HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Align-Then-stEer: Adapting the Vision-Language Action Models through Unified Latent Guidance

SubLIME: Subset Selection via Rank Correlation Prediction for Data-Efficient LLM Evaluation


























Align-Then-stEer: Adapting the Vision-Language Action Models through Unified Latent Guidance
SubLIME: Subset Selection via Rank Correlation Prediction for Data-Efficient LLM Evaluation
Mixture of Contexts for Long Video Generation
MusicSwarm: Biologically Inspired Intelligence for Music Composition
LEGO: Spatial Accelerator Generation and Optimization for Tensor Applications
LazyDrag: Enabling Stable Drag-Based Editing on Multi-Modal Diffusion Transformers via Explicit Correspondence
SearchInstruct: Enhancing Domain Adaptation via Retrieval-Based Instruction Dataset Creation
Interpretable Physics Reasoning and Performance Taxonomy in Vision-Language Models
InternScenes: A Large-scale Simulatable Indoor Scene Dataset with Realistic Layouts
UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling
LAVa: Layer-wise KV Cache Eviction with Dynamic Budget Allocation
World Modeling with Probabilistic Structure Integration
VStyle: A Benchmark for Voice Style Adaptation with Spoken Instructions
HANRAG: Heuristic Accurate Noise-resistant Retrieval-Augmented Generation for Multi-hop Question Answering
InfGen: A Resolution-Agnostic Paradigm for Scalable Image Synthesis
X-Part: high fidelity and structure coherent shape decomposition
The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs
IntrEx: A Dataset for Modeling Engagement in Educational Conversations
Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
SceneSplat: Gaussian Splatting-based Scene Understanding with Vision-Language Pretraining
Virtual Agent Economies
Towards Understanding Visual Grounding in Visual Language Models
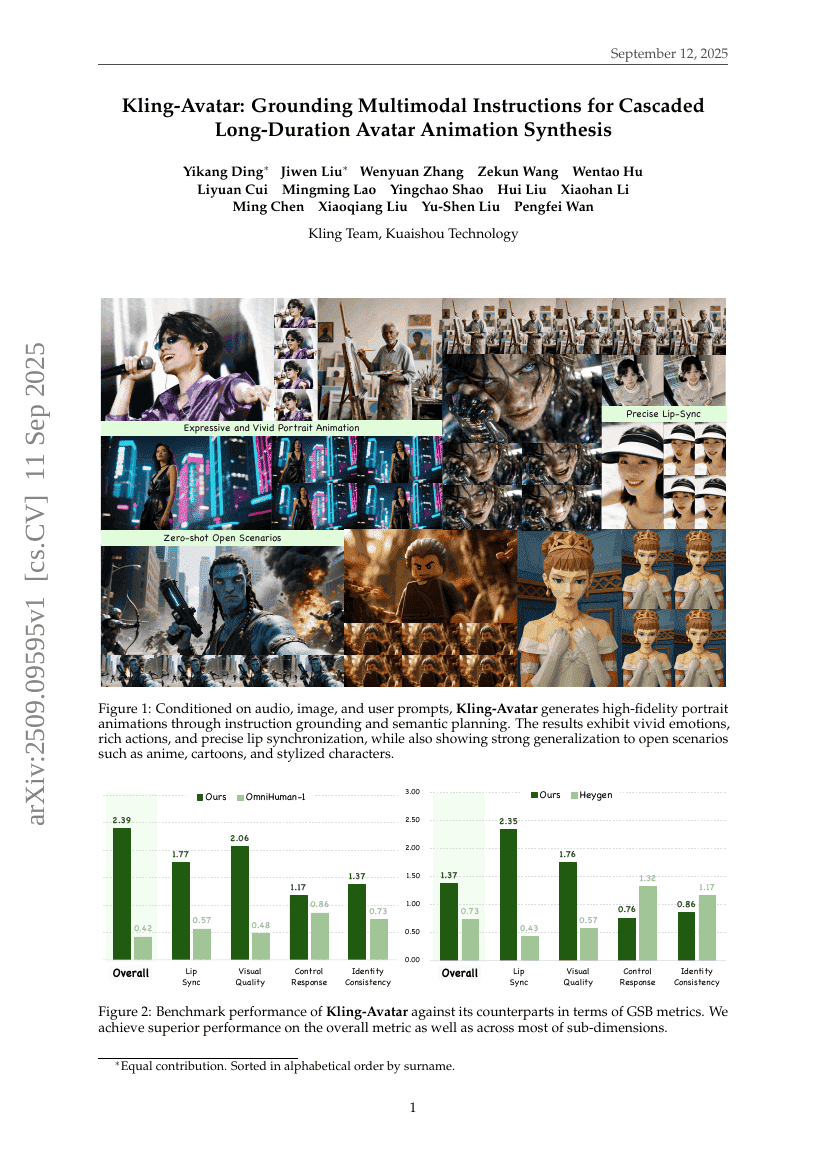
Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
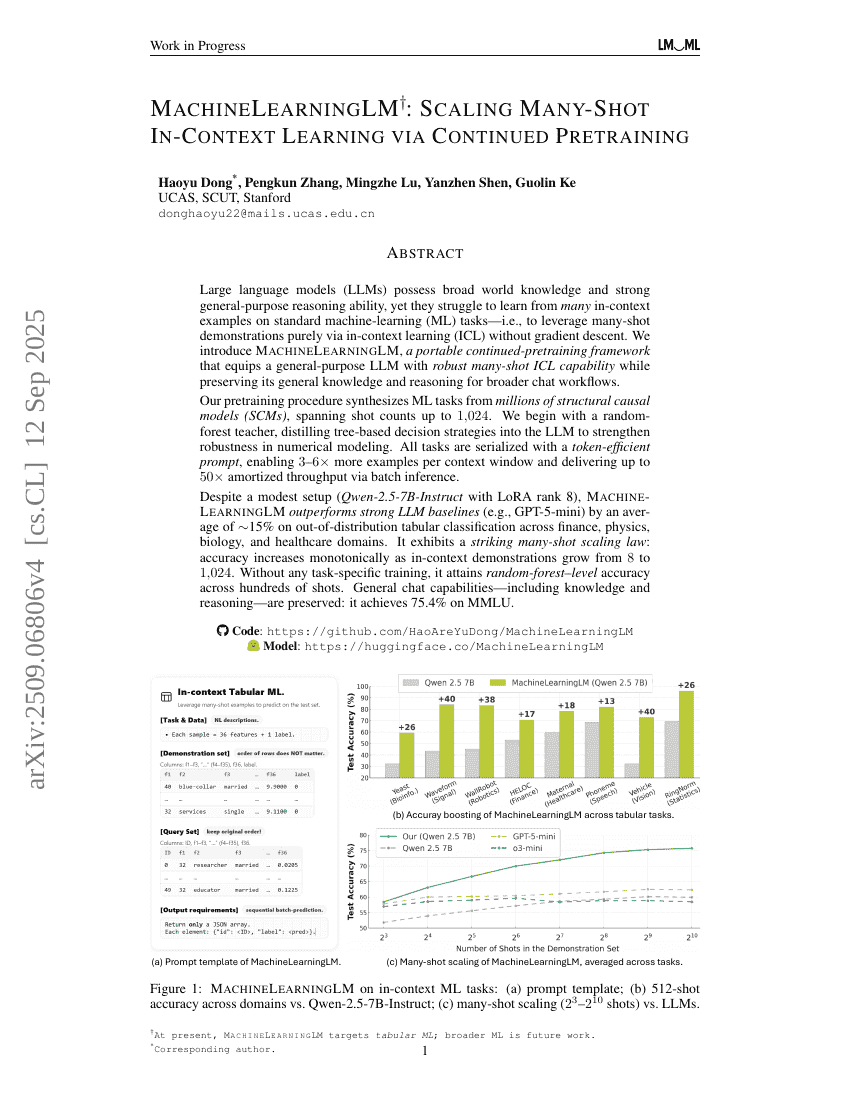
MachineLearningLM: Continued Pretraining Language Models on Millions of Synthetic Tabular Prediction Tasks Scales In-Context ML
EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
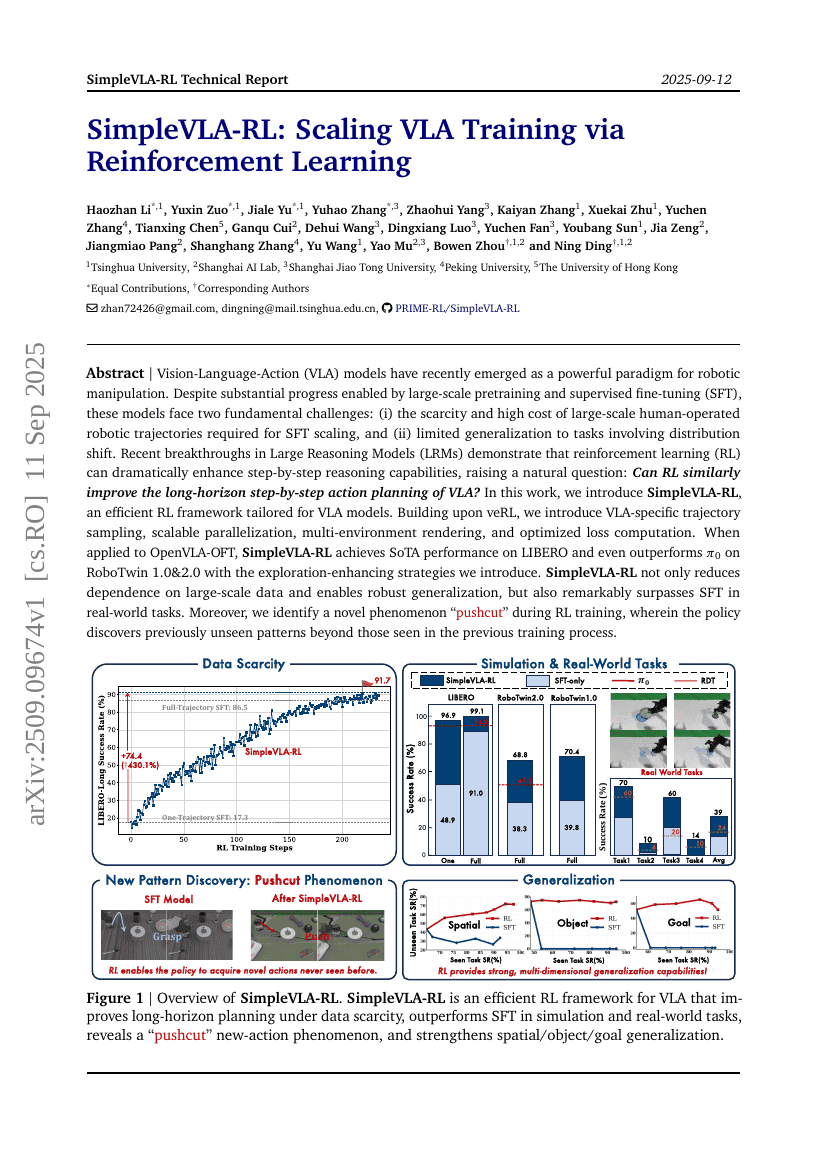
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
