HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer

Oyster-I: Beyond Refusal - Constructive Safety Alignment for Responsible Language Models






















MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Oyster-I: Beyond Refusal - Constructive Safety Alignment for Responsible Language Models
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
Synthetic bootstrapped pretraining
Skilful global seasonal predictions from a machine learning weather model trained on reanalysis data
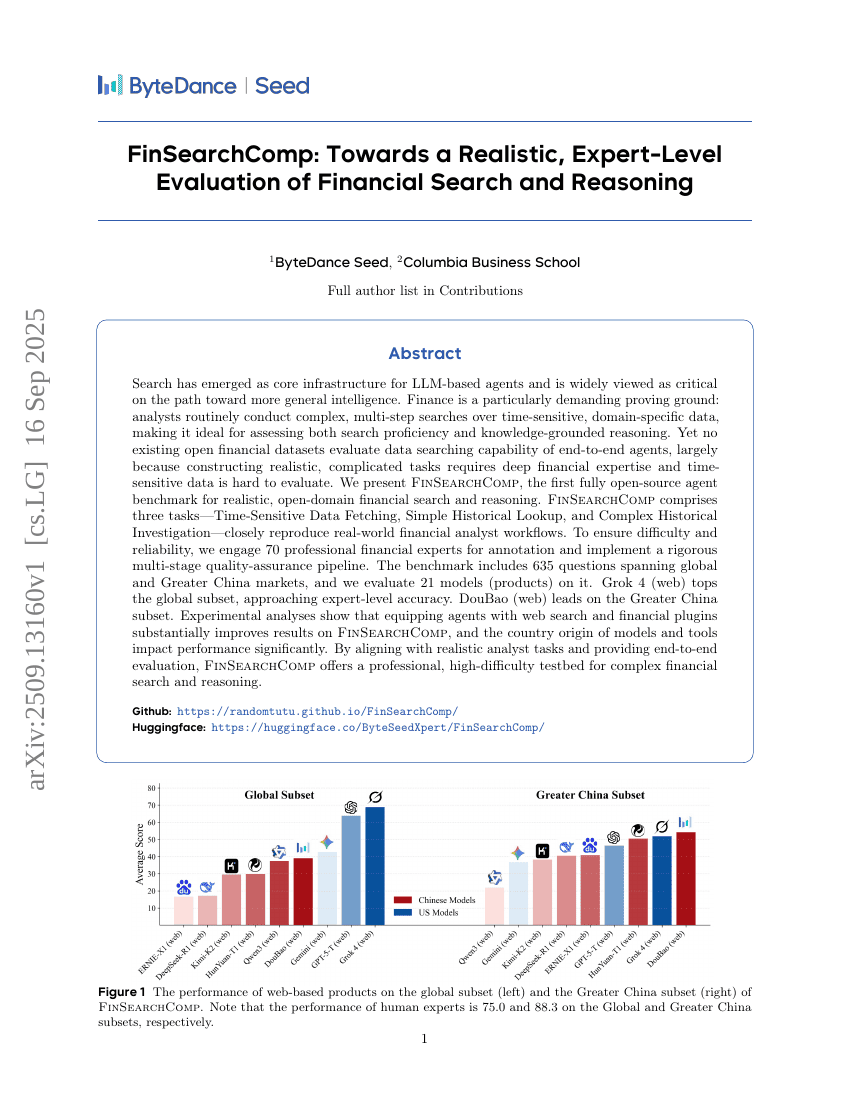
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
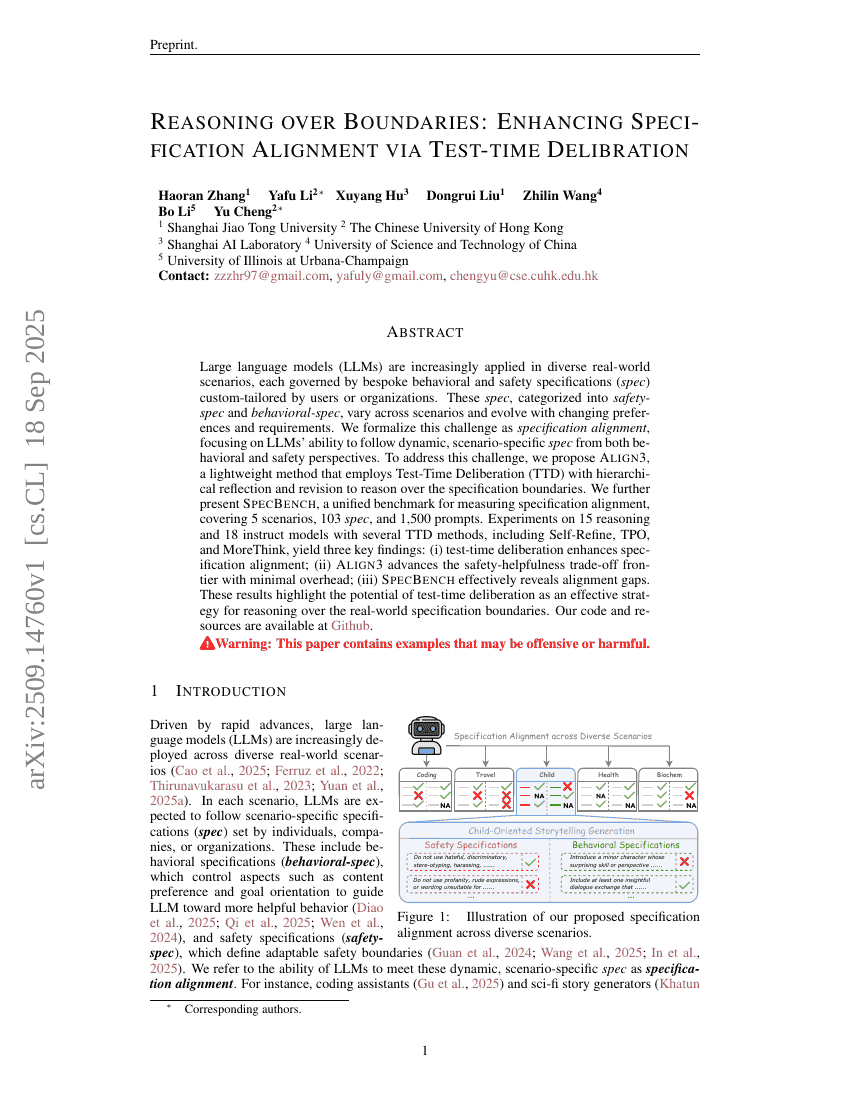
