HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

EmbeddingGemma: Powerful and Lightweight Text Representations

Advancing Speech Understanding in Speech-Aware Language Models with GRPO

How Far are VLMs from Visual Spatial Intelligence? A Benchmark-Driven Perspective

SIM-CoT: Supervised Implicit Chain-of-Thought

SWE-QA: Can Language Models Answer Repository-level Code Questions?

Video models are zero-shot learners and reasoners

An N-Plus-1 GPT Agency for Critical Solution of Mechanical Engineering Analysis Problems
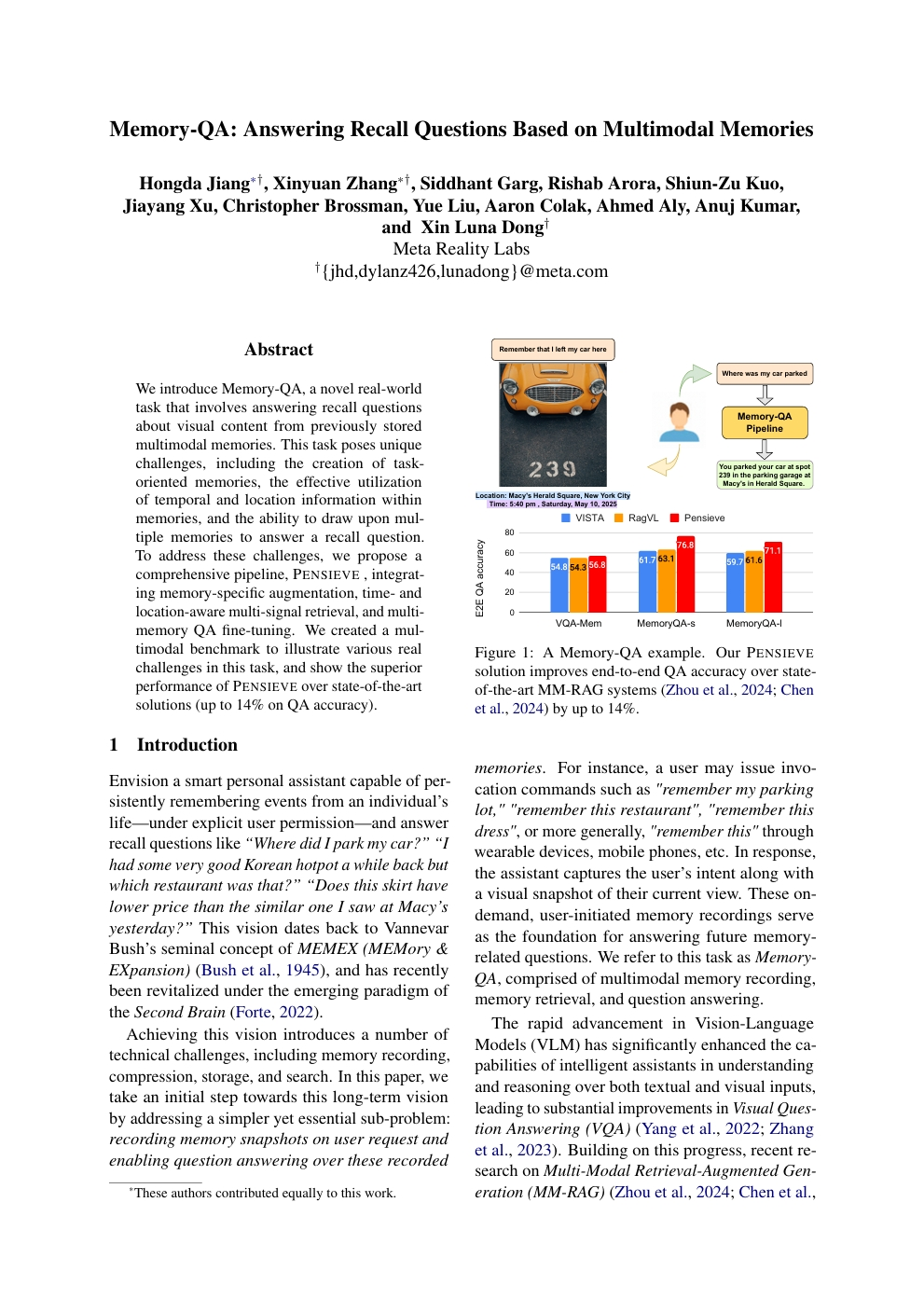
Memory-QA: Answering Recall Questions Based on Multimodal Memories

