HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Continual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments

MEMORY CACHING: RNNs with Growing Memory


























Continual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments
MEMORY CACHING: RNNs with Growing Memory
RobotValues: Evaluating Household Robots When Human Values Conflict
VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
ArcANE: Do Role-Playing Language Agents Stay in Character at the Right Time?
Code2LoRA: Hypernetwork-Generated Adapters for Code Language Models under Software Evolution
Self-Distilled Policy Gradient
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation
Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Qwen-Image-Flash: Beyond Objective Design
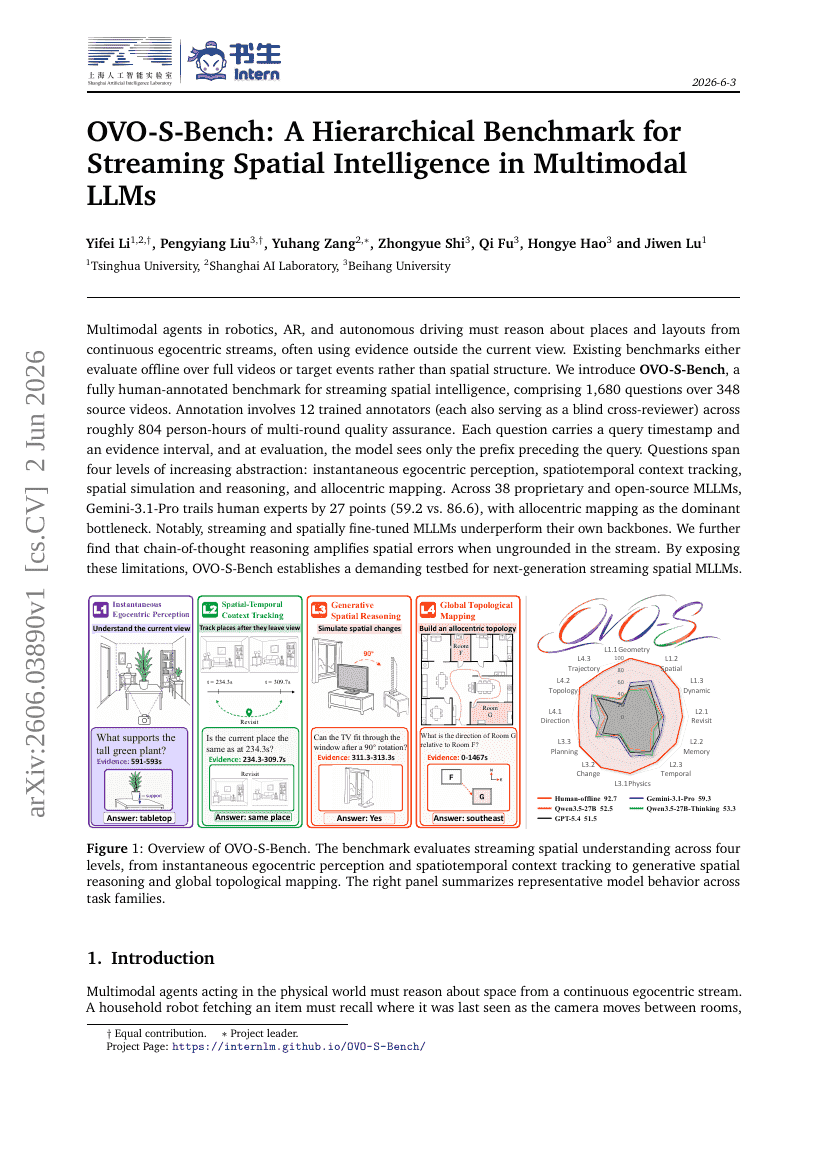
OVO-S-Bench: A Hierarchical Benchmark for Streaming Spatial Intelligence in Multimodal LLMs
Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories
Audio Interaction Model
Cosmos 3: Omnimodal World Models for Physical AI
Learning, Fast and Slow: Towards LLMs That Adapt Continually
LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks
World Models Meet Language Models: On the Complementarity of Concrete and Abstract Reasoning
From Activation to Causality: Discovery of Causal Visual Representations in the Human Brain
A Local Perturbation Theory for Cross-Domain Interference and Recovery in Multi-Domain RL
Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
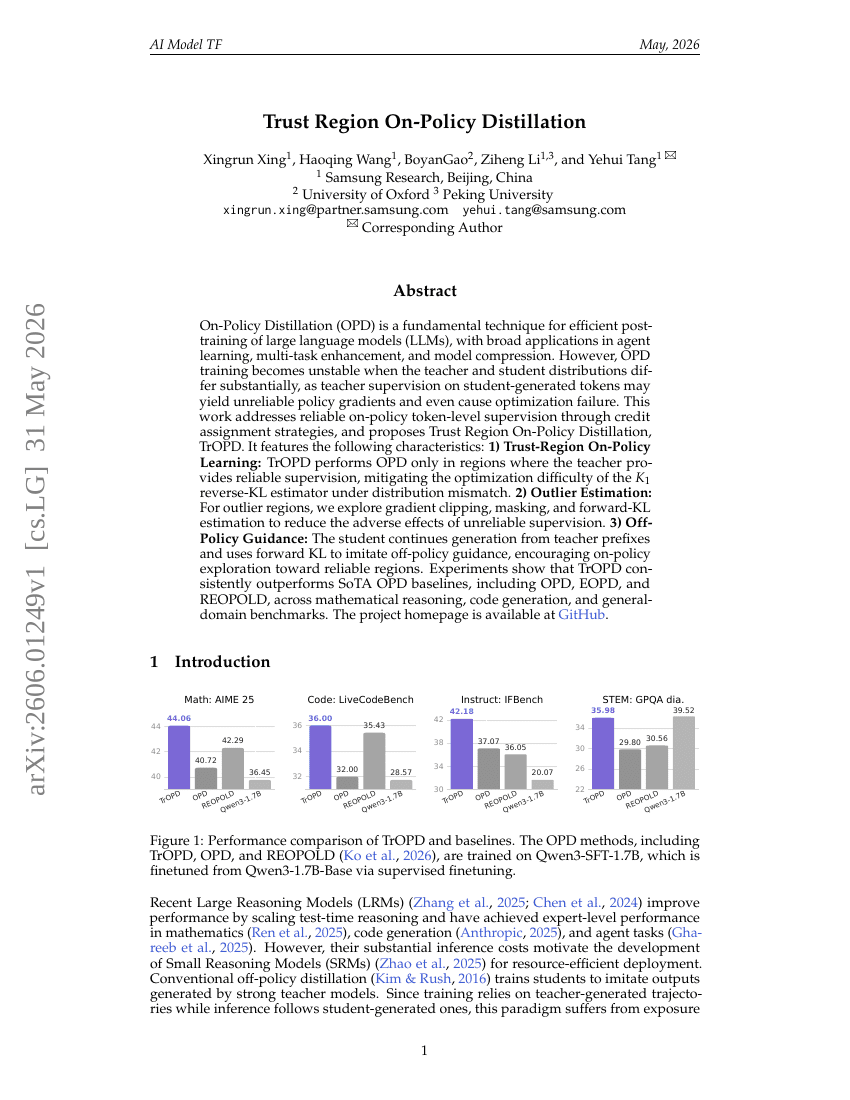
Trust Region On-Policy Distillation
OCC-RAG: Optimal Cognitive Core for Faithful Question Answering
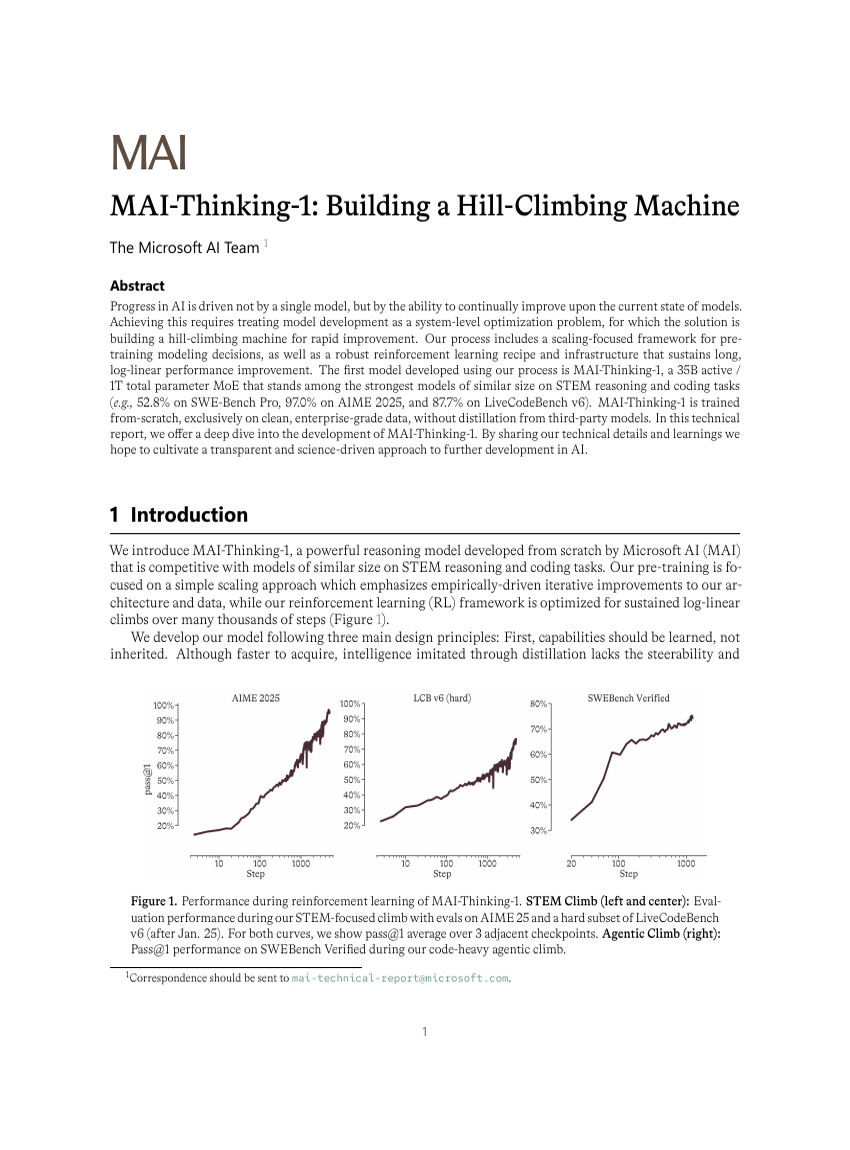
MAI-Thinking-1: Building a Hill-Climbing Machine
VLM3: Vision Language Models Are Native 3D Learners
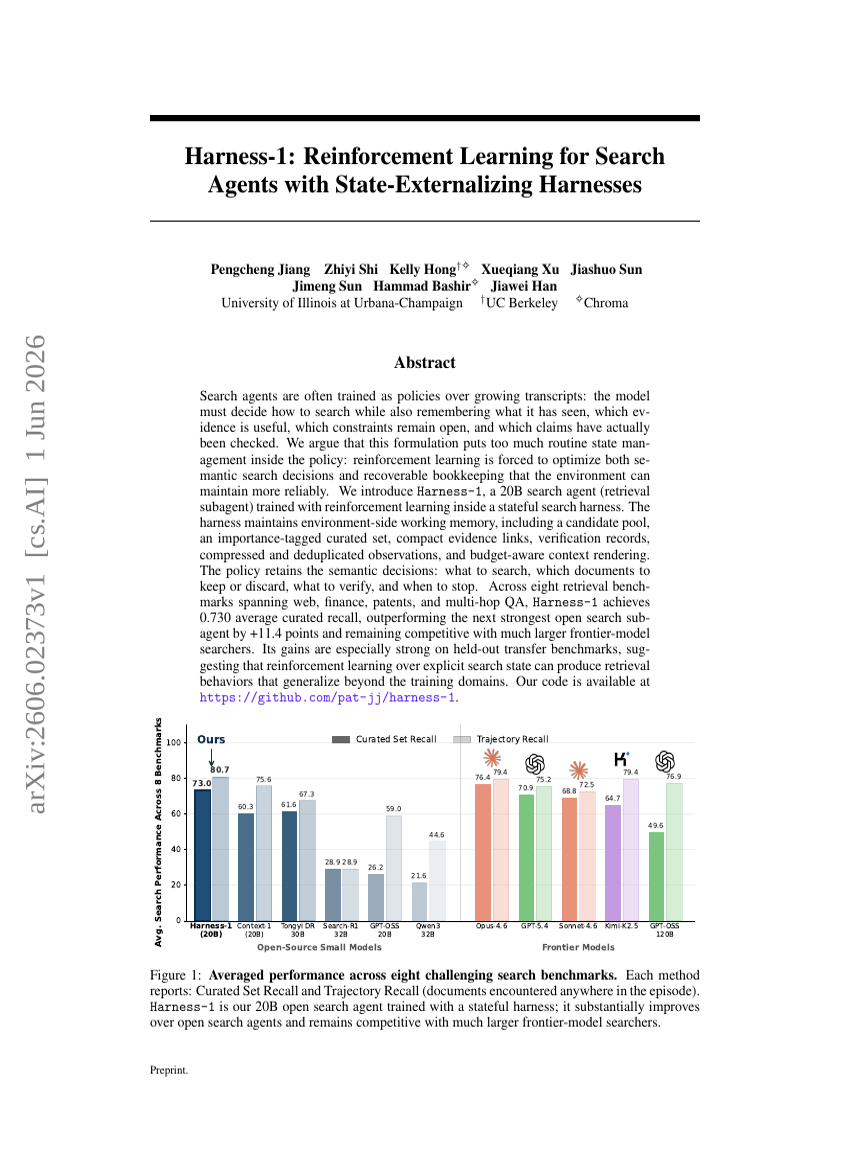
Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
DeepCrack: A deep hierarchical feature learning architecture for crack segmentation
VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
Draft-OPD: On-Policy Distillation for Speculative Draft Models
RobotValues: Evaluating Household Robots When Human Values Conflict
VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
ArcANE: Do Role-Playing Language Agents Stay in Character at the Right Time?
Code2LoRA: Hypernetwork-Generated Adapters for Code Language Models under Software Evolution
Self-Distilled Policy Gradient
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation
Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Qwen-Image-Flash: Beyond Objective Design
OVO-S-Bench: A Hierarchical Benchmark for Streaming Spatial Intelligence in Multimodal LLMs
Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories
Audio Interaction Model
Cosmos 3: Omnimodal World Models for Physical AI
Learning, Fast and Slow: Towards LLMs That Adapt Continually
LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks
World Models Meet Language Models: On the Complementarity of Concrete and Abstract Reasoning
From Activation to Causality: Discovery of Causal Visual Representations in the Human Brain
A Local Perturbation Theory for Cross-Domain Interference and Recovery in Multi-Domain RL
Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
Trust Region On-Policy Distillation
OCC-RAG: Optimal Cognitive Core for Faithful Question Answering
MAI-Thinking-1: Building a Hill-Climbing Machine
VLM3: Vision Language Models Are Native 3D Learners
Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
DeepCrack: A deep hierarchical feature learning architecture for crack segmentation
VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
Draft-OPD: On-Policy Distillation for Speculative Draft Models