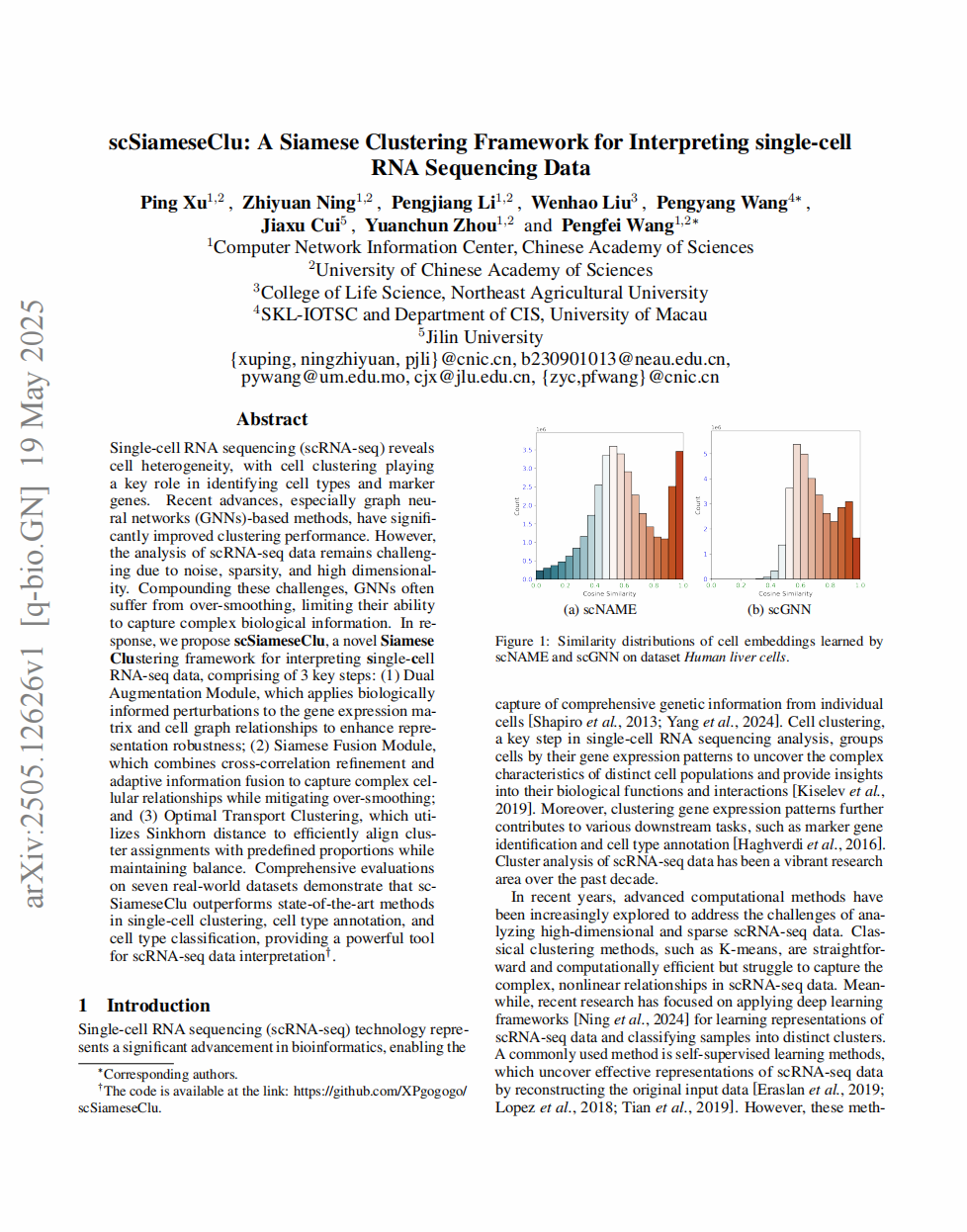
scSiameseClu: A Siamese Clustering Framework for Interpreting single-cell RNA Sequencing Data
ST-Raptor: LLM-Powered Semi-Structured Table Question Answering
OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models
Understanding Economic Tradeoffs Between Human and AI Agents in Bargaining Games
Mixture of Contexts for Long Video Generation
MusicSwarm: Biologically Inspired Intelligence for Music Composition
LEGO: Spatial Accelerator Generation and Optimization for Tensor Applications
LazyDrag: Enabling Stable Drag-Based Editing on Multi-Modal Diffusion Transformers via Explicit Correspondence
SearchInstruct: Enhancing Domain Adaptation via Retrieval-Based Instruction Dataset Creation
Interpretable Physics Reasoning and Performance Taxonomy in Vision-Language Models
InternScenes: A Large-scale Simulatable Indoor Scene Dataset with Realistic Layouts
UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling
LAVa: Layer-wise KV Cache Eviction with Dynamic Budget Allocation
World Modeling with Probabilistic Structure Integration
VStyle: A Benchmark for Voice Style Adaptation with Spoken Instructions
HANRAG: Heuristic Accurate Noise-resistant Retrieval-Augmented Generation for Multi-hop Question Answering
InfGen: A Resolution-Agnostic Paradigm for Scalable Image Synthesis
X-Part: high fidelity and structure coherent shape decomposition
The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs
IntrEx: A Dataset for Modeling Engagement in Educational Conversations
Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
SceneSplat: Gaussian Splatting-based Scene Understanding with Vision-Language Pretraining
Virtual Agent Economies
Towards Understanding Visual Grounding in Visual Language Models
Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
MachineLearningLM: Continued Pretraining Language Models on Millions of Synthetic Tabular Prediction Tasks Scales In-Context ML
EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
scSiameseClu: A Siamese Clustering Framework for Interpreting single-cell RNA Sequencing Data
ST-Raptor: LLM-Powered Semi-Structured Table Question Answering
OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models
Understanding Economic Tradeoffs Between Human and AI Agents in Bargaining Games