Reasoning over Boundaries: Enhancing Specification Alignment via Test-time Delibration
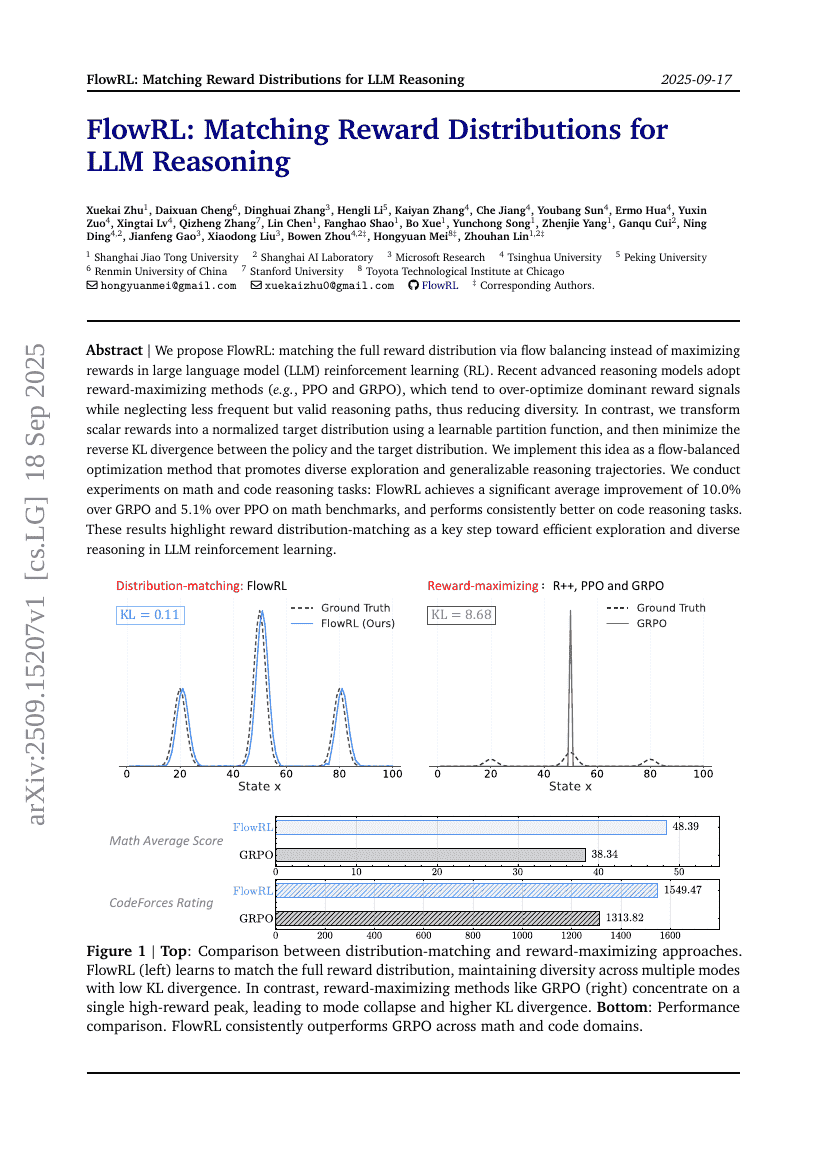
FlowRL: Matching Reward Distributions for LLM Reasoning
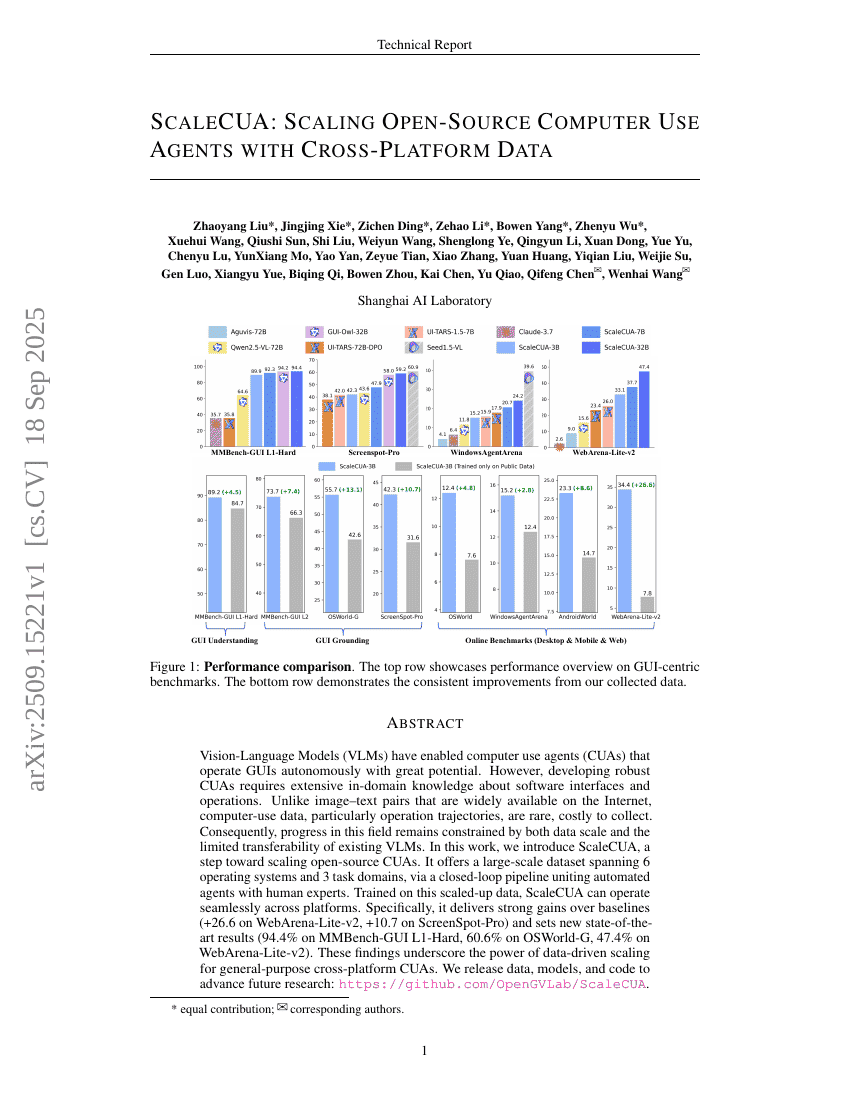
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Are Large Pre-trained Vision Language Models Effective Construction Safety Inspectors?
HTSC-2025: A Benchmark Dataset of Ambient-Pressure High-Temperature Superconductors for AI-Driven Critical Temperature Prediction
Discovery of Unstable Singularities
VCBench: Benchmarking LLMs in Venture Capital
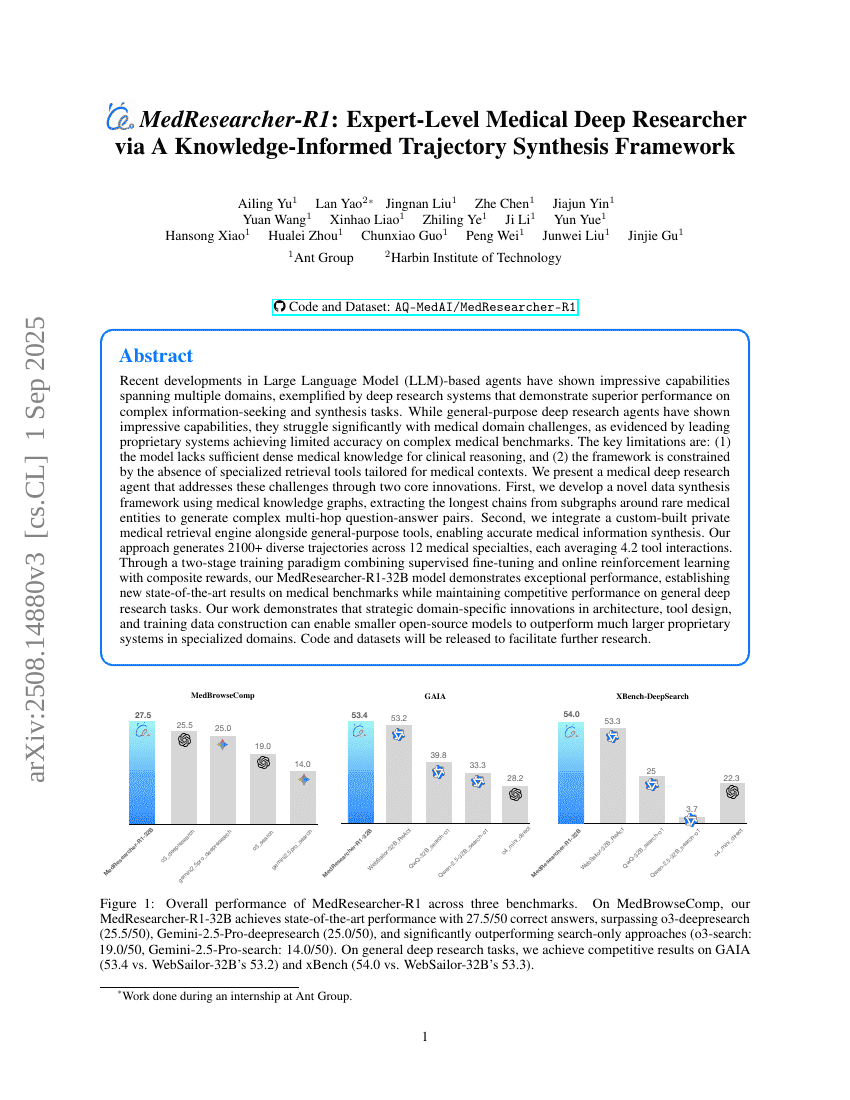
MedReseacher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework
Scrub It Out! Erasing Sensitive Memorization in Code Language Models via Machine Unlearning
PANORAMA: The Rise of Omnidirectional Vision in the Embodied AI Era
Hala Technical Report: Building Arabic-Centric Instruction & Translation Models at Scale
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
Teaching LLMs to Plan: Logical Chain-of-Thought Instruction Tuning for Symbolic Planning
OpenHA: A Series of Open-Source Hierarchical Agentic Models in Minecraft
BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
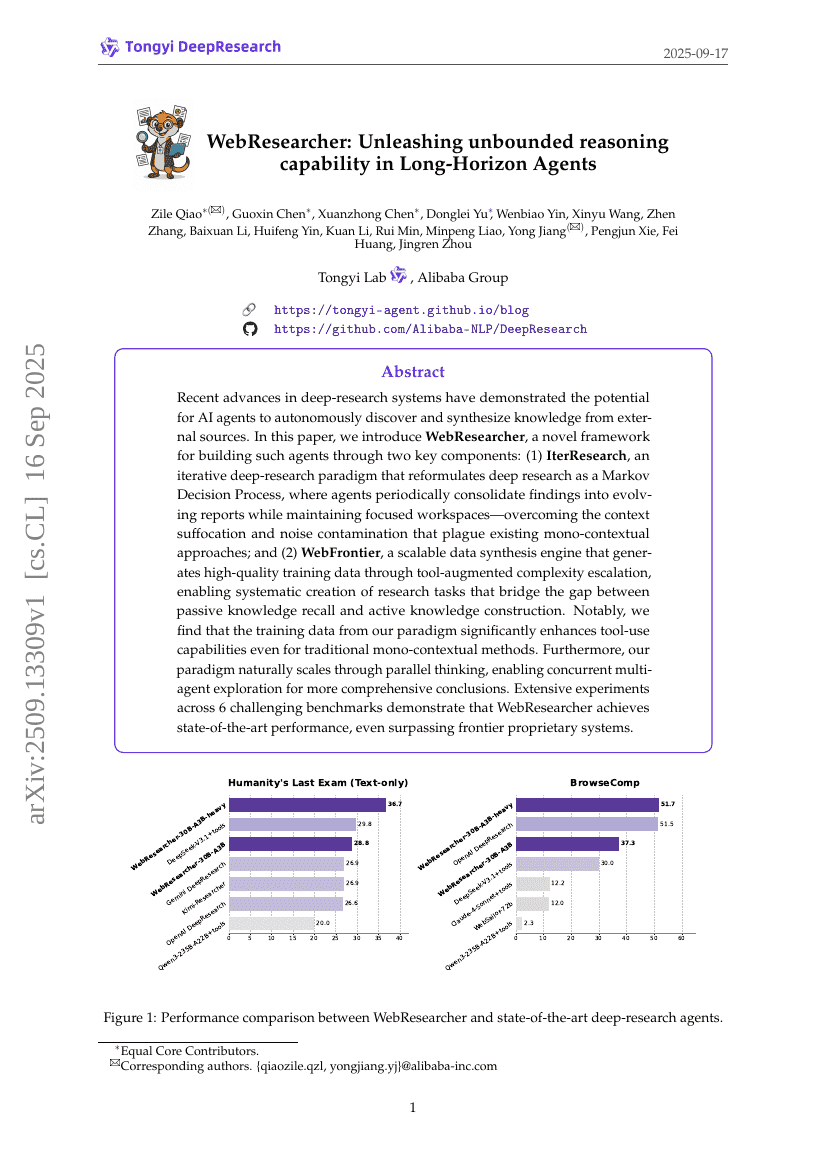
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Towards General Agentic Intelligence via Environment Scaling
WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
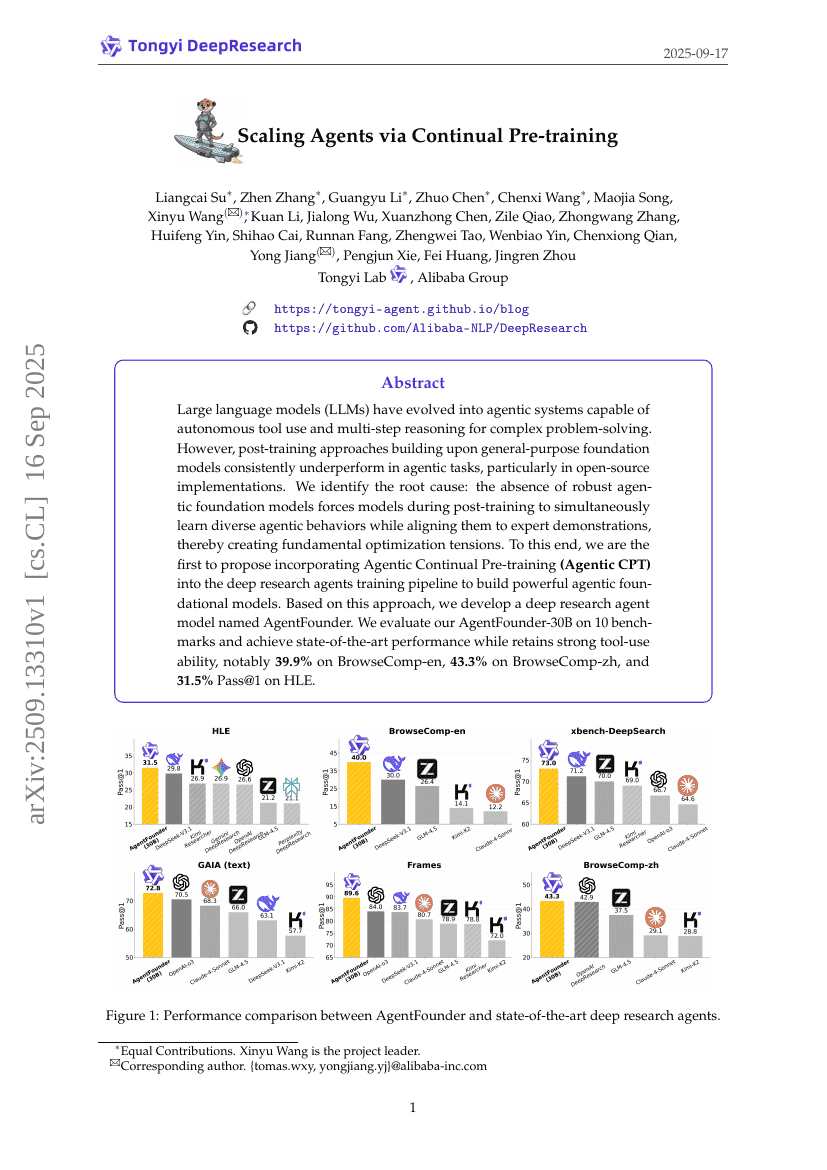
Scaling Agents via Continual Pre-training
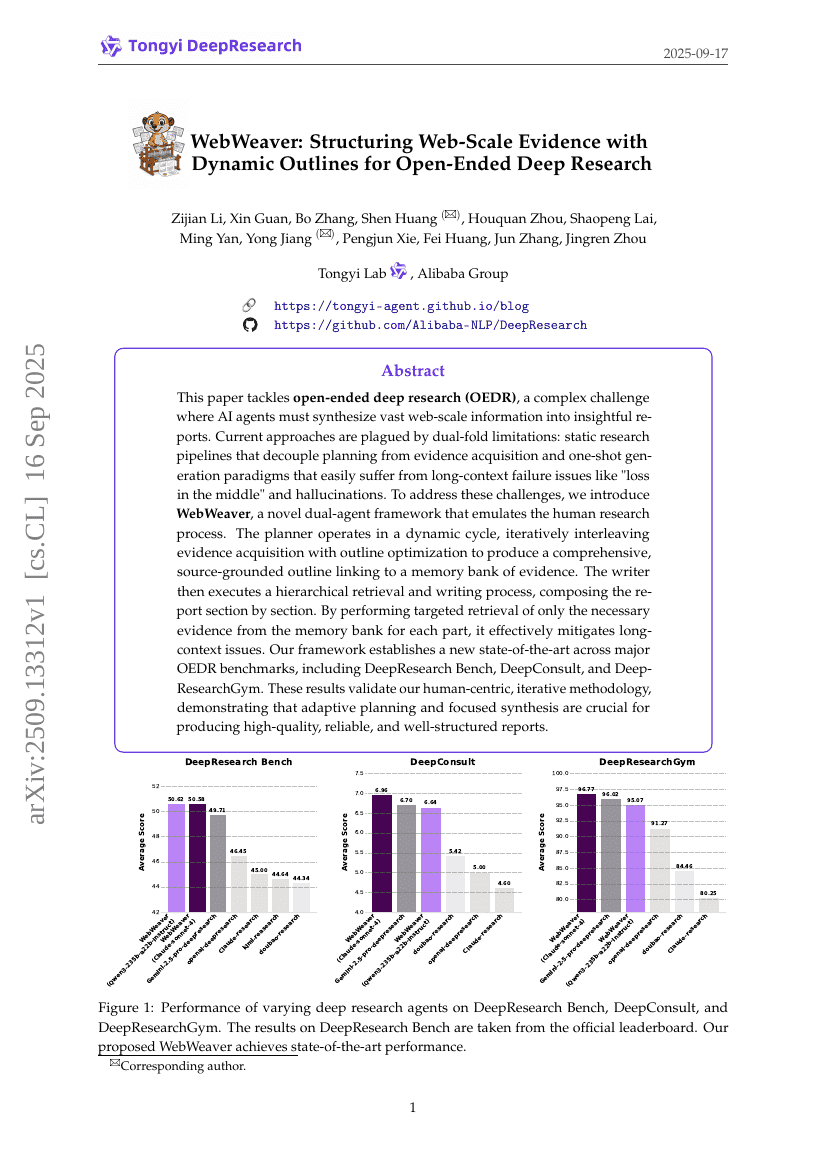
WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection
REFRAG: Rethinking RAG based Decoding
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
Synthetic bootstrapped pretraining
Skilful global seasonal predictions from a machine learning weather model trained on reanalysis data
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Reasoning over Boundaries: Enhancing Specification Alignment via Test-time Delibration
FlowRL: Matching Reward Distributions for LLM Reasoning
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Are Large Pre-trained Vision Language Models Effective Construction Safety Inspectors?
HTSC-2025: A Benchmark Dataset of Ambient-Pressure High-Temperature Superconductors for AI-Driven Critical Temperature Prediction
Discovery of Unstable Singularities
VCBench: Benchmarking LLMs in Venture Capital
MedReseacher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework
Scrub It Out! Erasing Sensitive Memorization in Code Language Models via Machine Unlearning
PANORAMA: The Rise of Omnidirectional Vision in the Embodied AI Era
Hala Technical Report: Building Arabic-Centric Instruction & Translation Models at Scale
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
Teaching LLMs to Plan: Logical Chain-of-Thought Instruction Tuning for Symbolic Planning
OpenHA: A Series of Open-Source Hierarchical Agentic Models in Minecraft
BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Towards General Agentic Intelligence via Environment Scaling
WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
Scaling Agents via Continual Pre-training
WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection
REFRAG: Rethinking RAG based Decoding