MAPO: Mixed Advantage Policy Optimization

Hyper-Bagel: A Unified Acceleration Framework for Multimodal Understanding and Generation
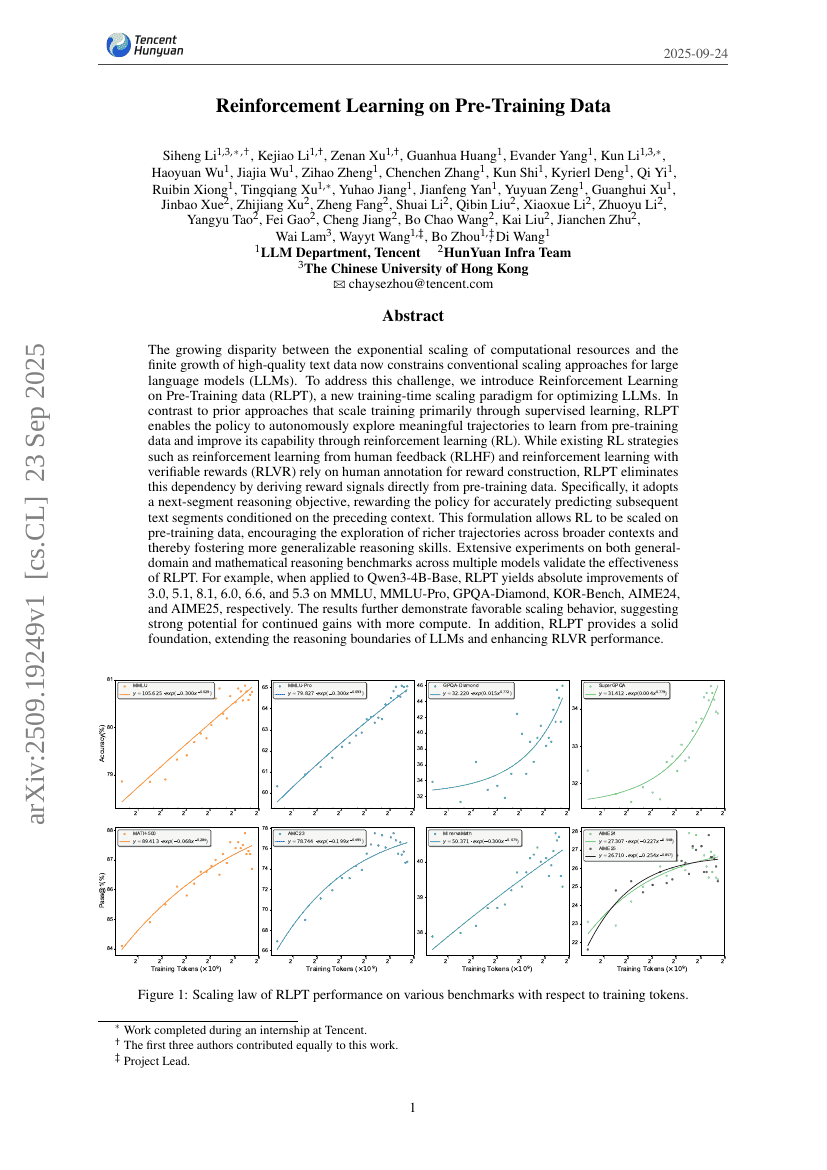
Reinforcement Learning on Pre-Training Data

Do You Need Proprioceptive States in Visuomotor Policies?

Baseer: A Vision-Language Model for Arabic Document-to-Markdown OCR

GenExam: A Multidisciplinary Text-to-Image Exam

Nav-R1: Reasoning and Navigation in Embodied Scenes

MoEs Are Stronger than You Think: Hyper-Parallel Inference Scaling with RoE
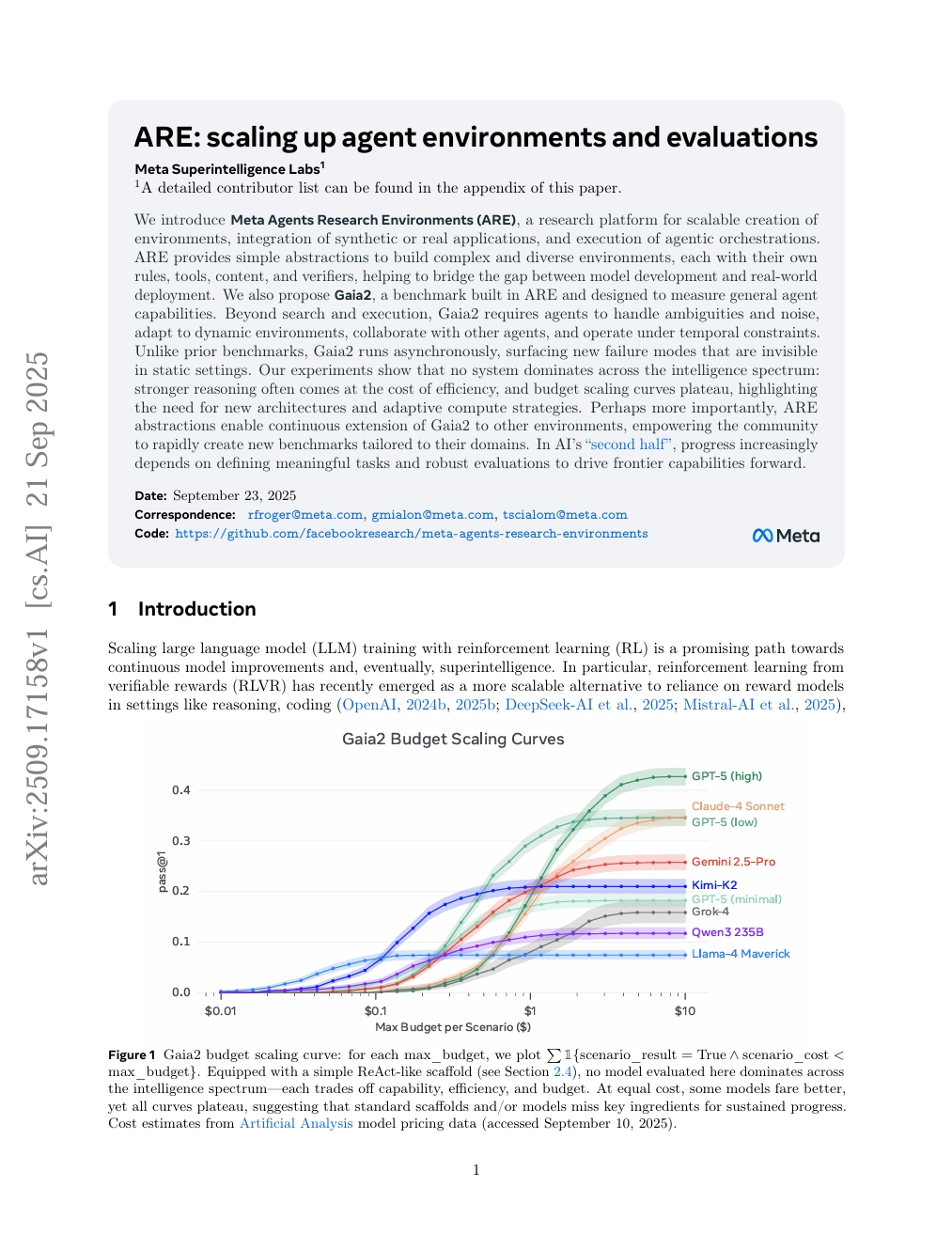
ARE: Scaling Up Agent Environments and Evaluations
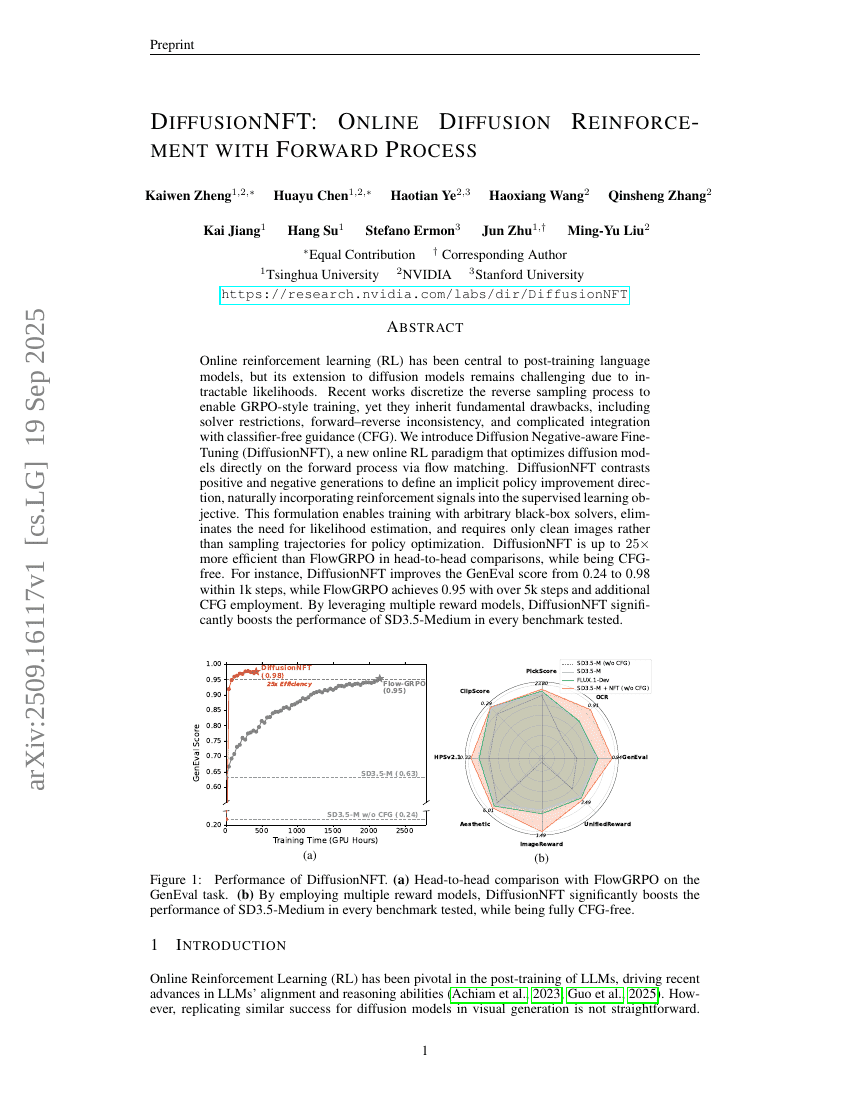
DiffusionNFT: Online Diffusion Reinforcement with Forward Process

TempSamp-R1: Effective Temporal Sampling with Reinforcement Fine-Tuning for Video LLMs

OnePiece: Bringing Context Engineering and Reasoning to Industrial Cascade Ranking System

OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models
LIMI: Less is More for Agency

A Modular Fusion Neural Network Approach to Efficiently Predict Multi-Metal Binding Sites in Protein Sequences

IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech

Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference

A Multi-Scale Graph Neural Process with Cross-Drug Co-Attention for Drug-Drug Interactions Prediction

GenCAD-3D: CAD Program Generation using Multimodal Latent Space Alignment and Synthetic Dataset Balancing

BTL-UI: Blink-Think-Link Reasoning Model for GUI Agent

Lynx: Towards High-Fidelity Personalized Video Generation

SPATIALGEN: Layout-guided 3D Indoor Scene Generation

BaseReward: A Strong Baseline for Multimodal Reward Model

Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification
EmbeddingGemma: Powerful and Lightweight Text Representations
Advancing Speech Understanding in Speech-Aware Language Models with GRPO
How Far are VLMs from Visual Spatial Intelligence? A Benchmark-Driven Perspective
SIM-CoT: Supervised Implicit Chain-of-Thought
SWE-QA: Can Language Models Answer Repository-level Code Questions?
Video models are zero-shot learners and reasoners
An N-Plus-1 GPT Agency for Critical Solution of Mechanical Engineering Analysis Problems
Memory-QA: Answering Recall Questions Based on Multimodal Memories
MAPO: Mixed Advantage Policy Optimization
Hyper-Bagel: A Unified Acceleration Framework for Multimodal Understanding and Generation
Reinforcement Learning on Pre-Training Data
Do You Need Proprioceptive States in Visuomotor Policies?
Baseer: A Vision-Language Model for Arabic Document-to-Markdown OCR
GenExam: A Multidisciplinary Text-to-Image Exam
Nav-R1: Reasoning and Navigation in Embodied Scenes
MoEs Are Stronger than You Think: Hyper-Parallel Inference Scaling with RoE
ARE: Scaling Up Agent Environments and Evaluations
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
TempSamp-R1: Effective Temporal Sampling with Reinforcement Fine-Tuning for Video LLMs
OnePiece: Bringing Context Engineering and Reasoning to Industrial Cascade Ranking System
OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models
LIMI: Less is More for Agency
A Modular Fusion Neural Network Approach to Efficiently Predict Multi-Metal Binding Sites in Protein Sequences
IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech
Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference
A Multi-Scale Graph Neural Process with Cross-Drug Co-Attention for Drug-Drug Interactions Prediction
GenCAD-3D: CAD Program Generation using Multimodal Latent Space Alignment and Synthetic Dataset Balancing
BTL-UI: Blink-Think-Link Reasoning Model for GUI Agent
Lynx: Towards High-Fidelity Personalized Video Generation
SPATIALGEN: Layout-guided 3D Indoor Scene Generation
BaseReward: A Strong Baseline for Multimodal Reward Model
Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification