents Automate End-to-End, Long-Horizon, Policy-Rich Healthcare Workflows?
Combining On-Policy Optimization and Distillation for Long-Context Reasoning in Large Language Models
Through the Lens of Contrast: Self-Improving Visual Reasoning in VLMs
HRM-Text: Efficient Pretraining Beyond Scaling
See What I Mean: Aligning Vision and Language Representations for Video Fine-grained Object Understanding
StepAudio 2.5 Technical Report
SciAtlas: A Large-Scale Knowledge Graph for Automated Scientific Research
Rethinking Cross-Layer Information Routing in Diffusion Transformers
Lens: Rethinking Training Efficiency for Foundational Text-to-Image Models
SkillOpt: Executive Strategy for Self-Evolving Agent Skills
CVEvolve: Autonomous Algorithm Discovery for Unstructured Scientific Data Processing
Poly-EPO: Training Exploratory Reasoning Models
MEMO: Memory as a Model
ACC: Compiling Agent Trajectories for Long-Context Training
Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows